# 动态规划
## 期望与概率DP
首先想一下能不能从高斯消元入手。比如说:小明在一个 $[1,n]$ 的序列上随机游走,每次会随机走到距离 $\le1$ 的一个位置,求走到 $n$ 的期望步数。
我们可以写出他的转移方程:
$ $。
这时候,我们把它写成矩阵,玩高斯消元,获得一个 $O(n^3)$ 的算法。
但是这类随机游走的核心就在于他的矩阵非常稀疏。比如这道题,我们大致只有 $3\times n$ 个非零值。
###### 这里有你没写完的东西,杂鱼...
# 图论
## 最短路
### floyd
floyd 是一种可以求全源最短路的算法,其时间复杂度为 $O(n^3)$。其思路比较接近动态规划。
具体地说,我们顺序枚举一个中转点 $k$,然后去更新每一对的 $(i,j)$ 的最短路为 $dis_{i,j}=\min(dis_{i,j},dis_{i,k}+dis_{k,j})$。这样子更新完之后,$dis_{i,j}$ 实际上变成了经过 ${i,j}\cup[1,k]$ 的点时的 $(i,j)$ 之间的最短路。
一定要注意不要把 $k$ 放到 $i,j$ 里面枚举,因为这样子不满足 $dis_{i,j}$ 是经过 ${i,j}\cup[1,k]$ 的点时的 $(i,j)$ 之间的最短路。不过有研究表明把这样的循环执行三次也会有正确性?
代码如下:
```cpp
for (int k = 1; k <= n; ++k)
for (int i = 1; i <= n; ++i)
for (int j = 1; j <= n; ++j)
if (i != j && i != k && j != k) //这一行实际上可以不要
tmin(dis[i][j], dis[i][k] + dis[k][j]);
```
### spfa
spfa 的思路是逐步松弛,缩小点的最短路长度。
具体的来说,我们先将每个点的最短路长度设置为极大值,然后将起始点的最短路长度设为 $0$,将其放入队列中。
然后我们不停的取出队首,遍历其所有能到的点,如果有的点的最短路长度比从队首过来的更长,那就更新那个点的最短路大小。如果那个点不在队列中那就加入队列。
这个算法可以判断负环。显然如果一个点被更新了超过 $n$ 次,那就一定有负环。时间复杂度是 $O(kn)$ 的,随机数据下 $k=2$,但是实际上可以轻松卡到其上界限 $O(nm)$。代码如下:
```cpp
memset(dis, 0x3f, sizeof dis);
dis[s] = 0; q.emplace(s);
while (q.size()) {
int tp = q.front(); q.pop(); viq[tp] = 0;
for (const node& sp : son[tp])
if (dis[sp.p] > dis[tp] + sp.v)
if (dis[sp.p] = dis[tp] + sp.v, !viq[sp.p])
if (q.emplace(sp.p), ++tc[sp.p] > n)
return -1;
}
return dis[t];
```
### dijkstra
如果一幅图没有负权边,那么我们从小的向大的扩展一定不会错。因此,我们可以使用优先队列来维护最短路最短的没有扩展的点,并类似于 spfa 一样松弛其他的点。只不过因为没有负边权,所以第一次访问到就是最优解。代码如下:
```cpp
memset(dis, 0x3f, sizeof dis);
q.emplace(s, dis[s] = 0);
while (q.size()) {
node tp = q.top(); q.pop(); if (dis[tp.p] < tp.v) continue;
for (const node& sp : son[tp.p])
if (dis[sp.p] > dis[tp.p] + sp.v)
q.emplace(sp.p, dis[sp.p] = dis[tp.p] + sp.v);
}
return dis[t];
```
### johnson
johnson 是另一种可以处理负边权的全源最短路算法。他的思路是 通过将每一个点“抬高一点”,将边权转化为正权,然后处理。
我们引入一个物理上常见的概念,叫做“势能”。我们新建一个超级源点向每一个点连一条边,权值为 $0$,随后用 spfa 跑出到每一个点的最短距离 $h_p$,视为每一个点的“势能”。随后我们将 $(i,j)$ 的边权重新标注为 $w_{i,j}+h_i-h_j$。由最短路的三角形不等式可得这个边权是恒正的。
最后在求 $p\to i$ 的最短路时,$d_i=d^\prime_i+h_t-h_s$。其中 $d^\prime_i$ 是 diskstra 跑出来的虚拟距离。
为什么这样是正确的呢?我们注意到,在求 $i\to j$ 的最短路的过程中,势能的变化量永远是 $h_j-h_i$,和物理意义上的势能很像:势能绝对大小和选定的参考点有关,但相对大小与之无关,两点之间的势能差只与两端点有关,和中间怎么走的无关。
因此我们通过保证在任意两点之间的每一条路径的增加量相同的方式,保证了我们跑出来的最短路转化后仍然是最短路。
## 差分约束
差分约束可以用来求解形如 $\forall i\in m,x_{a_i}-x_{b_i}\ge/\le y_i$ 的不等式方程组。
具体的来说我们可以先通过调换顺序将不等号的方向同一,比如全部统一成 $\ge$,随后我们思考在最长路中的三角形不等式,发现 $d_i-d_j\ge E_{j\to i}$。形式一样。
于是 $x_i-x_j\ge d$ 可以转化为 $j$ 到 $i$ 有一条长度为 $d$ 边,然后随便找一个源点作起始点跑一下最长路就行了。
显然如果出现了正环,那么就无解,否则每个点的 $d$ 就是一组合法的解。
## 最小生成树
### prim
prim 的思路是加点。每一次我们选出和当前已选择的点集最近的点,并将它加入已选择的点集当中。
具体地说,最开始的时候,我们随意指定一个节点作为已选择的点集中的初始元素,并计算出每一个节点和他的距离。随后我们扩展 $n-1$ 轮。每一轮我们找出距离最近的,加上他的距离,并将它纳入已选择的点集中。随后再用这个点去重新计算别的点的最短距离。这样扩展完之后 $n$ 个点就都在已选择的点集中了。
时间复杂度 $O(n^2)$,动用人类智慧的话就不清楚能做到多少了。
### kruskal
kruskal 的思路是加边。每一次我们选出边权最小的边,并检查两个端点,如果两个端点不在同一个集合中,就把二者合并,并在贡献中加上这条边。否则不做处理。显然这个贪心策略不会出任何问题。
## 最近公共祖先
最常用的有 $3$ 种解法:倍增,tarjan,dfs 序。
倍增法就是预处理出每一个结点的 $2^i$ 级祖先。先将两个节点的深度调整一样,然后不停往上倍减着跳,最终二者相同的位置就是答案。参考代码如下:
```cpp
inline int lca(int l, int r) {
if (dep[l] < dep[r]) swap(l, r);
for (int i = 19; i >= 0; i--)
(dep[fa[l][i]] >= dep[r]) && (l = fa[l][i]);
if (l == r) return l;
for (int i = 19; i >= 0; i--)
(fa[l][i] != fa[r][i]) && (l = fa[l][i], r = fa[r][i]);
return fa[l][0];
}
```
tarjan 是一种可以做到严格线性的离线算法。通常情况下复杂度为 $O(m\alpha(m+n,n)+n)$。
算法流程是这样的:我们先将询问同时记录在那**两个**点上,然后我们从根节点开始遍历。
每一次到一个节点 $u$ 时,我们先去遍历他的所有子节点 $v$ 并将 $v$ 节点的并查集合并到 $u$ 上。然后将 $u$ 标记为遍历过。
最后检查 $u$ 节点的所有查询 $v$。如果 $v$ 已经遍历过了那么答案就是 $v$ 所在的并查集,否则不做任何操作。参考代码如下:
```cpp
inline void dfs(int p, int f) {
for (int sp : son[p])
if (sp != f) dfs(sp, p), merge(sp, p);
vis[p] = 1;
for (const node& q : que[p])
if (vis[q.p]) ans[q.id] = find(q.p);
}
```
接下来是 dfs 序。dfs 满足一些神奇的性质,比如说 $[dfs_u+1,dfs_v]$ 中深度最小的节点的深度恰为 $lca$ 的深度 $-1$,如果 $u$ 的深度比 $v$ 小。
其实这个我不是很想证明,因为分讨一下 $u$ 是不是 $lca$ 就 证明完毕了。这样子你就可以用 ST 表做到 $O(1)$ 查询了。
## tarjan
tarjan 的思路并不复杂,我们先按照 $dfs$ 序进行遍历,然后处理每一个边。具体的来说,我们给每个节点两个标记:$dfn,low$。$dfn$ 记录他的 $dfs$ 序中的编号,$low$ 则是在一定的规则下通过至多一条不在搜索树上的边能到达的 dfs 序的最小值。
### 强连通分量
强连通分量是针对于有向图说的。具体的,如果同时存在 $a\to b,b\to a$ 的路径,那么 $a,b$ 强连通,而一个强连通分量 $S$ 就是一个满足 $\forall i,j\in S$,$i,j$ 强连通的极大子图。
那么我们在 tarjan 的时候具体怎么办呢?到每一个点 $p$ 时,我们会将 $dfn_n$ 和 $low_p$ 均设置为 $p$。首先,如果一个点 $p$ 发现了一个没有遍历过的点 $sp$,那么我们就可以先继续遍历 $sp$,随后将 $low_p$ 取为 $\min(low_p,low_{sp})$。这一种显然没有问题。
如果发现了一个遍历过的点那就要分一下情况了:
如果这个点已经被标记在某一个强连通分量中了,那说明这个点无法到达自己,肯定和自己不是同一个强连通分量内的。
但是如果没有被标记过呢?那么有两种情况:一种是访问到自己的祖先了,一种是访问到了自己的子节点。总之我们发现我们的这个边不是树边,而且因为那个节点截至目前仍然没有被纳入强连通分量,所以一定能到达自己,可以更新。
说白了,在强连通分量下,这个规则就是双方互相可达。但是似乎上面的最后一句的“一定能到达自己”不是很说的走呢?
并不是的。当我们在遍历完了 $p$ 的所有子节点之后发现 $dfn_p=low_p$,那么不难想到这个点及其子树中的所有点其实都无法逃出 $p$ 的魔爪,否则就会更新到 $low$ 中。因此没被更新就是可以访问到自己。
还差最后一个问题:我怎么知道该标记哪些点是自己这个连通分量内的?当 $dfn_p=low_p$ 的时候,我们会去标记在 $p$ 的子树之下而且可达到 $p$ 的节点,
### 割边-边双连通分量
### 割点-点双连通分量
## 二分图
二分图是这一个图 $(V,E)$,可以分出两个点集 $V_1,V_2$,满足 $V_1\cap V_2=\emptyset,V_1\cup V_2=V$ 且 $\forall(l,r)\in E,l\in V_1,r\in V_2$ 或者 $l\in V_2,r\in V_1$。
### 判定
有多种办法可以判定,常用的有染色法,扩展域并查集等。
染色法就是尝试给每个节点分配集合。显然如果 $l\in V_1$,那么 $\forall(l,r)\in E,r\in V_2$,换个集合仍然成立。
所以就随便钦定一个点在某个集合里,能分出来就有,分不出来就没有。
扩展域并查集类似,如果二者有就将 $l_1,r_2$ 和 $l_2,r_1$ 分别绑定一下。
### 最大匹配
就是给你一张二分图,问你能从里面选出多少边,满足这些边的左右部点都不重。
这个常用网络流中的 Dinic 或者匈牙利算法解决。
匈牙利算法就是不停的强制让某个点匹配上,如果某个右部点已经匹配上了就把他抢过来,直到成功匹配到没人的或者确实配不上。
网络流的话每一个左部点从源点牵一个流量一的,右部点连一个流量一的到汇点,中间的流量一就行。
## 霍尔定理
令 $L,R$ 分别表示左右点集,那么定义 $p\in L,D(p)=\{u|u\in R,(p,u)\in E\}$。也就是说 $D(p)$ 是左部点 $p$ 所直连的右部点的集合。
再定义 $S\subseteq L,D(S)=\cup_{p\in S}D(p)$。也就是说 $D(S)$ 是左部点子集 $S$ 中存在点直连的右部点集合。
再约定 $|S|$ 表示集合 $S$ 的大小。
那么,$\forall S\in L,|D(S)|\ge|S|\iff$ 存在 $L$ 向 $R$ 的完全匹配。
显然和匈牙利算法的证明等价。必要性显然,充分性反证:
设G中不存在完全匹配,取 $G$ 的一个最大匹配 $M$,则 $L$ 中至少有一个点不在 $M$ 上,且该点必至少与一条不在 $M$ 中的边相连。
该边的另一个顶点若也为 $M-$ 非饱和点,则与 $M$ 为最大匹配矛盾,若另一个顶点为 $M-$ 饱和点,则考察在 $M$ 中与该顶点相邻的点,利用饱和点去考察在 $M$ 中相邻的饱和点(交错地考察,即交错地通过 $M$ 中的边和非M中的边),直至考察完毕。
由相异性条件知,最后必考察至非饱和点,此时出现一条增广路,又与假设矛盾($M$不是最大匹配),故充分性成立。[refer](https://blog.csdn.net/feynman1999/article/details/76037603)。
扩展定理:
1. $\forall S\in L,|D(S)|\ge|S|-A\iff L$ 中最大匹配的情况下最多有 $A$ 个点失配。
2. $\forall S\in L,|D(S)|\ge k\times|S|\iff L$ 中每个点在匹配 $k$ 个右部点的情况下仍然存在满最大匹配。
3. 如果左部点 $i$ 最多能匹配 $r_i$ 个右部点,那么 $\forall S\in L,|D(S)|\ge\sum_{i\in S}r_i\iff$ 存在满最大匹配。
证明的话,第一个可以让每个左部点同时连上 $A$ 个赛博右部点,转化为原定理,得证。
第二个和第三个可以让第 $i$ 个人裂成 $r_i(=k?)$ 份去分别和几个右部点连边,转化为原定理,得证。
但是解题是有技巧的,限制数是 $2^n$ 级别的,我们需要去抓最紧的限制。也就是将有效限制个数缩到最小。从而求解问题。
## 网络流
### FF-EK-Dinic
#### FF(Ford–Fulkerson) 增广思路
FF,即 Ford–Fulkerson 增广。该方法运用贪心的思想,通过寻找增广路来更新并求解最大流。
其中有一个概念叫做增广路,说白了就是所有边剩余流量大于零的路径。使用这条边显然可以使答案增加,但是直接贪心是错的。
接下来,我们进行反悔贪心。当我们给 $x\to y$ 这条边增加 $v$ 的流量时,就将 $x\to y$ 的剩余流量减去 $v$,而将 $y\to x$ 的剩余流量增加 $v$。
正如 OI-wiki 的一张图:
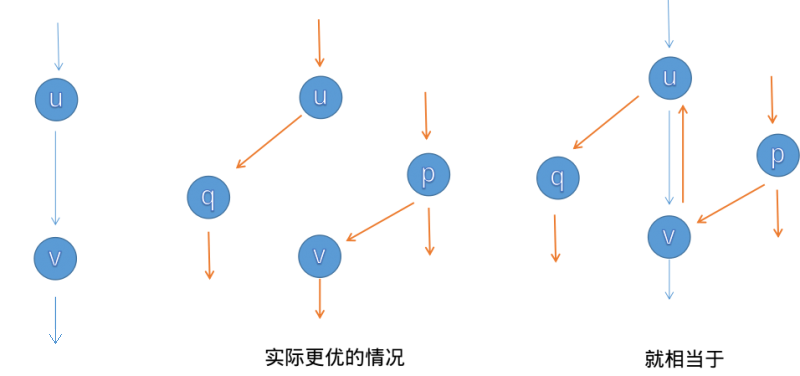
可以严格证明,这里略去。~~反正不考证明~~。其本质上就是 [最大流-最小割](https://oi-wiki.org/graph/flow/max-flow/#%E6%9C%80%E5%A4%A7%E6%B5%81%E6%9C%80%E5%B0%8F%E5%89%B2%E5%AE%9A%E7%90%86) 定理。
#### EK 算法
使用 BFS时,FF 增广表现为 EK 算法。其本质上就是将找出任意一条变成了找出最短的一条,每次使用 BFS 找出最短的增广路并增广。时间复杂度为 $O(nm^2)$。时间复杂度劣,而且和 Dinic 难度大致相当,不附代码。
#### Dinic 算法
他的优化就在于他同时对多条增广路进行处理,具体的流程如下:
首先,对当前的图做一次 BFS,求出每个点的“深度”。
然后,进行 DFS。每次 DFS 时,记录当前节点和当前携带流量。随后,一直向深度大 $1$ 的子节点分配尽可能多的流量,直到没有子节点或者自己流量用完。贡献就是所有被分配到的子节点的贡献之和。
这里还常用一个“当前弧”优化,其实说白了,就是之前已经被分配满的子节点以后不可能再分配了,因此记录一个已枚举位置就行。参考代码如下:
```cpp
//就这你还想看?没更新呢!
```
### 费用流
对于没有负圈的普通费用流,常用 SSP(Successive Shortest Path) 进行求解,思路类似于 FF,每一次找一条或多条单位费用最大/小的路进行增广。
负圈是指单位费用为负的圈。
注意费用流的时间复杂度是 $O(nmf)$ 的,$f$ 是最大流。可以被卡到 $O(n^32^{\frac{n}{2}})$。
给出基于 Dinic 的参考代码如下:
```cpp
struct SSP {
struct node { int p, f, v; }tmp;
vector<node>e; vector<int>h[5005];
inline void ins(int l, int r, int f, int v) {
tmp.p = r; tmp.f = f; tmp.v = v;
h[l].emplace_back(e.size());
e.emplace_back(tmp);
tmp.p = l; tmp.f = 0; tmp.v = -v;
h[r].emplace_back(e.size());
e.emplace_back(tmp);
} //加边函数
int d[5005]; bitset<5005>vis;
inline bool spfa() {
vis.reset(); fill(d + 1, d + n + 1, 0x3f3f3f3f3f3f3f3f);
queue<int>q; q.emplace(s); d[s] = 0;
while (q.size()) {
int tp = q.front(); q.pop(); vis[tp] = 0;
for (int i : h[tp])
if (e[i].f && d[e[i].p] > d[tp] + e[i].v)
if (d[e[i].p] = d[tp] + e[i].v, !vis[e[i].p])
q.emplace(e[i].p), vis[e[i].p] = 1;
}
return d[t] != 0x3f3f3f3f3f3f3f3f;
} //分层,这里的“距离”从 $1$ 变成了边权,因为有负权,所以需要 spfa
int pr[5005];
inline int dfs(int p, int f) {
if (p == t || !f) return f;
int ret = 0, v; vis[p] = 1;
for (int& i = pr[p];i != h[p].size();++i) {
node& sp = e[h[p][i]];
if (!vis[sp.p] && sp.f && d[sp.p] == d[p] + sp.v) {
v = dfs(sp.p, min(f, sp.f));
if (!v) d[sp.p] = 0x3f3f3f3f3f3f3f3f;
sp.f -= v; e[h[p][i] ^ 1].f += v;
ret += v; f -= v; ans += v * sp.v; //要在这里统计费用,边权不一致。
if (!f) return ret;
}
}
vis[p] = 0; return ret;
}
inline int que() {
while (spfa()) {
fill(pr + 1, pr + n + 1, 0); //当前弧优化
for (int v;v = dfs(s, 0x3f3f3f3f3f3f3f3f);) mxf += v;
}
return mxf;
}
//que 返回最大流,ans 存最小费用
}ssp;
```
### 上下界流
正如其名,原先只有上界的网络流也有下界拉!一篇较好的[博客](https://blog.csdn.net/EQUINOX1/article/details/135953172)专讲基础上下界流。
#### 存在性判定
对于每一个点,我们令 $cin_i=\sum f(j,i),cout_i=\sum f(i,j),rd_i=cin_i-cout_i$,然后思考:
1. 对于 $rd_i=0$ 的点,其入度的下界与出度的下界相同,也就是说这些边我们可以将上界重写为 $fmax-fmin$,仍满足流量守恒。
2. 对于 $rd_i<0$ 的点,他若直接将上界重写为 $fmax-fmin$,则不满足流量守恒,出度过小。需要向超级汇点连一条容量上界为 $-rd_i$ 的边。
3. 对于 $rd_i>0$ 的点,他若直接将上界重写为 $fmax-fmin$,则不满足流量守恒,入度过小。需要从超级源点连一条容量上界为 $rd_i$ 的边。
此时,若从超级源点到超级汇点满流,则存在,反之不存在,由源汇点的流量与原图的流量守恒关系不难证得。
#### 有源状态下的判定
从 $t$ 向 $s$ 连一条容量无限的边,就完美地将有源强转成了无源,然后就能做了。
#### 最大/小流(有源)
我们还是先有源强转无源跑判定,判定完了之后记录 $s$ 到 $t$ 的最大流,删除 $t$ 到 $s$ 的边,然后分情况:
如果是最大流,就跑出 $s$ 到 $t$ 的最大流和开始的那个最大流相加得到结果。
如果是最小流,就跑出 $t$ 到 $s$ 的最大流和开始的那个最大流相减得到结果。
问什么正确呢?其实判定的本质就是强制流量守恒,也就是强制将上下界流改成普通流。
判定如果成功的话,那么所有的点都在同一个“势能面”上了,多余的就是在推流/反流。
比如针对两个的[缝合体]()红石科技,我们可以这样写:
```cpp
#include<bits/stdc++.h>
using namespace std;
#define int long long
...//定义变量
struct ULBNF {
...//定义变量与其他函数
inline bool dneflow(int sm) {
ans = 0;
while (bfs())
fill(cur, cur + n + 4, 0),
ans += dfs(s, 1e18);
return ans != sm;
}
inline int maxflow() {
while (bfs())
fill(cur, cur + n + 4, 0),
ans += dfs(s, 1e18);
return ans;
}
inline int minflow() {
while (bfs())
fill(cur, cur + n + 4, 0),
ans -= dfs(s, 1e18);
return ans;
}
}net; //upper-lower bound network flow
signed main() {
ios::sync_with_stdio(0);
cin >> n >> m >> ys >> yt; s = n + 1; t = n + 2;
for (int i = 0, a, b, c, d;i != m;++i)
cin >> a >> b >> c >> d,
net.ins(a, b, d - c, 0),
rd[a] -= c, rd[b] += c;
bool ext = 0;
for (int i = 1;i <= n;++i)
if (rd[i] > 0) sm += rd[i], net.ins(s, i, rd[i], 0), ext = 1;
else if (rd[i] < 0) net.ins(i, t, -rd[i], 0), ext = 1; // :)
net.ins(yt, ys, 1e18, 0);
if (net.dneflow(sm)) return puts("A clever xzy~~~"), 0;
ans = net.e.back().f;
net.dellast(yt, ys); t = ys, s = yt;
cout << (ext ? net.minflow() - 1 : -1) << ' ';
s = ys, t = yt;
cout << net.maxflow() + 1 << endl;
}
```
#### 最大/小费用可行流
基于我们前面所讲的判定的本质就是强制流量守恒,我们不管在建出来的辅助图上跑网络流还是费用流,反正只要限定是最大流,就能对应出原图的一个可行流。
所以说,我们建出辅助图并且提前计算砍去下界少算的费用,辅助图的最大/小费用最大流就是原图的最大/小费用可行流。比最大/小流(有源)还少一步。
核心代码如下:
```cpp
struct ULBNF {
...
int d[505]; bool vis[505];
inline bool spfa() {
fill(vis, vis + t + 4, 0);
memset(d, 0x0f, sizeof d);
vis[s] = 1; d[s] = 0;
queue<int>q; q.push(s);
while (q.size()) {
int tp = q.front();q.pop(); vis[tp] = 0;
for (int i = 0;i != h[tp].size();++i) {
node& sp = e[h[tp][i]];
if (sp.f && d[sp.p] > d[tp] + sp.v)
if (d[sp.p] = d[tp] + sp.v, !vis[sp.p])
q.push(sp.p), vis[sp.p] = 1;
}
}
return d[t] < 1e8;
}
int cur[505];
inline int dfs(int p, int a) {
if (p == t || a == 0) return a;
int ret = 0, f; vis[p] = 1;
for (int& i = cur[p]; i != h[p].size(); ++i) {
node& sp = e[h[p][i]];
if (!vis[sp.p] && d[sp.p] == d[p] + sp.v && sp.f) {
f = dfs(sp.p, min(a, sp.f));
if (!f) d[sp.p] = 0x0f0f0f0f;
sp.f -= f; e[h[p][i] ^ 1].f += f;
ret += f; a -= f; miv += sp.v * f;
if (!a) return ret;
}
}
vis[p] = 0; return ret;
}
inline int micflow() {
while (spfa()) {
fill(cur, cur + t + 4, 0);
for (int v;v = dfs(s, 12);) ans += v;
}
return miv;
}
}net;
```
当然还是别忘了要给原图中的 $t\to s$ 建一条没费用的无限流。
### 模拟费用流
思路类似于手动消元,说白了就是利用建出来的图的性质进行针对性的优化,从而加速计算。[例题1](https://vjudge.net/problem/QOJ-7185#author=luzchancc)。
在这道题中,建模其实非常的裸,但是点数过大,完全不能跑费用流,因此需要手动最短路。
那怎么做呢?我们注意到原图近似是一个二分图,也就是说任意一条路径可以视为 $s\to l\to r$,任意多条 $r\to l\to r$ 和 $r\to t$ 拼接而成的。第三段费用为 $0$,所以只用分别维护第一二段从每个 $r$ 出发的最优边。
给出一份仅保留核心的参考代码:
```cpp
inline void enable(int lp) {
if (lus[lp])
for (int i = 0;i != m;++i)
if (rls[lp][i]) sh[i].emplace(c[lp][i], lp);
//这里是在处理添加左点对 slr 路径的影响
for (int i = 0;i != m;++i)
for (int j = 0;j != m;++j)
if (i != j && rls[lp][j] && !rls[lp][i])
hh[i][j].emplace(c[lp][j] - c[lp][i], lp);
//这里是在处理添加左点对 rlr 路径的影响
}
inline void disable(int lp) {
if (lus[lp])
for (int i = 0;i != m;++i)
if (rls[lp][i]) sh[i].erase(sh[i].find(node(c[lp][i], lp)));
//这里是在处理删除左点对 slr 路径的影响
for (int i = 0;i != m;++i)
for (int j = 0;j != m;++j)
if (i != j && rls[lp][j] && !rls[lp][i])
hh[i][j].erase(hh[i][j].find(node(c[lp][j] - c[lp][i], lp)));
//这里是在处理删除左点对 rlr 路径的影响
}
inline void solvpas(int l, int r, vector<int>& p) {
if (v[l][r] == pv[l][r]) {
p.emplace_back(l); return;
}
solvpas(l, pp[l][r], p);
// p.emplace_back(pp[l][r]);
// 实际上查询子区间时总会找到这些“叶子”节点并加入队列中。
solvpas(pp[l][r], r, p);
}
inline void delt1(int p) { //传入的是右侧点的编号。暂未更改,可以倒推出左侧点编号
int lp = sh[p].begin()->r;
disable(lp); lus[lp] = 0;
rls[lp][p] ^= 1; enable(lp);
}
inline void delt2(int ap, int bp) { //同上
int cp = hh[ap][bp].begin()->r;
disable(cp); rls[cp][bp] ^= 1;
rls[cp][ap] ^= 1; enable(cp);
}
signed main() {
ios::sync_with_stdio(0); m = 3;
memset(rls, 1, sizeof rls); //初始全部可用
for (int i = 0;i != m;++i) cin >> a[i], n += a[i];
for (int i = 1;i <= n;++i)
for (int j = 0;j != m;++j) cin >> c[i][j];
for (int i = 1;i <= n;++i) lus[i] = 1, enable(i);
for (int tms = 1;tms <= n;++tms) {
//总计 n 次增广;m 是源点,m+1 是汇点
memset(v, 0xcf, sizeof v);
memset(pp, -1, sizeof pp);
for (int i = 0;i != m;++i)
for (int j = 0;j != m;++j)
if (i != j && hh[i][j].size())
v[i][j] = hh[i][j].begin()->l;
for (int i = 0;i != m;++i)
if (sh[i].size())
v[m][i] = sh[i].begin()->l;
for (int i = 0;i != m;++i)
if (fl[i] < a[i]) v[i][m + 1] = 0;
for (int i = 0;i != m + 2;++i)
for (int j = 0;j != m + 2;++j)
pv[i][j] = v[i][j];
for (int k = 0;k != m + 2;++k)
for (int i = 0;i != m + 2;++i)
for (int j = 0;j != m + 2;++j)
if (v[i][j] < v[i][k] + v[k][j])
v[i][j] = v[i][k] + v[k][j], pp[i][j] = k;
vector<int>pas; ans += v[m][m + 1];
solvpas(m, m + 1, pas);
//处理路径,因为要开始增删边了。
for (int i = 1;i != pas.size() - 1;++i)
delt2(pas[i], pas[i + 1]);
delt1(pas[1]); fl[pas.back()]++;
}
cout << ans << endl;
}
\\然而并不能过这一道题。
```
[例题2](https://codeforces.com/problemset/problem/724/E),同样非常好建模,但是不难发现边太多了,没法玩。
所以我们可以从最大流-最小割定理入手,算他的最小割。显然,因为图只有一层,即每一个城市对应的点都直连源汇,所以每一个点要么断源,要么断汇。
显然断汇的点仍有能力向后面的城市流货,而断源的不能,所以写一个 DP 出来就完了。核心代码如下:
```cpp
for (int j = 1;j <= i;++j)
dp[i & 1][j] = dp[i - 1 & 1][j] + p[i] + j * m,
tmin(dp[i & 1][j], dp[i - 1 & 1][j - 1] + s[i]);
```
## 2-SAT
记得我们曾经学过一个东西叫做“扩展域并查集”,说白了就是令每一坨 $[(k-1)\times n+1,k\times n]$ 的区间中的点 $i=(k-1)\times n+t$ 对应表示 $t$ 在 $k$ 状态下与别的状态的联系。两个点在一起就认为两个点对应的状态必定同时满足。
那这玩意这么好用,能不能用到 2-SAT 上呢?
很可惜,需要改一下题才能用得到。把或改成异或就行了。
思考一下并查集的底层逻辑:两个点对应的状态必定同时满足。换言之,你只能加双向边。
然而 2-SAT 并不是这样的,他用的是或,也就是说硬性的约束条件是:$x_i=\neg v_i\implies x_j=v_j$ 和 $x_j=\neg v_j\implies x_i=v_i$。都是单向的约束。
那我们思考一下这些限制中的强连通分量意味着什么?
显然,这意味着这些点对应的状态成立与否是相同的。同时我们就推出了如果 $x_i$ 与 $\neg x_i$ 在同一个强连通分量内,那么必定无解。
强连通分量怎么求呢?Kosaraju 和 tarjan 你选一个吧。
```cpp
for (int i = 1, a, b, c, d;i <= m;++i)
a = io.read(), b = io.read(), c = io.read(), d = io.read(),
son[a + b * n].emplace_back(c + (d ^ 1) * n),
son[c + d * n].emplace_back(a + (b ^ 1) * n);
//模板题约束条件示例
```
当然了,2-SAT 只是一个最直接的应用。其实他给我们提供的是一种单向限制的处理思路,适用性比 2-SAT 本身要更广很多。
顺带讲两个常用优化技巧:
### 线段树优化建图
T1[rt](https://www.luogu.com.cn/problem/AT_arc069_d),[弱化版](https://www.luogu.com.cn/problem/UVA1146)。
翻译一下就是有 $n$ 个数 $a_i$ 和 $n$ 个数 $b_i$,$n$ 次从 $a_i$ 或 $b_i$ 中选出一个数放入 $c$,排序后询问最小的 $\min_{i=1}^{n-1}c_{i+1}-c_i$。
我们可以假定 $a_i<b_i$。解法大概率会是二分答案。首先如果 $|a_j-a_i|<d$,那么这俩不能同时出现。以此来建边进行求解,复杂度 $O(n^2\log V)$。可以过弱化版。
但是这样并不够优,究其原因是我们需要大量的向一个区间内的点建边。
而这,我们显然可以使用线段树优化建边来飞过去。具体方式可以看下面这幅图:
比如本来是 $2$ 要向 $[1,2]$ 和 $[4,6]$ 两个区间建边。
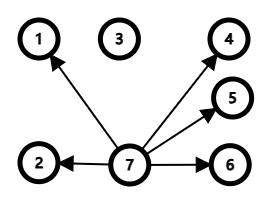
现在我们可以对原本的 $[1,6]$ 区间建一颗线段树如图:
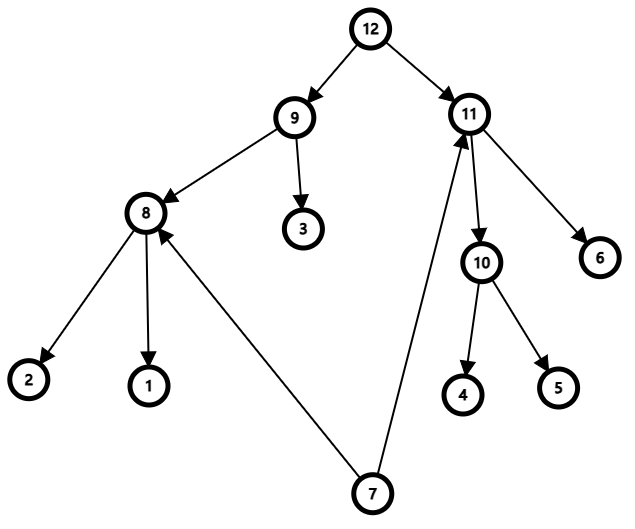
那这时候 $7$ 向 $8$ 连等同于向 $[1,2]$ 连,向 $11$ 连等同于向 $[4,6]$ 连。
显然这样下来每次要连的边数锐减至 $O(\log n)$ 条。总复杂度降至 $O(n\log n\log V)$。
比较核心的就是这坨:
```cpp
struct seg_tree {
struct node { int l, r; }re[10005 << 3];
inline static int segid(int p) { return p + 2 * n; }
inline void build(int l, int r, int p) {
re[p].l = l; re[p].r = r;
if (l == r) return void(son[segid(p)].push_back(ref(a[l].id)));
build(l, (l + r >> 1), p << 1);
build((l + r >> 1) + 1, r, p << 1 | 1);
son[segid(p)].push_back(segid(p << 1));
son[segid(p)].push_back(segid(p << 1 | 1));
}
inline void link(int l, int r, int lp, int p) {
if (l <= re[p].l && re[p].r <= r)
return void(son[lp].push_back(segid(p)));
if (l <= re[p << 1].r) link(l, r, lp, p << 1);
if (r > re[p << 1].r) link(l, r, lp, p << 1 | 1);
}
}sgt;
//注意只对区间连边有效
```
### 前缀优化建图
T2[rt](https://www.luogu.com.cn/problem/P6378)。
题意简单明了,转化也非常的明显,但是问题也就出在了这里。
相当于说在同一个部分内的 $x\neq y$,一定要 $x_1$ 到 $y_0$ 连一条边。只要我把所有的点放在同一个部分内,你的边数就是 $n^2$ 的。包炸的。
所以现在就是要去优化这个东西。我们不难发现,其实如果我们将这个部分内的点任意排序,那第 $i$ 个点一定要向第 $[1,i-1]\cup[i+1,size]$ 都连上边。
线段树优化建图不太好使,因为数据范围真的够大。但是思考如下结构:
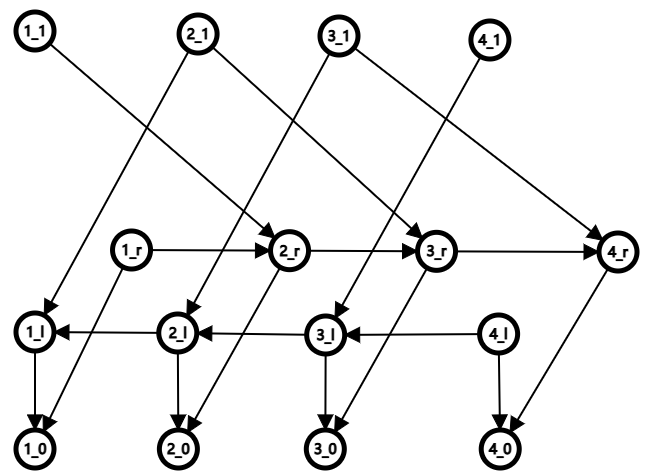
不难注意到,如果我们给整个部分添加两个辅助的侧链~~基团~~,那么这时候指向 $x_l$ 就间接指向了 $[1,x]$,指向 $x_r$ 就间接指向了 $[x,size]$。
非常妙,此题可解。我们称这种建图方式为前缀优化建图。比较核心的代码就是这坨:
```cpp
for (int i = 1, sz;i <= k;++i) {
for (int j = sz = io.read();j > 0;--j)
vl[j] = io.read(),
son[id(vl[j], stat_lp)].emplace_back(id(vl[j], stat_0)),
son[id(vl[j], stat_rp)].emplace_back(id(vl[j], stat_0));
for (int j = 1;j != sz;++j)
son[id(vl[j], stat_rp)].emplace_back(id(vl[j + 1], stat_rp)),
son[id(vl[j], stat_1)].emplace_back(id(vl[j + 1], stat_rp));
for (int j = sz;j > 1;--j)
son[id(vl[j], stat_lp)].emplace_back(id(vl[j - 1], stat_lp)),
son[id(vl[j], stat_1)].emplace_back(id(vl[j - 1], stat_lp));
}
```
## 二分图最大权匹配
从最基础的二分图最大权完美匹配讲起走:
最常用的是 KM 算法。他的思路是这样的:
首先我们假定原图存在完美匹配。然后,我们给每个点分配顶标 $h_i$,满足 $\forall (i,j)\in E,h_i+h_j\ge V_{(i,j)}$。
我们再取出 $E^\prime\in E$,满足 $\forall (i,j)\in E^\prime,h_i+h_j=V_{(i,j)}$,那么这时候,当 $E^\prime$ 中存在完美匹配时,$\sum h_p$ 就是答案。
正确性:$h_i+h_j\ge V_{(i,j)}$ 限定了每一条边都会具有的单调性,从而限定了整体的单调性(感性理解)。
算法流程:
首先令 $h_{l_i}=\max_{(l_i,r_j)\in E}V_{(l_i,r_j)},h_{r_i}=0$。显然满足限制条件。
接下来尝试扩大 $E^\prime$。在匈牙利算法中,从一个节点寻找然后匹配失败所遍历的树被称为交错树。显然,其中匹配上的边与没匹配上的边交错出现。
我们如果能在交错树上找到一条的路径,并将这条路径上的左部点 $h-=\Delta$,右部点 $h+=\Delta$,那么不会让交错树上原有的边消失,而且可能会出现新的匹配,从而增大 $E^\prime$。
为了防止一次性减小过多,$\Delta$ 应取为 $\min h_i+h_j-V_{(i,j)}$,其中 $i$ 在交错树上,$j$ 不在交错树上。
不难发现这样操作,交错树原有边不变,而且至少多一个新的边。也就是说理论上最多会需要 $m$ 轮。
那如果我们能将每次增广的时间复杂度降到 $O(n)$ 就可解了。
那很显然,如果我们使用 bfs 版的匈牙利算法,那么他每一次都是 $O(n^2)$ 的,然后再带上至多 $n$ 次增广($n$ 个节点肯定已经有匹配了),总复杂度 $O(n^3)$。
代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
#define int long long
int n, m, v[505][505], pl[505], pr[505];
int lm[505], rm[505], ext[505], lp[505], ans;
bool vil[505], vir[505];
inline void tmax(int& l, const int& r) { (l < r) && (l = r); }
inline void tmin(int& l, const int& r) { (l > r) && (l = r); }
inline void flip(int p) {
while (p) pr[p] = lp[p], swap(pl[lp[p]], p); //我去旧地方,你来我这里
}
inline void bfs(int sp) {
//将 sp 作为非匹配起点,bfs 版匈牙利找增广路
memset(ext, 0x0f, sizeof ext);
memset(lp, 0, sizeof lp);
memset(vil, 0, sizeof vil);
memset(vir, 0, sizeof vir);
queue<int>q; q.emplace(sp);
while (1) {
while (q.size()) {
int np = q.front(); q.pop(); vil[np] = 1;
//随便取出来一个左点,认为他被增广到了
for (int i = 1;i <= n;++i)
if (!vir[i] && lm[np] + rm[i] - v[np][i] < ext[i]) {
//右部点 i 可以取到并且比增量小
ext[i] = lm[np] + rm[i] - v[np][i]; lp[i] = np;
if (!ext[i]) //已经增广到相等子图内(lv+rv=ve),扩展
if (vir[i] = 1, !pr[i]) return flip(i);
else q.emplace(pr[i]);
//类似 dfs,没有就标记返回,有就尝试让对方让
}
}
//没有可行增广路,缩边权
int mind = 1e18;
for (int i = 1;i <= n;++i)
if (!vir[i]) tmin(mind, ext[i]);
//这个点此次没有增广到,希望被增广
if (mind > 1e12) return; // 确实没有能增广的了
for (int i = 1;i <= n;++i) if (vil[i]) lm[i] -= mind;
for (int i = 1;i <= n;++i)
if (vir[i]) rm[i] += mind;
else ext[i] -= mind; //本质上就是改了修改 rm 带来的对 ext 的影响
for (int i = 1;i <= n;++i)
if (!vir[i] && !ext[i])
if (vir[i] = 1, !pr[i]) return flip(i);
else q.emplace(pr[i]);
//和 bfs 时的 "可扩展" 处理方式一样
}
}
inline void km() {
for (int i = 1;i <= n;++i)
for (int j = 1;j <= n;++j)
tmax(lm[i], v[i][j]);
//每个左部点初始化为连边最大值,满足顶标要求
for (int i = 1;i <= n;++i) bfs(i);
for (int i = 1;i <= n;++i) ans += lm[i] + rm[i];
cout << ans << endl;
for (int i = 1;i <= n;++i) cout << pr[i] << " ";
}
signed main() {
ios::sync_with_stdio(0);
memset(v, 0xcf, sizeof v); cin >> n >> m;
//默认完全图,不足的要极小值补齐
for (int i = 1, l, r;i <= m;++i)
cin >> l >> r, cin >> v[l][r];
km();
}
```
然后我们偶遇了一个 trick: 抓大放小,[rt](https://vjudge.net/problem/HDU-3315#author=DeepSeek_zh)。
其实这个名字起的听生动的。说白了,就是给更重要的那部分提权,使得它的影响力严格优于次要部分。
在这道题中,我们需要在满足最大匹配的前提下使得换位置的元素个数最少。
我们令没有交换位置的匹配权值大 $1$,并且原先匹配的贡献乘上 $100$,这时候对最大匹配的影响至少为 $100$,而总的不交换的贡献严格小于 $100$,从而优先满足最大匹配,然后满足最少交换。
## 最小树形图
主要讲三个东西:朱刘,tarjan,堆优化朱刘。
### 朱刘算法
朱刘算法思路很简单:不停的找环,把环缩成一个大点,然后接着找,直到形成一个 DAG。
更大的思路是除了根节点,每一个点尽可能选取最小的入边。显然在一个环中,我们不能直接抛弃最大的边,而是将连向这个环的那个边减去环上随后的那个边的权值。
也就是在反悔贪心。同时你也就可以反应过来为什么不能暴力选最大边。
所以你要是暴力模拟这个过程的话,你就得到了朱刘算法。代码如下:
```cpp
inline int vap() {
while (1) {
for (int i = 1;i <= n;++i)
mv[i] = 1e9, f[i] = lp[i] = rp[i] = 0;
//清空最小边,vis(lp) 标记,所在环(rp) 标记
for (int i = 1;i <= m;++i)
if (l[i] != r[i] && v[i] < mv[r[i]])
mv[r[i]] = v[i], f[r[i]] = l[i];
//1. 不是自环才有效; 2. 边权更小
mv[k] = 0; cnt = 0;
for (int i = 1;i <= n;++i)
if (mv[i] == 1e9) return -1;
//有一个非根点没有父节点
else ans += mv[i];
for (int p = 1, np = 1;p <= n;p++, np = p) {
while (np != k && lp[np] != p && !rp[np]) lp[np] = p, np = f[np];
//vis(lp) 标记(避开上一次的flag,减小常数),不停跳,直到有访问过的或者创到 root
if (!rp[np] && np != k) { rp[np] = ++cnt; //在最新的环上转一圈
for (int i = f[np];i != np; i = f[i]) rp[i] = cnt;
}//只有在他不在已知环上而且非 rt 的时候可以重新标记
}
if (!cnt) return ans; //没有环
for (int i = 1;i <= n;++i)
if (!rp[i]) rp[i] = ++cnt; //孤立点处理
for (int i = 1;i <= m;++i)
v[i] -= mv[r[i]], l[i] = rp[l[i]], r[i] = rp[r[i]];
//重新计算边权
n = cnt; k = rp[k];
}
}
```
### tarjan/堆优化朱刘
他们的优化思路很简单,就是堆优化。
那么 tarjan 是怎么去求解的呢?它分为 **收缩** 与 **伸展** 两个过程。说白了就是先将整个图按照强连通分量缩成一个点,然后再根据记录的信息给把树重新建出来。
收缩怎么收缩呢?我们每一次任意选一个在堆中没有入边的的节点,并将它的最小入边加入到堆中。如果新加入的这条边使堆中的边形成了环,那么将构成环的那些结点收缩。我们不停的收缩,直到整张图被收缩为一个节点。
堆中的边总是会形成一条路径 $v_1,v_2,\dots,v_k$,由于图是强连通的,这个路径必然存在。我们每一次选一条最小入边 $v_k\gets u$。如果 $u$ 不在 $v$ 中就将 $v_{k+1}$ 定为 $u$。如果在就形成了一个环。我们将这个环缩掉,显然还在最后。我们接着处理这个点就完了。
当然了,收缩的过程中需要记录一些信息。伸展过程是相对简单的,以原先要求的根节点 $r$ 为起始点,对 $r$ 到收缩树的根上的每一个环进行伸展。再以 $r$ 的祖先结点 $f_r$ 为起始点,将其到根的环展开,直到遍历完所有的结点。
一种实现:
```cpp
inline void merge() {
for (int i = 1;i <= n;++i) {
for (const edge& e : son[i]) q.emplace(new node(e));
while (q.size() > 1) {
hptr p1 = q.front(); q.pop();
hptr p2 = q.front(); q.pop();
q.emplace(merge(p1, p2));
} //大小期望为 1,1,...,1,2,2,...,2,4,4,...,4,...
hp[i] = q.front(); q.pop(); //其实是线性建堆
}
vis[1] = 1; //“随机”选了一个点,100% 选中 1 点
for (int p = 1, np = 1;hp[p];vis[np = p] = 1) {
do lfp[p] = top(hp[p]), p = mss[lfp[p].l];
while (p == np && hp[p]);
if (p == np) break;
if (!vis[p]) continue;
int cnp = ++n;
for (p = np; p != n;p = cnp) {
mss.f[p] = lp[p] = n;
if (hp[p]) hp[p]->tg -= lfp[p].v;
hp[n] = merge(hp[n], hp[p]);
cnp = mss[lfp[p].l];
rinxtp[cnp == n ? np : cnp] = p;
}
}
}
inline int expand(int rt, int ep) {
int ret = 0;
for (;rt != ep;rt = lp[rt]) {
for (int sp = rinxtp[rt];sp != rt;sp = rinxtp[sp])
if (lfp[sp].orv >= 1e16) return 1e16;
else ret += expand(lfp[sp].r, sp) + lfp[sp].orv;
if (ret >= 1e16) return 1e16;
}
return ret;
}
inline int dmst() {
merge(); int ret = expand(rt, n);
if (ret >= 1e16) ret = -1; return ret;
}
```
堆优化朱刘相对而言可能会更好理解一点,真的就是给朱刘套上了和 tarjan 类似的可并堆优化。但是要注意处理指向环内的边。这些边对 tarjan 正确性没有影响,但是对朱刘有影响。给出完整的代码如下:
```cpp
int n, m, rt;
struct edge {
int p, v;
edge(int pi = 0, int vi = 0) :p(pi), v(vi) {};
}; vector<edge>son[100005];
inline void adde(int l, int r, int v) {
son[r].push_back(edge(l, v));
}
struct mss {
signed h[100005];
inline signed operator[](signed p) {
return h[p] != p ? h[p] = (*this)[h[p]] : p;
}
}fr, inc;
struct m_incl_heap {
struct node {
edge e; signed ls, rs; int tg;
}re[1000005]; signed cnt, h[100005];
inline node& ls(signed p) { return re[re[p].ls]; }
inline node& rs(signed p) { return re[re[p].rs]; }
inline void pud(signed p) {
if (re[p].ls) ls(p).tg += re[p].tg, ls(p).e.v += re[p].tg;
if (re[p].rs) rs(p).tg += re[p].tg, rs(p).e.v += re[p].tg;
re[p].tg = 0;
}
inline signed merge(signed l, signed r) {
if (l == r) return l; if (!l || !r) return l | r;
if (re[l].e.v > re[r].e.v) swap(l, r);
pud(l); re[l].rs = merge(re[l].rs, r);
swap(re[l].ls, re[l].rs); return l;
}
inline void clear() {
memset(re, 0, sizeof re);
memset(h, 0, sizeof h); cnt = 0;
}
inline void pop(signed& p) {
pud(p); p = merge(re[p].ls, re[p].rs);
}
inline void noselfptr(int tp, int r) {
while (h[tp] && inc[re[h[tp]].e.p] == r) pop(h[tp]);
}
inline void addev(int p, int v) {
re[p].e.v += v; re[p].tg += v;
}
}mih;
queue<int>q; edge lfp[100005];
inline void solve() {
mih.clear(); memset(lfp, 0, sizeof lfp);
for (signed i = 1;i <= n;++i) {
for (signed j = 0;j != son[i].size();++j)
mih.re[++mih.cnt].e = son[i][j], q.push(mih.cnt);
while (q.size() > 1) {
signed p1 = q.front(); q.pop();
signed p2 = q.front(); q.pop();
q.push(mih.merge(p1, p2));
}
if (q.size()) mih.h[i] = q.front(), q.pop();
}
for (signed i = 1;i <= n;++i) fr.h[i] = inc.h[i] = i;
for (signed i = 1;i <= n;++i) {
if (i == rt) continue;
if (!mih.h[i]) { puts("-1"); return; }
mih.noselfptr(i, i); lfp[i] = mih.re[mih.h[i]].e;
if (fr[inc[lfp[i].p]] == i) {
int rsm = 0, p = i;
do rsm += lfp[p].v; while ((p = inc[lfp[p].p]) != i);
do mih.pop(mih.h[p]); while ((p = inc[lfp[p].p]) != i);
do mih.addev(mih.h[p], rsm - lfp[p].v); while ((p = inc[lfp[p].p]) != i);
do mih.h[i] = mih.merge(mih.h[i], mih.h[p]), fr.h[p] = inc.h[p] = i; while ((p = inc[lfp[p].p]) != i);
mih.noselfptr(i, i); i--;
}
else fr.h[i] = lfp[i].p;
}
int ans = 0;
for (signed i = 1;i <= n;++i)
if (inc[i] == i) ans += lfp[i].v;
cout << ans << endl;
}
signed main() {
ios::sync_with_stdio(0);
n = io.read(); m = io.read(); rt = io.read();
for (signed i = 1, l, r;i <= m;++i)
l = io.read(), r = io.read(), adde(l, r, io.read());
solve(); return 0;
}
```
见的不多,而且目前来看遇到了基本上就挺板的,不再多说了。
## 仙人掌与圆方树
[模板题](https://www.luogu.com.cn/problem/P5236)显然就是一个狭义圆方树求仙人掌上两点之间的距离的板子题。
先说一下什么是仙人掌:仙人掌就是一种特殊的图,满足每一个边最多在一个简单环上。
我们会使用倍增 LCA 和树上前缀和来快速的求解树上的两点之间的距离。那如果我们可以将这个图转变成一棵树的话是不是就做完了?狭义圆方树就干了这么一点事。
那我们想一想这个圆方树都要处理一些什么呢?显然,成环的地方就是我们要重点考虑的。正是这些环,使得原先的图不是树。我们考虑如下结构:
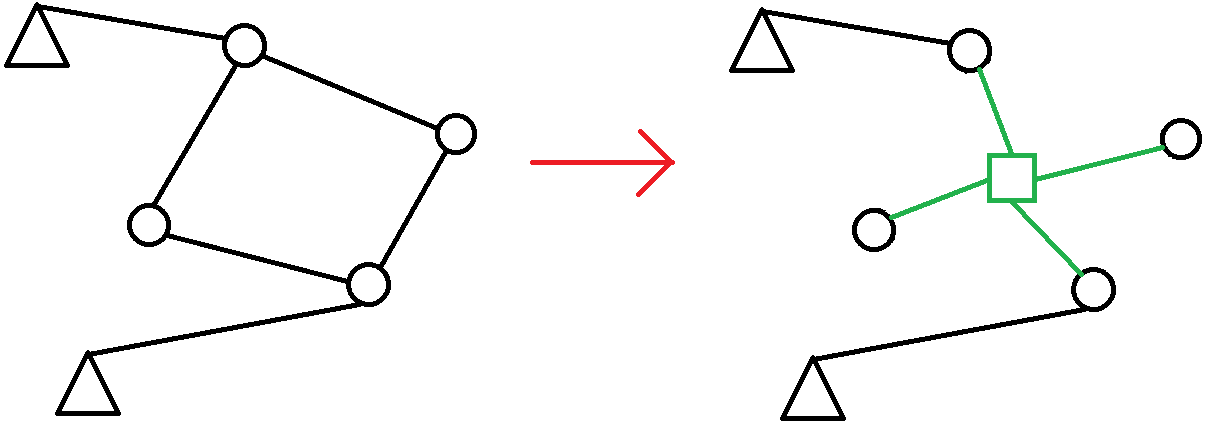
肉眼可见的,我们通过添加一个点使得一个环变成了一个菊花一样的东西。我们处理完后一定是一棵树。而树上除了根以外别的点都一定是有父节点的。只要我们指定一个圆点为根节点,那每一个这样的环都会有一个最靠上的节点。
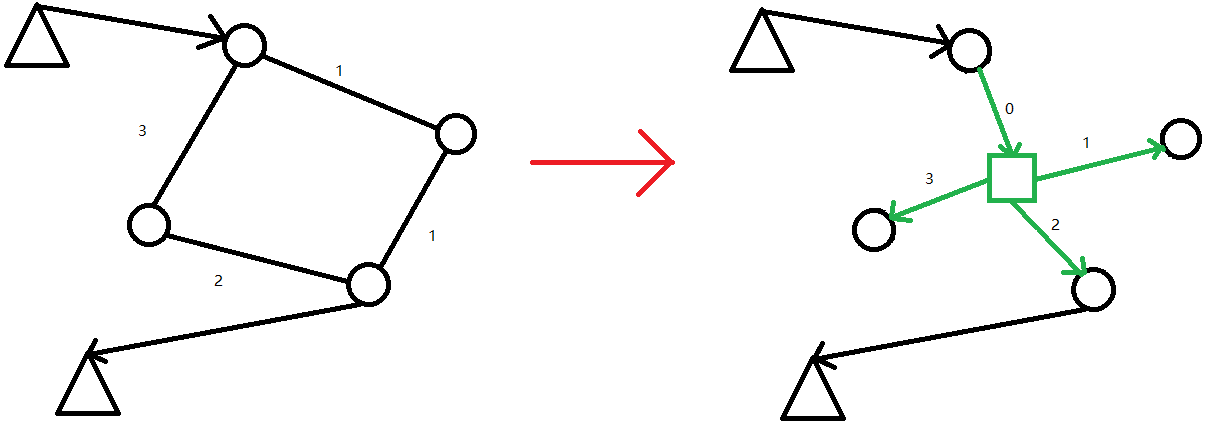
我们把这个节点视为这个环的起点,像任意方向绕着环转一圈,并把每个点的“距离”标记为第一次遇到他时走过的路程。接下来,我们把环的起点到这个环的方点的边权设置为 $0$,把这个环的方点到其他点的权值设为本环的起点到那个点的**最短路的长度**。
这意味着我们还需要处理这个环的长度。因为最短路是这个点的“距离”和环长减去“距离”的最小值。就像这样:
建出来了树了之后,分成两种大的情况:
第一种:两个点的 LCA 是一个圆点。这种情况相当的好,答案就是两个点在树上的距离。
第二种:两个点的 LCA 是一个方点。这意味着这两个点不停往上跳,最后跳到了一个环的不同的两个点上。这时候我们要处理出二者在环上的最小距离。于是我们之前记录的信息就发挥作用了。两个点之间有两个不同的种路径,一种是按照“距离”的行走方向的那段弧,长度为二者的“距离”的差,另一种是走另一段弧,长度是环长减第一种的长度。
至此,狭义圆方树求仙人掌上两点之间的距离讲解完毕。代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
struct node {
int p, v, id;
node(int pi = 0, int vi = 0, int ii = 0) :
p(pi), v(vi), id(ii) { }
}; vector<node>son[10005], nsn[20005];
int n, m, k, cnt, dfn[20005], low[20005], cln[20005], dp[20005];
int f[20005][16], v[20005], fe[20005], d[20005], vcn, dis[20005], fl, fr;
inline void tmin(int& l, int r) { (l > r) && (l = r); }
inline void mkcir(int ep, int sp, int sv) {
for (int p = sp; p != ep; p = f[p][0]) d[p] = sv, sv += v[p];
d[ep] = cln[ep] = sv; nsn[ep].emplace_back(++vcn);
for (int p = sp; p != ep; p = f[p][0])
cln[p] = sv, nsn[vcn].emplace_back(p, min(d[p], sv - d[p]));
}
inline void tarjan(int p, int id) {
dfn[p] = low[p] = ++cnt;
for (const node& sp : son[p])
if (!dfn[sp.p]) {
f[sp.p][0] = p; v[sp.p] = sp.v; fe[sp.p] = sp.id;
tarjan(sp.p, sp.id), tmin(low[p], low[sp.p]);
if (dfn[p] < low[sp.p]) nsn[p].emplace_back(sp.p, sp.v);
}
else if (id != sp.id) tmin(low[p], dfn[sp.p]);
for (const node& sp : son[p])
if (dfn[p] < dfn[sp.p] && fe[sp.p] != sp.id)
mkcir(p, sp.p, sp.v);
}
inline void dfs(int p, int fa) {
f[p][0] = fa; dp[p] = dp[fa] + 1;
for (int i = 1;i <= 15;++i)
f[p][i] = f[f[p][i - 1]][i - 1];
for (const node& sp : nsn[p])
dis[sp.p] = dis[p] + sp.v, dfs(sp.p, p);
}
inline int lca(int l, int r) {
if (dp[l] < dp[r]) swap(l, r);
for (int i = 15;i >= 0;i--)
(dp[f[l][i]] >= dp[r]) && (l = f[l][i]);
if (l == r) return l;
for (int i = 15;i >= 0;i--)
(f[l][i] != f[r][i]) && (l = f[l][i], r = f[r][i]);
return fl = l, fr = r, f[l][0];
}
signed main() {
ios::sync_with_stdio(0);
cin >> n >> m >> k; vcn = n;
for (int i = 1, l, r, v;i <= m;++i)
cin >> l >> r >> v,
son[l].emplace_back(r, v, i),
son[r].emplace_back(l, v, i);
tarjan(1, 0); dfs(1, 0);
for (int i = 1, l, r, la;i <= k;++i)
if (cin >> l >> r, (la = lca(l, r)) > n) {
int lln = abs(d[fl] - d[fr]), rln = cln[fl] - lln;
cout << (dis[l] - dis[fl]) + (dis[r] - dis[fr]) + min(lln, rln) << endl;
}
else cout << dis[l] + dis[r] - dis[la] * 2 << endl;
}
```
同学提出了一个问题,我觉得有必要讲一下:一个点有可能会在多个环里,为什么我们不需要记录这个点在每一个环中的“距离”和环长?
我们想一下我们询问的过程:首先如果 LCA 就是圆点的话那没什么影响,如果是方点的话那才会用到“距离”和环长。但是很显然,一个环的起点是骑在这个方点的上面的,也就是我们永远也不会用到一个环的起点在这个环上的信息。
而很显然,我们在建树的过程中,一个点永远也不会成为多个环的“终点”,而且最后一次处理这个点就是在他是“终点”的那棵树上。故不需要记录一个点在每个环上的信息。
那么,一个比较常见的应用就是圆方树上 DP,虽然我们不一定要把树真正的建出来。[如题](https://www.luogu.com.cn/problem/P10779)。
面对仙人掌的题,我们最基本的思路就是转化成树上问题求解。而很显然仙人掌本质上就是一棵树上面挂了一些边不相交的基环。
先看第一道题:[没有上司的舞会](https://www.luogu.com.cn/problem/P1352)。没错,这就是同一道题,只不过仙人掌上没有环而已。
为什么思考这个问题呢?因为这就是在推最基础的 DP 式子。显然:
$dp_{i,0}=\sum_{s\texttt{ is son of }i}\max(dp_{s,0},dp_{s,1}),dp_{i,1}=1+\sum_{s\texttt{ is son of }i}dp_{s,0}$。
再看第二道题:[城市环路](https://www.luogu.com.cn/problem/P1453),不过请自己弱化一下,每一个点的人流量都是 $1$。没错,这就是同一道题,只不过仙人掌上有且仅有一个环而已。
那我们想一下面对基环树时的套路呢?先随便选择两个相邻的点,指定他们的状态,然后进行 DP。
现在看回这一道题。现在“树”上有一堆子基环了,我们怎么办?
仙人掌的典型套路:把每一个环拆出来,逐个击破。剩下的非环边正常处理就完了。
所以面对基环树 DP,思考大抵是有点套路的:思考树上怎么做,思考怎么处理基环,套仙人掌找环处理环的板子。
代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
struct node {
int p, id;
node(int pi = 0, int vi = 0) :p(pi), id(vi) {};
};
int n, m, dp[50005][2], cnt, dfn[50005], low[50005]; vector<node>son[50005];
int f[50005], v[50005], fe[50005];
inline void tmin(int& l, int r) { (l > r) && (l = r); }
inline void mkdp(int fp, int p) {
int v0 = 0, v1 = 0, t0, t1;
for (int i = p;i != fp;i = f[i])
t0 = v0 + dp[i][0], t1 = v1 + dp[i][1],
v0 = max(t0, t1), v1 = t0;
//选自己就选不了前一个,不选自己就任意选
dp[fp][0] += v0; v0 = 0; v1 = -1e9;
//只要选上一个贡献够小,就一定没人会选上一个
for (int i = p;i != fp;i = f[i])
t0 = v0 + dp[i][0], t1 = v1 + dp[i][1],
v0 = max(t0, t1), v1 = t0;
dp[fp][1] += v1;
}
inline void tarjan(int p, int id) {
dfn[p] = low[p] = ++cnt; dp[p][1] = 1;
for (const node& sp : son[p])
if (!dfn[sp.p]) {
f[sp.p] = p; fe[sp.p] = sp.id;
tarjan(sp.p, sp.id), tmin(low[p], low[sp.p]);
if (low[sp.p] > dfn[p])
dp[p][0] += max(dp[sp.p][0], dp[sp.p][1]),
dp[p][1] += dp[sp.p][0]; //非环边正常处理
}
else if (id != sp.id) tmin(low[p], dfn[sp.p]); //严禁当场返祖
for (const node& sp : son[p])
if (dfn[p] < dfn[sp.p] && fe[sp.p] != sp.id)
mkdp(p, sp.p); //找到一个底下的环
}
signed main() {
ios::sync_with_stdio(0);
cin >> n >> m;
for (int i = 1, l, r;i <= m;++i)
cin >> l >> r,
son[l].emplace_back(r, i),
son[r].emplace_back(l, i);
tarjan(1, 0); cout << max(dp[1][0], dp[1][1]) << endl;
}
```
# 数据结构
## 线段树
线段树是 OI 当中最常用的数据结构之一,务必认真掌握。接下来讲解的是比较常用的多种线段树及其变体,大致按难度排序。
###### 这里有你没写完的东西,杂鱼...
## ZKW线段树
很神奇的卡常用的线段树,但是支持面远远比不上普通线段树。
思路就是更改递归为循环。我们可以注意到,在线段树中,$fa_i=\lfloor\frac{i}{2}\rfloor$,因此,我们维护一个数组,使其也满足这样的性质,每次循环向上更新信息,就完成了。
查询的时候我们从区间的左右部分的端点外的一点开始操作。对于一个端点,当我们向内跳的时候,统计右儿子的贡献,当向外跳的时候,不统计贡献,直到两端点重合。
但是区间修改使用标记永久化,无法维护标记有顺序要求的情况。
参考代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
#define lc(i) (i << 1)
#define rc(i) (i << 1 | 1)
int n, m, a[2000005], s;
inline void ins(int p, int v) {
do a[p] += v; while (p >>= 1);
}
inline int que(int l, int r) {
int v = 0; do v += (~l & 1 ? a[l ^ 1] : 0) + (r & 1 ? a[r ^ 1] : 0);
while ((l >>= 1) ^ (r >>= 1) ^ 1); return v;
}
signed main() {
ios::sync_with_stdio(0); cin >> n >> m;
for (s = 1;s < n + 2;s <<= 1);
for (int i = 1;i <= n;++i) cin >> a[i + s];
for (int i = s - 1;i > 0;i--) a[i] = a[lc(i)] + a[rc(i)];
for (int i = 1, o, l, r;i <= m;++i)
if (cin >> o >> l >> r, o & 1) ins(l + s, r);
else cout << que(l + s - 1, r + s + 1) << endl;
}
```
## 并查集
### 普通并查集
并查集要维护的操作主要就是“合并”和“查询”。具体来说,他要能够支持将两个集合合并,并查询每一个元素在哪一个集合,比如判断二者在不在同一个集合中。
不难想到我们可以用类似于树的结构来实现这一点,具体的来说,我们要合并 $l,r$ 所在的集合的时候,我们找到这两个集合的代表元素 $f_l,f_r$,并将其中一者的父节点设置为另一个。
但显然这样做如果给你整成链状的你就炸了,因此我们有诸多技巧来维护其时间复杂度正确。
第一种是路径压缩,也就是每一次查询完某个节点之后,我们将这个节点到他的代表节点这一条链上的所有节点的直接父节点设为代表。这样做时间复杂度均摊是 $O(\log)$ 的。显然不是特别优。如果你再把他们按照大小合并,也就是将大小更小的那一坨的父亲设为更大的那一坨,时间复杂度进一步降至 $O(\alpha(n))$。其中 $\alpha$ 是反阿克曼函数。
实际应用中,根本没人去卡那个 $\log$,所以更常见的情况下你并不需要按大小合并。
还有另一种是按秩合并,也就是树高更低的合并到树高更高的上面。时间复杂度显然是 $O(\log)$ 的。
### 扩展域并查集
又名种类并查集,思路就是拆点。举[食物环](https://www.luogu.com.cn/problem/P2024)为例题。
在这道题中,每一个生物对应有三种状态:是 A/B/C 类生物。于是我们将每个生物拆成三个点,比如说第 $i$ 个生物就会被拆成三个不同的点 $p_{i,A},p_{i,B},p_{i,C}$,其中 $p_{i,X}$ 表示 $i$ 生物是 $X$ 类生物这个陈述为真。而我们将并查集视为一种等价关系,即如果 $p_{i,X},p_{j,Y}$ 在同一个集合内,我们就认为这两个命题要么都成立,要么都不成立。
那么对应到这一道题,如果两个生物是同类,则 $p_{i,A},p_{j,A}$,$p_{i,B},p_{j,B}$,$p_{i,C},p_{j,C}$ 应该分别进行合并。显然判断条件是 $i,j$ 不能相互啃食,比如 $p_{i,A},p_{j,B}$ 或 $p_{i,B},p_{j,A}$ 等共计 $6$ 个条件。二者相互啃食的类似,不再赘述。
可以给出核心代码如下:
```cpp
if (cin >> t >> l >> r, t & 1) {
if (l > n || r > n) {
ans++; continue;
}
bool cn = 0;
cn |= (find(id(l, 0)) == find(id(r, 1)));
cn |= (find(id(l, 1)) == find(id(r, 2)));
cn |= (find(id(l, 2)) == find(id(r, 0)));
cn |= (find(id(l, 0)) == find(id(r, 2)));
cn |= (find(id(l, 1)) == find(id(r, 0)));
cn |= (find(id(l, 2)) == find(id(r, 1)));
if(cn) {
ans++; continue;
}
merge(id(l, 0), id(r, 0));
merge(id(l, 1), id(r, 1));
merge(id(l, 2), id(r, 2));
}
else {
if (l > n || r > n || l == r) {
ans++; continue;
}
bool cn = 0;
cn |= (find(id(l, 0)) == find(id(r, 0)));
cn |= (find(id(l, 1)) == find(id(r, 1)));
cn |= (find(id(l, 2)) == find(id(r, 2)));
cn |= (find(id(l, 1)) == find(id(r, 0)));
cn |= (find(id(l, 2)) == find(id(r, 1)));
cn |= (find(id(l, 0)) == find(id(r, 2)));
if (cn) {
ans++; continue;
}
merge(id(l, 0), id(r, 1));
merge(id(l, 1), id(r, 2));
merge(id(l, 2), id(r, 0));
}
```
### 权值并查集
这类并查集会需要维护多维的信息,比如和代表的实际距离。[例题](https://www.luogu.com.cn/problem/P1196)。
一般情况下,我们会考虑在重定向父亲的时候先去除父节点造成的影响,然后在路径压缩的过程中再逐步去合并信息。比如说当有一种信息是针对整个并查集改的的时候,我们会在合并的时候先将合并者的信息“减去”被合并者的信息,然后再在后面恢复过来。当然了,这个例题体现不出来。
一定要注意路径压缩时对信息进行合并的时候要记录好原先的父亲,不要随意拿着新的“父亲”去更新信息。
可以给出核心代码如下:
```cpp
inline int find(int p) {
if (f[p] == p) return p;
int fp = f[p];
f[p] = find(f[p]);
v[p] += v[fp];
return f[p];
}
```
## 莫队
这绝对称得上是离线算法中的代表之一。话说,彼时的 $\text{OI}$ 界 $\text{RMQ}$ 问题并起,而我们的暴力却不能骗到太多分,于是 $\text{CF}$ 高手圈内流行起了一种快速处理离线问题的算法,并由莫涛整理,这种算法便被称之为莫队。后人便在此基础上加以拓展,统称为莫队算法。
算法的实现就是询问区间依靠 $l,r$ 指针反复横跳。他要求我们能够在较优的时间复杂度内(一般为 $O(1)$)用 $[l,r]$ 的答案及状态转移出 $[l\pm1,r]$ 或 $[l,r\pm1]$ 的答案及状态。这时候,我们通过一定的方式找到一个较优的询问序列,使得其左右横跳的次数较为少。
这时候莫队的神奇重排询问方式发挥了作用。首先我们先这 $n$ 个点顺序平均分成 $\sqrt n$ 个块,然后询问间排序时以左端点所在的块编号为第一关键字,右端点为第二关键字。这时候,右端点右移距离不超过 $n\sqrt n$,左端点移动次数在 $m\sqrt n$ 的级别控制内,均有不超过 $2$ 的理论常数(~~像黑塔那样~~左右乱滚)。于是总复杂度在 $O((n+m)\sqrt n)$。
### 普通莫队
显然,上面的就是普通莫队。
以[袜子](https://www.luogu.com.cn/problem/P1494)为例,核心操作就是这样的:
```cpp
inline void add(int p) {
ak -= get(cnt[a[p]]);
cnt[a[p]]++;
ak += get(cnt[a[p]]);
}
inline void del(int p) {
ak -= get(cnt[a[p]]);
cnt[a[p]]--;
ak += get(cnt[a[p]]);
}
while (nr < q[i].r) add(++nr);
while (nl > q[i].l) add(--nl);
while (nr > q[i].r) del(nr--);
while (nl < q[i].l) del(nl++);
```
特别注意,我们应尽量保证区间长度不为负,所以我们总是先扩展再收缩。
### 带修莫队
核心思路就是加上一维时间戳,因为 $l,r$ 同在 $[1,n]$ 的区间内,所以我们把 $l$ 的排序方式强加在 $r$ 上,然后 $t$ 按照原来 $r$ 的排序方式升序排序。当块长取 $\frac{n^{\frac{2}{3}}t^{\frac{1}{3}}}{m^{\frac{1}{3}}}$ 时时间复杂度为最优的 $O(n^{\frac{2}{3}}m^{\frac{2}{3}}t^{\frac{1}{3}})$。但是一般情况下 $n,m,t$ 同阶,所以时间复杂度常被视为 $O(n^\frac{5}{3})$。
带修莫队有他的局限性。只支持单点修改,时间复杂度也已经只比暴力优了 $n^\frac{1}{3}$,可能要卡常。
### 回滚莫队
回滚怎么滚?为什么要滚?问题很简单,有的信息在增加或删除的时候很难在一个能接受的时间复杂度内处理出来。于是,我们就只让他扩展。
具体的,我们暴力处理完块内的询问后,块间的我们让他的左端点固定在 $block_r+1$ 的位置,保持右端点单增,每到一个询问,记录当前的状态,让左端点扩展,到之后记录答案,然后快速滚回到 $block_r+1$。
可以参见[野史的研究](https://www.luogu.com.cn/problem/AT_joisc2014_c)的代码。
```cpp
#include<bits/stdc++.h>
using namespace std;
inline int read() {
int r = 0; char c = getchar();
while (c < '0' || c>'9') c = getchar();
while (c >= '0' && c <= '9') r = r * 10 + (c ^ 48), c = getchar();
return r;
}
inline void write(long long x) {
if (x > 9) write(x / 10);
putchar(x % 10 ^ 48);
return;
}
inline void writi(long long args) {
write(args); putchar(10);
}
struct node {
int l, r, id;
}q[100005];
int n, m, v[100005], sz, tot; long long ans[100005], res;
unordered_map<int, int>tv; int t[100005], vlt[100005];
#define blk(x) (x/sz)
inline bool cmp(const node& l, const node& r) {
if (blk(l.l) ^ blk(r.l)) return blk(l.l) < blk(r.l);
return l.r < r.r;
}
inline void add(int p) {
t[p]++; res = max(res, vlt[p] * 1ll * t[p]);
}
signed main() {
n = read(), m = read(); sz = ceil(sqrt(m));
for (int i = 1; i <= n; ++i) {
v[i] = read();
if (!tv[v[i]])
tv[v[i]] = ++tot,
vlt[tot] = v[i];
v[i] = tv[v[i]];
}
for (int i = 1; i <= m; ++i)
q[i].l = read(), q[i].r = read(), q[i].id = i;
sort(q + 1, q + m + 1, cmp);
for (int k = 1; k <= m;) {
int pt = k, rt, lp, rp;
while (pt <= m && blk(q[pt].l) == blk(q[k].l))pt++;
rt = blk(q[k].l) * sz + sz;
while (k < pt && q[k].r < rt) {
res = 0; int id = q[k].id, l = q[k].l, r = q[k].r;
for (int i = l; i <= r; ++i) add(v[i]); k++;
ans[id] = res;
for (int i = l; i <= r; ++i)t[v[i]]--;
}
res = 0; lp = rt; rp = rt - 1;
while (k < pt) {
int id = q[k].id, l = q[k].l, r = q[k].r;
while (rp < r) add(v[++rp]);
long long bak = res;
while (lp > l) add(v[--lp]);
ans[id] = res;
while (lp < rt) t[v[lp++]]--;
res = bak; k++;
}
memset(t, 0, sizeof t);
}
for (int i = 1; i <= m; ++i) writi(ans[i]);
return 0;
}
```
### 树上莫队
经典的序列问题上树。处理方式无非就两种:把树拍成序列;重链剖分吃掉这棵树。很显然,对于莫对这种喜欢~~像黑塔那样~~左右乱滚的神奇算法来说,第一个方式会更友善一些。
最终,我们选择了欧拉序,即进子树记录一次,出子树记录一次。这样子,我们可以通过一个点在序列中出现的次数轻松的知道他到底在不在序列上。
一般的,我们会将其拆成 $[l,lca]$ 和 $[lca,r]$ 两条链来处理。由于欧拉序的特殊性,对于不满足一者在另一者的子树内时,我们需要记录 $lca$。
然后就是类似于普通莫队的思路了。下面给一个[树上莫队](https://www.luogu.com.cn/problem/SP10707)的代码:
```cpp
#include<bits/stdc++.h>
using namespace std;
namespace indata {
int n, m, v[100005], tot, l2g[40005], ans[100005];
unordered_map<int, int>um;
inline void lsh() {
for (int i = 1; i <= n; ++i) {
if (!um[v[i]]) um[v[i]] = ++tot;
v[i] = um[v[i]];
}
}
inline void getlog2() {
for (int i = 1; i <= n; ++i)
l2g[i] = l2g[i - 1] + (1 << l2g[i - 1] == i);
}
}
using indata::n; using indata::m; using indata::v; using indata::l2g; using indata::ans;
namespace tree { inline int getlca(int, int); };
namespace mque {
int olq[80005], tot, fp[40005], lp[40005], sz;
bool st[40005];;int cnt[40005], res;
struct node {
int l, r, p, id;
}q[100005];
inline void inque() {
for (int i = 1; i <= m; ++i) {
int a, b, lcp; cin >> a >> b;
if (fp[a] > fp[b]) swap(a, b);
lcp = tree::getlca(a, b);
if (a == lcp) q[i].id = i, q[i].l = fp[a], q[i].r = fp[b];
else q[i].id = i, q[i].l = lp[a], q[i].r = fp[b], q[i].p = lcp;
//cerr << i << " query " << q[i].l << " to " << q[i].r
// << " special " << q[i].p << endl;
}
}
inline int blk(int x) {
return x / sz;
}
inline bool cmp(const node& l, const node& r) {
if (blk(l.l) ^ blk(r.l)) return blk(l.l) < blk(r.l);
return l.r < r.r;
}
inline void add(int p) {
//cerr << "add " << p << " val " << v[p] << endl;
st[p] ^= 1;
if (!st[p]) {
cnt[v[p]]--;
if (!cnt[v[p]]) res--;
}
else {
if (!cnt[v[p]]) res++;
cnt[v[p]]++;
}
}
inline void solve() {
for (int k = 1, l = 1, r = 0; k <= m; ++k) {
int id = q[k].id, lp = q[k].l, rp = q[k].r, np = q[k].p;
while (r < rp) add(olq[++r]);
while (r > rp) add(olq[r--]);
while (l < lp) add(olq[l++]);
while (l > lp) add(olq[--l]);
if (np) add(np); ans[id] = res;
if (np) add(np);
}
}
}
using mque::olq; using mque::q; using mque::lp; using mque::fp;
namespace tree {
vector<int>son[40005]; int a, b;
int dep[40005], fa[40005][16];
inline void in_tree() {
for (int i = 1; i ^ n; ++i)
cin >> a >> b,
son[a].emplace_back(b),
son[b].emplace_back(a);
}
inline void dfs(int pos, int fap) {
fa[pos][0] = fap; dep[pos] = dep[fap] + 1;
for (int i = 1; i <= l2g[dep[pos]]; ++i)
fa[pos][i] = fa[fa[pos][i - 1]][i - 1];
olq[++mque::tot] = pos; fp[pos] = mque::tot;
for (int i = 0; i < son[pos].size(); ++i)
if (son[pos][i] != fap) dfs(son[pos][i], pos);
olq[++mque::tot] = pos; lp[pos] = mque::tot;
}
inline int getlca(int lp, int rp) {
if (lp == rp) return lp;
if (dep[lp] < dep[rp]) swap(lp, rp);
while (dep[lp] > dep[rp]) lp = fa[lp][l2g[dep[lp] - dep[rp]] - 1];
if (lp == rp) return lp;
for (int k = l2g[dep[lp]] - 1; k >= 0; k--)
if (fa[lp][k] != fa[rp][k]) lp = fa[lp][k], rp = fa[rp][k];
return fa[lp][0];
}
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0); cout.tie(0);
cin >> n >> m; indata::getlog2();
for (int i = 1; i <= n; ++i) cin >> v[i];
indata::lsh(); tree::in_tree(); tree::dfs(1, 0);
//for (int i = 1; i <= mque::tot; ++i) cerr << olq[i] << " "; cerr << endl;
mque::inque(); mque::sz = ceil(sqrt(2 * n));
sort(q + 1, q + m + 1, mque::cmp);
mque::solve(); for (int i = 1; i <= m; ++i) cout << ans[i] << endl;
return 0;
}
```
## 笛卡尔树
笛卡尔树是一种二叉树,每一个节点由一个键值二元组 $(k,w)$ 构成。要求 $k$ 满足二叉搜索树的性质,而 $w$ 满足堆的性质。一般我们会需要构造一个笛卡尔树,编号为 $i$ 的点权值为 $(i,a_i)$,$a_i$ 为给定的值。一般用栈解决。方法如下:
我们先按照下标顺序依次加入这棵树中,显然,为了维护二叉搜索树的性质,这个节点势必会在树的右链上。
这时候我们维护其堆的性质就行了。从下往上比较右链节点与当前节点 $u$ 的 $w$,如果找到了一个右链上的节点 $x$ 满足 $w_x<w_u$,就把 $u$ 接到 $x$ 的右儿子上,而 $x$ 原本的右子树就变成 $u$ 的左子树。
复杂度线性。可能视情况会需要树上 $DP$,四毛子等。
## 树套树
首先给出警告:树套树时空常数大,代码复杂,一定要静下来调,线段树中不要记录当前节点的区间端点,在函数中下传!
其实修正一个对树套树的认知错误:树套树实际上只有最内层在维护实际有效信息,外层只是为了减少内层维护次数,从而降低复杂度,而不做信息的合并。
在这基础之上,就不容易出错了。主要补充一些技巧。其中第二个板块有线段树套平衡树的参考代码。接下来讲一下相对好写而且支持面较广的树状数组套线段树。
###### 这里有你没写完的东西,杂鱼...
### 线段树二分/树状数组倍增
前者就是线段树上二分。因为线段树是分治型结构,所以复杂度单 $\log$。方法就是在每一个节点选择往左/右子树走。
后者如其名,因为树状数组是倍增型结构,所以复杂度单 $\log$。方法就是跳 $2^n$ 个,$n$ 越来越小。这时候,前面的贡献不会被重复统计,达到效果。
### 多树二分
不难注意到,在树套树[模板题](https://www.luogu.com.cn/problem/P3380)中,我给出了如下代码:
```cpp
#include<bits/stdc++.h>
using namespace std; using cir = const int&;
inline int read() {
int r = 0; char c = getchar();
while (c < '0' || c>'9') c = getchar();
while (c >= '0' && c <= '9') r = r * 10 + (c ^ 48), c = getchar();
return r;
}
inline void write(int x) {
if (x > 9) write(x / 10);
putchar(x % 10 ^ 48);
return;
}
inline void writi(int args) {
if (args < 0) args = ~args + 1, putchar('-');
write(args); putchar(10);
}
int n, m, v[50005], o, l, r, k;
struct bal_node {
int v, sz, rv, lc, rc;
}re[10000005]; int cnt;
//inline int max(cir l, cir r) { return l > r ? l : r; }
//inline int min(cir l, cir r) { return l < r ? l : r; }
class bal_tree {
int rt, r1, r2, r3;
inline void pup(cir p) {
re[p].sz = re[re[p].lc].sz + re[re[p].rc].sz + 1;
}
inline void blyat(int p, int v, int& l, int& r) {
if (!p) { l = r = 0; return; }
if (re[p].v > v) r = p, blyat(re[p].lc, v, l, re[p].lc);
else l = p, blyat(re[p].rc, v, re[p].rc, r);
pup(p); return;
}
inline int merge(int l, int r) {
if (!l || !r) return l | r;
if (re[l].rv < re[r].rv) {
re[l].rc = merge(re[l].rc, r);
pup(l); return l;
}
else {
re[r].lc = merge(l, re[r].lc);
pup(r); return r;
}
}
public:
inline int newn(cir v) {
++cnt; re[cnt].rv = rand(); re[cnt].sz = 1; re[cnt].v = v;
return cnt;
}
inline void ins(cir vl) {
blyat(rt, vl, r1, r2); rt = merge(r1, merge(newn(vl), r2));
}
inline void del(cir vl) {
blyat(rt, vl, r1, r3);
blyat(r1, vl - 1, r1, r2);
r2 = merge(re[r2].lc, re[r2].rc);
rt = merge(merge(r1, r2), r3);
}
inline void build(cir l, cir r) {
for (int i = l; i <= r; ++i) ins(v[i]);
}
inline int getrk(cir vl) {
blyat(rt, vl - 1, r1, r2);
int ans = re[r1].sz + 1;
rt = merge(r1, r2);
return ans;
}
inline int fndrk(cir p, cir rk) {
if (rk <= re[re[p].lc].sz) return fndrk(re[p].lc, rk);
if (rk == re[re[p].lc].sz + 1) return re[p].v;
return fndrk(re[p].rc, rk - re[re[p].lc].sz - 1);
}
inline int prev(cir vl) {
blyat(rt, vl - 1, r1, r2); int ans;
if (re[r1].sz) ans = fndrk(r1, re[r1].sz);
else ans = -INT_MAX; rt = merge(r1, r2);
return ans;
}
inline int next(cir vl) {
blyat(rt, vl, r1, r2); int ans;
if (re[r2].sz) ans = fndrk(r2, 1);
else ans = INT_MAX; rt = merge(r1, r2);
return ans;
}
}bt[50005 << 2];
#define mid (l + r >> 1)
struct bal_seg_tree {
inline void build(cir l, cir r, cir p) {
bt[p].build(l, r); if (l == r) return;
build(l, mid, p << 1); build(mid + 1, r, p << 1 | 1);
}
inline int getrk(cir l, cir r, cir p, cir sl, cir sr, cir vl) {
if (sl <= l && r <= sr) return bt[p].getrk(vl) - 1;
int ret = 0;
if (sl <= mid) ret += getrk(l, mid, p << 1, sl, sr, vl);
if (sr > mid) ret += getrk(mid + 1, r, p << 1 | 1, sl, sr, vl);
return ret;
}
inline int fndrk(cir l, cir r, cir rk) {
int lp = 0, rp = 1e8, mv, ans = -1;
while (lp <= rp)
if (getrk(1, n, 1, l, r, (mv = lp + rp >> 1)) < rk) ans = mv, lp = mv + 1;
else rp = mv - 1;
return ans;
}
inline void chg(cir l, cir r, cir p, cir cp, cir cv) {
bt[p].del(v[cp]); bt[p].ins(cv);
if (l != r)
if (cp <= mid) chg(l, mid, p << 1, cp, cv);
else chg(mid + 1, r, p << 1 | 1, cp, cv);
}
inline int prev(cir l, cir r, cir p, cir sl, cir sr, cir vl) {
if (r < sl || sr < l) return -INT_MAX;
if (sl <= l && r <= sr) return bt[p].prev(vl);
return max(prev(l, mid, p << 1, sl, sr, vl), prev(mid + 1, r, p << 1 | 1, sl, sr, vl));
}
inline int next(cir l, cir r, cir p, cir sl, cir sr, cir vl) {
if (r < sl || sr < l) return INT_MAX;
if (sl <= l && r <= sr) return bt[p].next(vl);
return min(next(l, mid, p << 1, sl, sr, vl), next(mid + 1, r, p << 1 | 1, sl, sr, vl));
}
}bst;
map<tuple<int, int, int>, int>ans;
signed main() {
n = read(); m = read(); srand((unsigned)time(0));
for (int i = 1; i <= n; ++i) v[i] = read();
bst.build(1, n, 1);
while (m--)
if (o = read(), o == 1)
l = read(), r = read(), k = read(),
writi(bst.getrk(1, n, 1, l, r, k) + 1);
else if (o == 2) {
l = read(), r = read(), k = read();
if (ans.count(make_tuple(l, r, k)))
writi(ans[make_tuple(l, r, k)]);
else writi(ans[make_tuple(l, r, k)] = bst.fndrk(l, r, k));
}
else if (o == 3)
l = read(), r = read(),
bst.chg(1, n, 1, l, r),
v[l] = r, ans.clear();
else if (o == 4)
l = read(), r = read(), k = read(),
writi(bst.prev(1, n, 1, l, r, k));
else
l = read(), r = read(), k = read(),
writi(bst.next(1, n, 1, l, r, k));
}
```
那么请看第 $135$ 到 $137$ 行,这一部分就是为了防被卡。仔细看会发现这个操作是 $O(\log^3n)$ 的。这时候就需要多树二分了。
多树二分,一句话说,就是将会涉及到的线段树树上的节点给全部放一起,然后一起二分。这时候,节点个数是 $\log$ 级别,二分是 $\log$ 的,整体双 $\log$。以 lby 的代码作为实现思路:
```cpp
inline int getkth(int l,int r,int k){
id.clear();
find(l,r);//找到树
int x=0,y=1e8;
vector<node*>pt;
for(int i=0;i<id.size();i++) pt.push_back(t[id[i]].root);//提出树根
if(k==0) return -2147483647;//特判边界
if(r-l+1<k) return 2147483647;
while(x!=y){//线段树二分
int sum=0;
for(int i=0;i<id.size();i++) sum+=pt[i]->l->val;
int mid=x+y>>1;
if(k>sum){
k-=sum,x=mid+1;
for(int i=0;i<id.size();i++) pt[i]=pt[i]->r;
}
else{
y=mid;
for(int i=0;i<id.size();i++) pt[i]=pt[i]->l;
}
}
return x;
}
```
## 严格次小生成树
还挺简单的,能直接口胡出思路来,就是建出最小生成树,然后在上面换边。只涉及到了倍增和最小生成树相关的。给出相对简短的实现:
```cpp
#include<bits/stdc++.h>
using namespace std;
#define int long long
struct node {
int p, v;
node(int pi = 0, int vi = 0) :p(pi), v(vi) {};
}; vector<node>son[100005];
struct edge {
int l, r, v;
edge(int li = 0, int ri = 0, int vi = 0) :
l(li), r(ri), v(vi) {};
friend bool operator<(const edge& l, const edge& r) {
return l.v < r.v;
}
}et; vector<edge>e; bitset<300005>vis;
int n, m, f[100005], cn, mav[100005][18], nmv[100005][18], dep[100005], lg[100005], fa[100005][18], msz, ap;
inline int find(int p) {
return f[p] != p ? f[p] = find(f[p]) : p;
}
inline bool merge(int l, int r) {
l = find(l), r = find(r);
if (l == r) return 0;
f[l] = r; return 1;
}
inline void dfs(int p, int f, int v) {
dep[p] = dep[f] + 1; mav[p][0] = v; fa[p][0] = f;
for (int i = 1; i <= lg[dep[p]]; ++i) {
fa[p][i] = fa[fa[p][i - 1]][i - 1];
mav[p][i] = max(mav[p][i - 1], mav[fa[p][i - 1]][i - 1]);
if (mav[p][i - 1] == mav[fa[p][i - 1]][i - 1])
nmv[p][i] = max(nmv[p][i - 1], nmv[fa[p][i - 1]][i - 1]);
else nmv[p][i] = min(mav[p][i - 1], mav[fa[p][i - 1]][i - 1]);
}
for (const node& sp : son[p])
if (sp.p != f) dfs(sp.p, p, sp.v);
}
inline int getlca(int l, int r) {
if (dep[l] < dep[r]) swap(l, r);
for (int i = 17; i >= 0; i--)
if (dep[fa[l][i]] >= dep[r]) l = fa[l][i];
if (l == r) return l;
for (int i = 17; i >= 0; i--)
if (fa[l][i] != fa[r][i])
l = fa[l][i], r = fa[r][i];
return fa[l][0];
}
inline int getmv(int p, int d, int lim) {
int mit; mit = -1e9;
for (int i = 0; i <= 17; ++i)
if (d & (1ll << i)) {
if (mav[p][i] != lim) mit = max(mit, mav[p][i]);
else mit = max(mit, nmv[p][i]); p = fa[p][i];
}
return mit;
}
signed main() {
ios::sync_with_stdio(0); cin >> n >> m;
for (int i = 1, a, b, c; i <= m; ++i)
cin >> a >> b >> c,
e.emplace_back(edge(a, b, c));
for (int i = 1; i <= n; ++i)
f[i] = i, lg[i] = lg[i - 1] + (1ll << lg[i - 1] == i);
sort(e.begin(), e.end());
for (int i = 0; i != e.size(); ++i)
if (cn == n - 1) break;
else if (et = e[i], merge(et.l, et.r))
cn++, msz += et.v, vis[i] = 1,
son[et.l].emplace_back(node(et.r, et.v)),
son[et.r].emplace_back(node(et.l, et.v));
memset(nmv, 0xcf, sizeof nmv);
dfs(1, 0, 0); ap = 0x3f3f3f3f3f3f3f3f;
for (int i = 0; i != e.size(); ++i) {
if (vis[i]) continue; et = e[i];
if (et.l == et.r) continue; int lp = getlca(et.l, et.r);
int val = max(getmv(et.l, dep[et.l] - dep[lp], et.v), getmv(et.r, dep[et.r] - dep[lp], et.v));
if (val > -1e9) ap = min(ap, et.v - val);
}
cout << msz + ap << endl;
}
```
## 整体二分
正如其名字,我们将所有的询问放到一起来二分,这样可以节省中间重复的判断的时间。思路很简单,结合题目去想一下能不能高效维护就是了。
[例题](https://www.luogu.com.cn/problem/P3527)核心代码:
```cpp
inline void solve(const int& la, const int& ra, const int& lq, const int& rq) {
if (la == ra) {
for (int i = lq; i <= rq; ++i) ans[v[i].p] = la;
return;
}
int mid = la + ra >> 1, c1(0), c2(0);
for (int i = la; i <= mid; ++i)
ta.add(l[i], c[i]), ta.add(r[i] + 1, -c[i]);
for (int i = lq; i <= rq; ++i) {
int tv = 0;
for (int sp : son[v[i].p]) {
tv += ta.que(sp) + ta.que(sp + m);
if (tv >= v[i].v) break;
}
if (tv >= v[i].v) ql[++c1] = v[i];
else v[i].v -= tv, qr[++c2] = v[i];
}
for (int i = la; i <= mid; ++i)
ta.add(l[i], -c[i]), ta.add(r[i] + 1, c[i]);
for (int i = 1; i <= c1; ++i) v[lq + i - 1] = ql[i];
for (int i = 1; i <= c2; ++i) v[lq + i - 1 + c1] = qr[i];
solve(la, mid, lq, lq + c1 - 1);
solve(mid + 1, ra, lq + c1, rq);
}
```
只是题必须满足以下性质:
1. 询问的答案具有可二分性
2. 修改对判定答案的贡献互相独立,修改之间互不影响效果
3. 修改如果对判定答案有贡献,则贡献为一确定的与判定标准无关的值
4. 贡献满足交换律,结合律,具有可加性
5. 题目允许使用离线算法
## 陈丹琦分治
CDQ 分治其实更像是一种思想。CDQ 的经典例题处理的是三维偏序问题,即满足 $a_i<a_j,b_i<b_j,c_i<c_j$ 的整数对 $(i,j)$ 的个数。
这个东西,一看就可以 KDTree(大雾)。
显然不优,CDQ 可以做到 $O(n\log^2n)$。
核心思路就是先按照第一维排序,随后归并排第二维的序列。归并的时候,左部点仍然满足 $a$ 比右部点小。此时我们依次归并 $b$,当 $b$ 来自右部点是计算比该点 $c$ 值更小的已归并的数量之和,这可以用树状数组快速维护。
求解完成。[模板题](https://www.luogu.com.cn/problem/P3810)核心代码:
```cpp
void solve(int lp, int rp) {
if (lp >= rp) return; int mid = lp + rp >> 1;
solve(lp, mid); solve(mid + 1, rp);
for (int lt = lp, rt = mid + 1, ip = lp; ip <= rp; ++ip)
if (rt > rp || lt <= mid && v[lt].b <= v[rt].b) ta.ins(v[lt].c, v[lt].cnt), tmp[ip] = v[lt++];
else v[rt].ret += ta.que(v[rt].c), tmp[ip] = v[rt++];
for (int i = lp; i <= mid; ++i) ta.ins(v[i].c, -v[i].cnt);
for (int i = lp; i <= rp; ++i) v[i] = tmp[i];
}
```
可以求解类似[动态逆序对](https://www.luogu.com.cn/problem/P3157),[二维数点](https://www.luogu.com.cn/problem/P2163)等的部分问题。
但是这只是非常狭义的 CDQ 分治。我们现在要去研究其核心思想,也就是对于更广的一类题目,我们到底怎么处理:
从上述过程中,我们可以窥见 CDQ 的核心思路。假设现在我们要求出 $[l,r]$ 的贡献,那么我们将其分成两半 $[l,mid]$ 和 $[mid+1,r]$,然后统计 $[l,mid]$ 对 $[mid+1,r]$ 的贡献。
事实上,中间贡献的计算不一定是像三位偏序那样的简单的数据结构,它可以是线段树,平衡树,kd-tree,甚至是另一层 CDQ 分治!
一个典型的例题是[四维偏序](https://qoj.ac/problem/21566),但是我们换一个略有挑战性的[TATT](https://www.luogu.com.cn/problem/P3769)进行讲解。
在经典的三维偏序中,我们每一次二分的时候可以视为将左区间的 $(x,y,z)$ 拍扁成了 $(0,y,z)$,右区间的拍扁成了 $(1,y,z)$。在保证 $y_l<y_r$ 的前提下,只有 $(0,y,z)$ 能对 $(1,y,z)$ 产生贡献。
在四维偏序中,我们可以使用类似的思路:我们在第一层将 $(a,b,c,d)$ 拍扁成 $(0/1,b,c,d)$,然后在第二层将他进一步拍扁成 $(0/1,0/1,c,d)$,然后只统计当 $c_l<c_r$ 时 $(0,0,c,d)$ 对 $(1,1,c,d)$ 的贡献。仍然使用树状数组。
下面给出[TATT](https://www.luogu.com.cn/problem/P3769)中的 CDQ 部分的参考代码:
```cpp
inline void cdq_in(int l, int r) {
if (l == r) return; int mid = l + r >> 1, lp = l;
cdq_in(l, mid);
sort(q + l, q + mid + 1, cmp<2>());
sort(q + mid + 1, q + r + 1, cmp<2>());
//cdq_in 外保证 [l,mid].b<[mid+1,r].b,现在按照 c 合并,按照 d 统计贡献
for (int i = mid + 1; i <= r; ++i) {
while (lp <= mid && q[lp].v[2] <= q[i].v[2]) {
if (q[lp].t) bit.ins(q[lp].v[3], q[lp].ans);
lp++;
}
if (!q[i].t) tmax(q[i].ans, bit.que(q[i].v[3]) + q[i].c);
}
//统计完恢复案发现场
for (int i = l; i != lp; ++i) if (q[i].t) bit.cls(q[i].v[3]);
for (int i = l; i <= r; ++i) tmp[p2[q[i].p]] = q[i];
for (int i = l; i <= r; ++i) q[i] = tmp[i];
cdq_in(mid + 1, r);
}
inline void cdq_out(int l, int r) {
if (l == r) return; int mid = l + r >> 1;
cdq_out(l, mid);
for (int i = l; i <= mid; ++i) q[i].t = 1;
for (int i = mid + 1; i <= r; ++i) q[i].t = 0;
sort(q + l, q + r + 1, cmp<1>());
for (int i = l; i <= r; ++i) p2[q[i].p] = i;
//cdq_out 外保证 [l,mid].a<[mid+1,r].a,现在按照 b 合并,不统计贡献
cdq_in(l, r);
for (int i = l; i <= r; ++i) tmp[q[i].p] = q[i];
for (int i = l; i <= r; ++i) q[i] = tmp[i];
cdq_out(mid + 1, r);
}
```
## 重链剖分
重链剖分是树链剖分中最强大也最常用的一种。重链剖分是这样的:
对于每一个节点,我们选出他的一个儿子,满足以这个儿子为根的子树大小不比别的子节点小。我们称这个儿子为重儿子。其他的我们称为轻儿子。连接重儿子和父节点的边称为重边,其余的称为轻边。这时候,一个极长的只由重边构成的链称为重链。显然一棵树会被剖分成许多的重链。
随后我们使用数据结构对重链进行维护。一种常见的做法是使用线段树。不过这要求链上的节点的编号是连续的。我们按照优先遍历重儿子的方式对整棵树上的节点重新标号为其 dfs 序。这时候同一重链上的节点的编号连续,同一子树内的结点的编号连续,因此我们可以快速维护部分对路径或子树进行修改或者查询的操作。
有点抽象,还是举个例子。比如[模板题](https://www.luogu.com.cn/problem/P3384),他要求维护子树加,子树求和,路径加,路径求和。确实模板,我们主要说一下路径的维护方式。
树上的任意一条路径本质上都是一堆重链的部分被一些轻边串了起来,同时也是 $l\to\operatorname{lca}(l,r)$ 和 $r\to\operatorname{lca}(l,r)$ 串起来。因此,我们可以考虑通过不停的跳重链的方式维护路径信息。
具体的,如果 $l,r$ 还不在同一条重链上,我们就选择**链顶**深度最大的那个节点去跳,先合并链顶到那个节点的信息,然后让那个节点跳到链顶的父节点。当 $l,r$ 到了同一个重链上之后,我们就可以直接合并 $l\to r$ 的信息。
代码其实挺简单的,但是我们还没有证明时间复杂度。
我们发现一个性质:我们每跳一次轻边,以当前节点为根的子树大小至少能够 $\times 2$,因为有重儿子压着你的嘛。也就是说,一个点只要是在向上跳,那就至多只能够跳 $\log_2^n$ 次。跳到 $\operatorname{lca}$ 上其实也是同理的。
所以单次操作时间复杂度就是 $\log^2n$ 的。核心代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
#define int long long
vector<int>son[100005];
int n, m, s, mod, v[100005];
int sz[100005], hs[100005], idc, f[100005];
inline void spl_lnk(int p, int fa) {
for (int sp : son[p])
if (sp != fa)
spl_lnk(sp, p), sz[p] += sz[sp],
(sz[sp] > sz[hs[p]]) && (hs[p] = sp);
sz[p]++; f[p] = fa;
}
int lnk[100005], nid[100005], nv[100005], d[100005];
inline void down_he(int p, int t) {
lnk[p] = t; nid[p] = ++idc; nv[idc] = v[p]; d[p] = d[f[p]] + 1;
if (!hs[p]) return; down_he(hs[p], t);
for (int sp : son[p]) if (!lnk[sp]) down_he(sp, sp);
}
struct seg_tree {
struct node { int l, r, v, t; }re[100005 << 2];
inline int sz(int p) { ... }
inline void pup(int p) { ... }
inline void pud(int p) { ... }
inline void build(int l, int r, int p) { ... }
inline void ins(int l, int r, int v, int p) { ... }
inline int que(int l, int r, int p) { ... }
}sgt;
inline void lins(int l, int r, int v) {
while (lnk[l] != lnk[r]) {
if (d[lnk[l]] < d[lnk[r]]) swap(l, r);
sgt.ins(nid[lnk[l]], nid[l], v, 1); l = f[lnk[l]];
}
if (d[l] > d[r]) swap(l, r);
sgt.ins(nid[l], nid[r], v, 1);
}
inline int lque(int l, int r) {
int ret = 0;
while (lnk[l] != lnk[r]) {
if (d[lnk[l]] < d[lnk[r]]) swap(l, r);
ret += sgt.que(nid[lnk[l]], nid[l], 1); l = f[lnk[l]];
}
if (d[l] > d[r]) swap(l, r);
ret += sgt.que(nid[l], nid[r], 1);
return ret % mod;
}
signed main() {
ios::sync_with_stdio(0);
cin >> n >> m >> s >> mod;
for (int i = 1; i <= n; ++i) cin >> v[i];
for (int i = 1, l, r; i != n; ++i)
cin >> l >> r,
son[l].emplace_back(r),
son[r].emplace_back(l);
spl_lnk(s, 0); down_he(s, s); sgt.build(1, n, 1);
for (int i = 1, o, l, r, v; i <= m; ++i)
if (cin >> o >> l, o == 1) cin >> r >> v, lins(l, r, v);
else if (o == 2) cin >> r, cout << lque(l, r) << endl;
else if (o == 3) cin >> r, sgt.ins(nid[l], nid[l] + sz[l] - 1, r, 1);
else cout << sgt.que(nid[l], nid[l] + sz[l] - 1, 1) << endl;
}
```
## 长链剖分
虽然和重链剖分一样都是树链剖分的一种,但是面对的主要问题却很不一样。长链剖分主要是解决一些和深度相关的 DP 问题。长链剖分是这样的:
定义长子节点表示其子节点中子树深度最大的子结点。定义短子节点表示剩余的子结点。从这个结点到长子节点的边为长边。到其他轻子节点的边为短边。若干条首尾衔接的长边构成长链。
它本身并不是很适合维护链修改操作,毕竟他最多会跳 $O(\sqrt n)$ 次短边,远远劣于重链剖分。但是对于深度相关的 DP 问题却有着很大的优化。比如[这道题](https://www.luogu.com.cn/problem/CF1009F):
DP 式子其实非常好想,难就难在转移。你可以通过线段树合并等等复杂的技巧去维护,但是这是不必要的,我们可以用长链剖分用简短的代码做到线性复杂度。
具体的来说,我们让一个节点直接继承长儿子的 DP 数组,并在前面插入一个数 $1$,表示在相对深度为 $0$ 的位置有且仅有一个节点,然后暴力合并所有短儿子的 DP 数组。做完了。
没错!做完了。我们分析一下时空复杂度。
首先对于每一个长链,我们仅在链顶的时候被暴力合并一次,而且显然有效的位置最多只会有其长度那么多个,因此合并的时间复杂度是 $O(n)$ 的。空间呢?我们发现我们可以通过指针预留空间的方式,让一整个链完全基于同一个数组进行修改,不同的链也可以通过相应的偏移给别的链预留足够的空间,从而空间也是线性的。
代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
vector<int>son[1000005];
int n, a[1000005], d[1000005], ls[1000005];
inline void spl_lnk(int p, int f) {
for (int sp : son[p]) if (sp != f)
spl_lnk(sp, p), (d[sp] > d[ls[p]]) && (ls[p] = sp);
d[p] = d[ls[p]] + 1;
}
int* v[1000005], * lp, ans[1000005];
inline void cmp(int* v, int& a, int b) {
if (v[a]<v[b] || v[a] == v[b] && a>b) a = b;
}
inline void dps(int p, int f) {
v[p][0] = 1; ans[p] = 0;
if (!ls[p]) return; v[ls[p]] = v[p] + 1;
dps(ls[p], p); ans[p] = ans[ls[p]] + 1;
for (int sp : son[p])
if (sp != f && sp != ls[p]) {
v[sp] = lp; lp += d[sp];
dps(sp, p);
for (int i = 1; i <= d[sp]; ++i)
v[p][i] += v[sp][i - 1], cmp(v[p], ans[p], i);
}
cmp(v[p], ans[p], 0);
}
signed main() {
ios::sync_with_stdio(0); cin >> n;
for (int i = 1, l, r; i != n; ++i)
cin >> l >> r,
son[l].emplace_back(r),
son[r].emplace_back(l);
spl_lnk(1, 0); v[1] = lp = a; lp += d[1]; dps(1, 0);
for (int i = 1; i <= n; ++i) cout << ans[i] << endl;
}
```
有的时候不得不佩服一下发明这种简洁美丽的算法的人。这才是数据结构的美之所在。
## 李超线段树
要求在平面直角坐标系下维护两个操作:
1. 在平面上加入一条线段。记第 $i$ 条被插入的线段的标号为 $i$。
2. 给定一个数 $k$,询问与直线 $x=k$ 相交的线段中,交点纵坐标最大的线段的编号。
我们发现,传统的线段树无法很好地维护这样的信息。这种情况下,**李超线段树**便应运而生。
区间修改,最常见的办法就是给每个节点一个懒标记。对于每个区间,维护在 $m=\frac{l+r}{2}$ 处取值最大的直线的信息。
现在我们需要插入一条线段 $f$,在这条线段完整覆盖的线段树节点代表的区间中,某些区间的最优线段可能发生改变。
考虑某个被新线段 $f$ 完整覆盖的区间,若该区间无最优线段,则该线段可以直接成为最优线段。
否则,设该区间的中点为 $m$,我们拿新线段 $f$ 在中点处的值与原最优线段 $g$ 在中点处的值作比较。
如果新线段 $f$ 更优,则将 $f$ 和 $g$ 交换。那么现在考虑在中点处 $f$ 不如 $g$ 优的情况:
1. 若在左端点处 $f$ 更优,那么 $f$ 和 $g$ 必然在左半区间中产生了交点,递归到左儿子中进行插入;
2. 若在右端点处 $f$ 更优,那么 $f$ 和 $g$ 必然在右半区间中产生了交点,递归到右儿子中进行插入。
3. 若在左右端点处 $g$ 都更优,那么 $f$ 不可能成为答案,不需要继续下传。
由于仅有一个交点,所以两边子区间最多会递归一个。复杂度 $O(\log n)$。但是需要注意,因为每一次我们都需要对全覆盖的区间都进行修改,而这样的区间是 $\log$ 级别的,因此单次修改的复杂度为 $O(\log^2n)$。
查询 $x=k$ 答案时,从根走到 $[x,x]$ 节点记录的所有最优直线在 $x=k$ 时取值的答案极值即为所求。这里是运用了**标记永久化**的思想。查询的复杂度就为 $O(\log n)$。
特别需要注意,对于不优的三种情况的讨论中,如果二者在端点同样优,那么一定要视为 $g$ 更优。这样才能保证对于两个重复的线段不会一直走 $3$ 操作,从而导致时复错误。
核心代码如下:
```cpp
constexpr double eps = 1e-9;
inline int cmp(double l, double r) {
if (l > r + eps) return 1;
if (r > l + eps) return -1;
return 0;
}
inline double quep(int id, int x) {
return l[id].b + l[id].k * x;
}
inline void chg_intv(int nl, int nr, int cp, int p) {
int& lp = ans[p], mid = nl + nr >> 1;
int ty = cmp(quep(cp, mid), quep(lp, mid));
if (ty == 1 || !ty && cp < lp) swap(cp, lp);
int lcn = cmp(quep(cp, nl), quep(lp, nl)), rcn = cmp(quep(cp, nr), quep(lp, nr));
if (lcn == 1 || !lcn && cp < lp) chg_intv(nl, mid, cp, p << 1);
if (rcn == 1 || !rcn && cp < lp) chg_intv(mid + 1, nr, cp, p << 1 | 1);
}
inline void fnd_intv(int nl, int nr, int cl, int cr, int cp, int p) {
if (nl >= cl && nr <= cr) return chg_intv(nl, nr, cp, p);
int mid = nl + nr >> 1;
if (cl <= mid) fnd_intv(nl, mid, cl, cr, cp, p << 1);
if (cr > mid) fnd_intv(mid + 1, nr, cl, cr, cp, p << 1 | 1);
}
inline pode que(int nl, int nr, int cp, int p) {
if (nr<cp || nl>cp) return pode(0, 0);
int mid = nl + nr >> 1; double val = quep(ans[p], cp);
if (nl == nr) return pode(val, ans[p]);
return
max(pode(val, ans[p]),
que(nl, mid, cp, p << 1),
que(mid + 1, nr, cp, p << 1 | 1));
}
```
Q1:为什么一定要在路径上取 $\max$ 而不是一直走到底,返回最底部的状态?
标记永久化。
实际上,对于一条线段,他在中点最优常常意味着他在全局都是比较优的。尤其是对于第一次存入的区间。
也就是说,对于相当大的一部分线段,他其实是整个区间的子区间的最优解。但是如果真的更改整个子树,其复杂度退化为 $O(n)$。
所以说,与其更改整个子树,不如直接标记永久化,最后再在这些**可能的最大值**中刨出真正的最大值。
Q2:李超线段树合并细节?
其实不难想象,对于李超线段树这种有永久化标记的树,其合并方式不太一样。
不过,对于同一层,其实我们只需要将其中一个的最优线段合并到另一个当中,然后递归合并就行了。
特别需要注意一点,对于[【模板】李超树合并](https://www.luogu.com.cn/problem/CF932F),其时间复杂度实际上是 $O(n\log n)$ 的。这一点可用势能分析得出。参见第一篇题解,非常玄妙。连[官方题解](https://codeforces.com/blog/entry/57796)都分析错了。
典型应用:
1. 优化 DP,也就是动态维护斜率优化 DP 的凸包,支持任意地方插入。
2. 李超线段树合并,主要也是优化 DP,主要是在对于整个子树的最优信息的合并。
例题:[T0:P4097,省选/NOI-,模板题](https://www.luogu.com.cn/problem/P4097);[T1:P4254,省选/NOI-,模板题](https://www.luogu.com.cn/problem/P4254);[T2:P4655,省选/NOI-](https://www.luogu.com.cn/problem/P4655);[T3:CF932F,省选/NOI-](https://www.luogu.com.cn/problem/CF932F);[T4:P4069,省选/NOI-](https://www.luogu.com.cn/problem/P4069)。
## 动态树
动态树,顾名思义,这种树是动态的,可能删边或加边。$\text{LCT}$ 可以动态维护其中的路径信息,以[模板题](https://www.luogu.com.cn/problem/P3690)为例。
首先,你需要学会:文艺 $\text{splay}$ 树,实链剖分。
实链剖分?没见过。但是,我们可以管他叫乱链剖分,因为他确实是随便选一个儿子当成实儿子,其余的当成虚儿子。
这有什么用呢?他非常的灵活。不像重链或者长链一样改一个上面全得改。
剖分完了,然后呢?然后,我们将被一堆实边连到一起的树甩到文艺 $\text{Splay}$ 里面,构成一颗树。
那虚边怎么办?我们采用一种神奇的方法:认父不认子!我们正好满足了高效维护虚边和只向上移动的需求。
又因为我们有一堆的 $\text{Splay}$ 树,构成了一个森林,我们管这个森林叫做辅助树。一个辅助树对应原森林中的一棵树。
那辅助树需要满足什么性质呢?每一个 $\text{Splay}$ 的中序遍历满足按照深度排序。这样,我们就完成了原森林到辅助森林的转化。
接下来,$\text{Splay}$树中都有哪些函数和变量呢?
```cpp
class splaytree {
int sn[sz][2], f[sz], v[sz], r[sz];
//sn(子节点),f(父节点),v(子树异或值),r(反转标记)
inline bool bs(int p);
inline void pup(int p);
inline bool nor(int p);
inline void swn(int p);
inline void pud(int p);
inline void ron(int p);
inline void rot(int p);
inline void splay(int p);
inline void access(int p);
inline void mkrt(int p);
inline int fnrt(int p);
inline void tlnk(int l, int r);
public:
inline void link(int l, int r);
inline int val(int l, int r);
inline void chg(int p, int v);
}re;
```
首先说最基础的 `pup`,`pud`,`rot` 和 `splay`。
`pup` 即 `pushup`,将子节点的信息上传上来。这里,我们需要维护每一个节点在 $\text{Splay}$ 中的子树中的所有结点的异或值。
`pud` 即 `pushdown`,将旋转标记下传,毕竟是文艺 $\text{Splay}$嘛。
`rot` 即 `rotate`,将一个节点向上旋转,$\text{Splay}$ 的基础操作。但是要做一定的修改。
首先,一定要严格判断父节点是不是当前 $\text{Splay}$树的树根。如果不是,一定不要让祖父认这个儿子,因为认父不认子只出现在虚边,而一颗 $\text{Splay}$ 维护的是实边树。
其次,一定要严格判断子节点是否存在,不要让 $0$ 有了父节点。
别的大致没有什么好说的,注意先 `pup(fp)` 再 `pup(p)`,因为这时候 $fp$ 已经成为 $p$ 的子节点了。
`splay` 就是你想的那个函数,但是因为在 $\text{LCT}$ 中只涉及到了将一个点转到当前 $\text{Splay}$ 树的根节点这一种操作,所以省略掉了第二个参数。
然后说一下 $\text{LCT}$ 特有的函数。
`nor` 即 `not_root`,判断一个节点是不是当前 $\text{Splay}$ 的根节点。判断方式很简单,看他是不是父亲的儿子,因为认父不认子。
`access` 是 $\text{LCT}$ 的核心操作,它会将 $p$ 在原树中到根节点的链变为实链。可是我们不是不维护原树吗?
其实我们仔细想一下,因为他们在同一个实链当中,所以他们在 `access` 完了之后只会在同一颗 $\text{Splay}$ 中。所以我们只需要将路径上的 $\text{Splay}$ 间的边设为实边就行了。
具体的,我们不停地将当前节点旋到树根,让父亲认这个儿子(原先的儿子因为认父不认子而自动降为了虚儿子)为右儿子(中序遍历满足深度递增),再将节点跳到父亲上就完了。
`swn` 即 `swap_node`,即将这个节点区间反转。
`ron` 即 `rotate_node`,将这个点到根节点的区间反转标记下传。
`mkrt` 即 `make_root`,将这个节点设为原树的根。也很简单,打通他和根节点之间的路径(`access`),旋到树根,区间反转。
为什么区间反转呢?中序遍历按深度递增。反转之前他只会是整个 $\text{Splay}$ 中最下的节点,旋到树根后所有节点都在他的左子树,区间反转一下它就成为最低的节点,也就是根节点了。
`fnrt` 即 `find_root`,找他在原树中的根。我们只需要 `access`,`splay`,然后边下传标记边向左子树走,最靠边的就是根节点。
`tlnk` 即 `to_link`,就是用一颗 $\text{Splay}$ 树专门来维护 $l,r$ 之间的链。显然我们只需要 `mkrt(l)`,`access(r)` 之后 `splay(r)` 就行了。
`link` 就是 $\text{LCT}$ 中 $L$ 对应的操作。他就是连接一条 $l,r$ 的边。我们只需要让 $l$ 成为原树树根,然后 $fa[l]=r$ 就行了。
`cut` 就是 $\text{LCT}$ 中 $C$ 对应的操作。他就是断开 $l,r$ 的边。我们只需要让 $l$ 成为原树的根,将 $r$ 转到 $l$ 边上,不认父不认子就完了。
剩下的两个就是对题的函数了,不用管他。
代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
constexpr int sz = 1e5 + 5;
int n, m, t[sz];
class tree {
//变量:sn(子节点),f(父节点),v(子树异或值),r(反转标记)
int sn[sz][2], f[sz], v[sz], r[sz];
//是不是右儿子
inline bool bs(int p) { return sn[f[p]][1] == p; }
//更新答案(v)
inline void pup(int p) { v[p] = v[sn[p][1]] ^ v[sn[p][0]] ^ t[p]; }
//not - root = nor
inline bool nor(int p) { return sn[f[p]][0] == p || sn[f[p]][1] == p; }
//swn:swap - node = swn
inline void swn(int p) { swap(sn[p][0], sn[p][1]), r[p] ^= 1; }
//pud:下传反转标记
inline void pud(int p) {
if (r[p]) {
if (sn[p][0]) swn(sn[p][0]);
if (sn[p][1]) swn(sn[p][1]);
r[p] = 0;
}
}
//ron:rotate - node(实际上是下传了到链顶的标记)
inline void ron(int p) {
if (nor(p)) ron(f[p]); pud(p);
}
/*
rot:最根本的旋转操作,但是和普通的 splay 有区别
1. 要判断 f[p] 是不是当前 splay 的根,不是才能更新 f[f[p]] 的子节点信息
2. 要判断 sn[p][...] 的存在性,存在才更新 f[sn[p][...]],否则 f[0] 会被改
*/
inline void rot(int p) {
int fp = f[p], pp = f[fp];
bool t = bs(p); int sp = sn[p][!t];
if (nor(fp)) sn[pp][bs(fp)] = p;
sn[p][!t] = fp; sn[fp][t] = sp;
if (sp) f[sp] = fp;
f[fp] = p; f[p] = pp;
pup(fp); pup(p);
}
/*
splay:最基本的操作,但是也有不同,更像文艺 splay
要下传从 splay 树的树根开始的反转懒标记,但是只反转这条链的。
*/
inline void splay(int p) {
ron(p);
while (nor(p)) {
int fp = f[p], pp = f[fp];
if (nor(fp)) rot((sn[fp][0] == p) ^ (sn[pp][0] == fp) ? p : fp);
rot(p);
}
}
/*
access:LCT 的根本操作
作用:在原树中将 p 到“树根”的边置为实边
方式:
1. 将 p 转到当前 splay 树的根
2. p 作为父亲认前一个节点 ap 互认父子
3. 更新 p 点答案,p 跃到其父节点上。
4. 循环直至 p 变为 0 (虚无令使)。
解释:如果 2 中 p 有右节点,那么置右节点只会将原有的一条实边变为虚边。
这时候,因为认父不认子,修边完成。
*/
inline void access(int p) {
for (int ap = 0; p; p = f[ap = p])
splay(p), sn[p][1] = ap, pup(p);
}
/*
mkrt:make_root
作用:将 p 变为原树的根节点
方式:打通路径,旋至顶点,交换儿子
交换儿子干了什么呢?
access 会使他成为 splay 树中最深的节点。
上去了之后他会成为中序最后,但是交换完左右就成为中序最前了。
根据其特殊性质,他变相地成为了原树的根节点。
*/
inline void mkrt(int p) { access(p); splay(p); swn(p); }
/*
fnrt:find_root
作用:找这个原树的根节点
方式:打通路径,旋至顶点,走左子树,重新旋顶,返回答案。
*/
inline int fnrt(int p) {
access(p); splay(p);
while (pud(p), sn[p][0]) p = sn[p][0];
splay(p); return p;
}
/*
tlnk:to_link
作用:将两个点的路径提取为一个 splay
方式:提为树根,打通路径,旋至树顶
access 链底,mkrt 必为链顶。
*/
inline void tlnk(int l, int r) { mkrt(l); access(r); splay(r); }
public:
//连接边:先作为根,判断不同树后单向认父(虚边)即可。
inline void link(int l, int r) {
if (mkrt(l), fnrt(r) != l) f[l] = r;
}
//断开边:先作为根,判断有边后双向断边即可。
inline void cut(int l, int r) {
if (mkrt(l), fnrt(r) == l && f[r] == l && !sn[r][0])
f[r] = sn[l][1] = 0, pup(l);
}
//其余针对题目的支持函数:查询路径&&修改点权
inline int val(int l, int r) { return tlnk(l, r), v[r]; }
inline void chg(int p, int v) { splay(p); t[p] = v; pup(p); }
}re;
int main() {
ios::sync_with_stdio(0); cin >> n >> m;
for (int i = 1; i <= n; ++i) cin >> t[i];
for (int i = 1, o, l, r; i <= m; ++i)
if (cin >> o >> l >> r, !o) cout << re.val(l, r) << endl;
else if (o == 1) re.link(l, r);
else if (o == 2) re.cut(l, r);
else re.chg(l, r);
}
//私は猫です
```
## 快速傅里叶变换
快速傅里叶变换还是太超模了。FFT 可以在 $O(n\log n)$ 的时间复杂度内解决两个次数不高于 $n$ 次的多项式的卷积。
首先,多项式最直观的表示方式是系数表示,但是 FFT 转而使用点值表示。对于一个 $n$ 次多项式,可由 $n+1$ 或更多个不同点的位置确定。这一点在此不作证明。
接下来,我们假定我们有两个 $n$ 次的多项式 $f_1(x)$ 和 $f_2(x),g(x)=f_1(x)\times f_2(x)$,那么假设我们算出了 $2\times n+1$ 个点的值,分别为 $(x_0,f_1(x_0)),(x_1,f_1(x_1)),\dots,(x_{2\times n},f_1(x_{2\times n}))$ 和 $(x_0,f_2(x_0)),(x_1,f_2(x_1)),\dots,(x_{2\times n},f_2(x_{2\times n}))$,那么 $g(x)$ 必过 $(x_0,f_1(x_0)\times f_2(x_0)),(x_1,f_1(x_1)\times f_2(x_1)),\dots,(x_{2\times n},f_1(x_{2\times n})\times f_2(x_{2\times n}))$。
就是这么一坨东西。显然,我们如果能够快速的在点值和多项式之间转化,那么我们就能够快速的求出两个多项式的卷积。问题就在于我们如何在二者之间快速转化。
神奇的地方就在于此。让我们做一个小小的变化。假设 $F_o(x)$ 表示 $F$ 中 $x$ 的偶数次方项之和,$F_e(x)$ 表示 $F$ 中 $x$ 的奇数次方项提出 $x$ 的公因数之后的式子,那么不难发现,$F_o,F_e$ 都只剩偶数次方项了。
这有什么呢?不难注意到,$F(x)=F_o(x)+xF_e(x),F(-x)=F_o(x)-xF_e(x)$。初现端倪,我们递归此过程的话,是不是就可以做到 $O(n\log n)$ 了呢?
似乎并没有,接下来你在求 $F_o(x)$ 的时候,你无法再使用正负点对来加速了,毕竟 $x$ 的平方一定是恒正的......吗?
不一定是啊!你回忆了一下你不知道学没学过的复数,想到单位根正好满足这个要求。
最底层的时候我们求最底下的那个多项式(其实已经只剩单项式了)在 $x=\omega_x=\cos\frac{2\pi\times x}{n+1}+i\sin\frac{2\pi\times x}{n+1}$,其中 $x$ 取值范围为 $[0,n]$。
那么你再观察一下,当 $x^\prime=x^2$ 的时候,$\omega_x^2=\omega_{x+\frac{n+1}{2}}^2$。也就是说,只要我们能让 $n$ 是一个形如 $2^k-1$ 的数,我们就能一直将这个过程进行下去。
那很显然,不足的位我们直接补 $0$ 就完事了。
于是我们成功地将多项式在 $n\log n$ 的复杂度内变为了点值表示。
那么,怎么从点值变回多项式呢?
我们这样来看:FFT 实际上是快速的求出了 $b_x=\sum_{i=0}^na_i\times \omega_{ix}$。那么经过一些神奇的推导,我们很难发现:$a_x=\frac{1}{n+1}\sum_{i=0}^nb_i\omega_{-ix}$。这一点可以通过直接的数论推导或者 FFT 中各步骤对应的矩阵乘法形式通过逆矩阵证得。
此时你又定睛一看,发现如果你令 $\omega^\prime_{x}=\frac{\omega_{-x}}{n+1}$,那么 $a_x=\sum_{i=0}^nb_i\times \omega^\prime_{ix}$,FFT 不就能求了吗?
因此,我们求出了两个多项式的卷积,复杂度 $O(n\log n)$。
更多优化与应用在 NTT 讲。
## 快速数论变换
也算是为数不多的几个完全不需要掌握其所以然的算法了。可以从 FFT 那里变过来。
NTT 本质上就干了一件事:把复数映射到了整数集上,然后接着干。
怎么映射呢?原根。对于质数 $p=qn+1$,且 $n=2^m$,那么原根 $g$ 满足 $g^{qn}\equiv1\pmod p$。此时我们可以将 $g_n=g^q\pmod p$ 看作 $\omega_n$ 的等价。
说白了,在模 $p$ 意义下可以认为 $g\equiv e^{\frac{2\pi}{q}}$。常见的 $(p,g)$ 有 $(167772161,3),(998244353,3),(1004535809,3)$。
所以你只需要把代码中对应的那些位置替换一下就行了。
### 若干优化
逐步看。这是 FFT 比较劣的一个版本,模板题要跑 2.77s。
```cpp
using cpx = complex<double>;
int n, m, lim, rev; const double pi2 = acos(-1) * 2;
inline void fft(const int& lim, vector<cpx>& v) {
if (lim == 1) return;
vector<cpx>vl(lim + 4 >> 1), vr(lim + 4 >> 1);
for (int i = 0; i <= lim; i += 2)
vl[i >> 1] = v[i], vr[i >> 1] = v[i + 1];
fft(lim >> 1, vl); fft(lim >> 1, vr);
cpx tm(cos(pi2 / lim), sin(pi2 / lim) * rev), tv(1, 0);
for (int i = 0; i != lim >> 1; ++i, tv *= tm)
v[i] = vl[i] + tv * vr[i],
v[i + (lim >> 1)] = vl[i] - tv * vr[i];
}
```
我们知道,复数的运算其实很耗时间,所以能少计算一次,尤其是乘法,会有一定的优化。所以我们将 `tv * vr[i]` 的结果存下来。这样就能优化到 2.65s。代码如下:
```cpp
using cpx = complex<double>;
int n, m, lim, rev; const double pi2 = acos(-1) * 2;
inline void fft(const int& lim, vector<cpx>& v) {
if (lim == 1) return;
vector<cpx>vl(lim + 4 >> 1), vr(lim + 4 >> 1);
for (int i = 0; i <= lim; i += 2)
vl[i >> 1] = v[i], vr[i >> 1] = v[i + 1];
fft(lim >> 1, vl); fft(lim >> 1, vr);
cpx tm(cos(pi2 / lim), sin(pi2 / lim) * rev), tv(1, 0), tmp;
for (int i = 0; i != lim >> 1; ++i, tv *= tm)
tmp = tv * vr[i], v[i] = vl[i] + tmp,
v[i + (lim >> 1)] = vl[i] - tmp;
}
```
这不是重点,接下来要介绍一下非递归版的 FFT。
我们在运行的时候会不停的涉及到交换位置,导致最后算出来的东西出现乱序,根本用不了。但是如果我们预先将这些位置预先换了,是不是就没有那么多问题了?
确实。不过一个悲催的问题是我没有搞懂他为什么是代码中的那个位置。所以死记吧。这样能直接优化到 1.65s。代码如下:
```cpp
inline void fft(vector<cpx>& v) {
for (int i = 0; i < lim; ++i)
if (i < sp[i]) swap(v[i], v[sp[i]]);
for (int ml = 1; ml < lim; ml <<= 1) {
tv = cpx(cos(pi / ml), sin(pi / ml) * rev);//因为是枚举一半的长度,所以不需要pi*2了。
for (int p = 0; p < lim; p += ml << 1) {
vl = cpx(1, 0);
for (int i = 0; i < ml; ++i, vl *= tv)
tmp = v[p + i + ml] * vl,
v[p + i + ml] = v[p + i] - tmp,
v[p + i] += tmp;
}
}
}
int main() {
n = read(); m = read();
vector<cpx>f(n + m + 1 << 1), g(n + m + 1 << 1);
for (int i = 0; i <= n; ++i) f[i] = cpx(read(), 0);
for (int i = 0; i <= m; ++i) g[i] = cpx(read(), 0);
lim = rev = 1; while (lim <= n + m) lim <<= 1, tl++;
for (int i = 0; i < lim; ++i)
sp[i] = (sp[i >> 1] >> 1) | ((i & 1) << (tl - 1));
fft(f); fft(g); rev = -1;
for (int i = 0; i <= lim; ++i) f[i] *= g[i];
fft(f);
for (int i = 0; i <= n + m; ++i)
writi(f[i].real() / lim + 0.5);
return 0;
}
```
### 应用
重要的是卷积形式。这又是什么呢?就是形如 $A(x)=\sum_{i=0}^xF(i)G(x-i)$ 的式子,其中 $F,G$ 均不与 $x$ 相关。显然从卷积的暴力计算方式来看,就不难发现 $F*G$ $x^n$ 对应的系数就是要求的 $A(n)$。
于是,只要你能化出卷积形式,就可以用 FFT/NTT 做掉了。典型例题有[第二STL行](https://www.luogu.com.cn/problem/P5395)。EG:
$$
\begin{aligned}
& \{_m^n\}\\
=&\frac{1}{m!}\sum_{i=1}^m(_i^m)(-1)^{m-i}i^n\\
=&\sum_{i=1}^m\frac{(_i^m)(-1)^{m-i}i^n}{m!}\\
=&\sum_{i=0}^m\frac{i^n}{i!}\times\frac{(-1)^{m-i}}{(m-i)!}
\end{aligned}
$$
所以就能得出核心代码如下:
```cpp
class prev_stl {
arr cp, a, b, ny; int jc, lim, tl, rev, tv, tmp;
inline void ntt(int* v) {
for (int i = 0;i < lim;++i)
if (i < cp[i]) swap(v[i], v[cp[i]]);
for (int ml = 1; ml < lim; ml <<= 1) {
tv = qpow(rev ? 3 : siv3, (mstl - 1) / ml / 2, mstl);
for (int p = 0; p < lim; p += ml << 1)
for (int i = 0, vl = 1; i < ml; ++i, vl = vl * tv % mstl)
tmp = v[p + i + ml] * vl % mstl,
v[p + i + ml] = (v[p + i] - tmp + mstl) % mstl,
v[p + i] = (v[p + i] + tmp) % mstl;
}
if (!rev) {
int inv = qpow(lim, mstl - 2, mstl);
for (int i = 0;i < lim;++i) v[i] = v[i] * inv % mstl;
}
}
public:
inline void init() {
for (int i = jc = 1;i <= k;++i) jc = jc * i % mstl;
ny[k] = qpow(jc, mstl - 2, mstl);
for (int i = k;i >= 1;i--) ny[i - 1] = ny[i] * i % mstl;
for (int i = 0;i <= k;++i)
a[i] = (i & 1) ? mstl - ny[i] : ny[i],
b[i] = qpow(i, k, mstl) * ny[i] % mstl;
lim = rev = 1; while (lim <= (k * 2)) lim <<= 1, tl++;
for (int i = 0; i < lim; ++i)
cp[i] = (cp[i >> 1] >> 1) | ((i & 1) << (tl - 1));
ntt(a); ntt(b);
for (int i = 0;i < lim;++i) a[i] = a[i] * b[i] % mstl;
rev = 0; ntt(a);
for (int i = k + 1;i < lim;++i) a[i] = 0;
}
inline int solve(int v) { return a[v]; }
}prs;
```
## prufer序列
这个也是相当的重要的。Prufer 序列可以实现无根树和值域为 $[1,n]$ 的长度为 $n-2$ 的整数序列之间的转化。
那么怎么转化的呢?先看第一种:树转 prufer。
每一次我都选择当前编号最小的叶子节点,将它的父节点的编号存到序列中,然后删掉这个节点,直到只剩下两个节点。
显然,用堆可以 $O(n\log n)$ 做。但是如果你仔细想一下就会发现,每删一个点最多再加上一个点。因此我可以顺序枚举点,如果能删就一直删,直到非叶子节点或者编号比初始位置大。时复 $O(n)$。
再看第二种:prufer 转树。
首先由于 prufer 序列的一个非常显然的性质:每个节点在序列中出现的次数就是其度数减一。所以我们每一次选择编号最小的度数为 $1$ 的节点与当前枚举到的 prufer 序列中的点连接起来,将二者的“剩余度数”减一。当 prufer 序列枚举完后就剩下了两个点,连起来就行。
但是由于和树转 prufer 类似的构造方式,显然仍然可以用类似的方式来线性构造。
有什么用呢?首先他明显证明了 Cayley 定理:$n$ 个节点的带标号的形态不同的无根树有 $n^{n−2}$ 个。
其次,按照 LZJ 所说,会有一些题要用这个序列和一些数据结构搓一下,但是似乎到现在为止他也没有给出相关例题,就先放着吧。
## 可并堆
### 斜堆
斜堆应该是非常好实现的一种可并堆。假设我们有 $n$ 个堆,每一个堆初始大小都是 $O(1)$ 的。
斜堆每次合并时先比较一下两个正在合并的堆的堆顶,视情况选取更小的那个堆,并将那个堆的左儿子/右儿子和另一个堆接着合并。随后直接交换左右儿子。非常潦草,但是操作均摊下来就是 $O(\log)$ 的。感性证明不难,不会严格证明,想了解的[看这里](https://www.luogu.com.cn/article/5bxl56nu)。模板二代码如下:
```cpp
class m_incline_heap {
struct node {
int f, s[2], v;
}re[1000005];
inline int merge(int l, int r) {
if (!l || !r) return l | r;
if (re[l].v > re[r].v) swap(l, r);
re[re[l].s[1] = merge(re[l].s[1], r)].f = l;
swap(re[l].s[0], re[l].s[1]);
return l;
}//合并操作
public:
inline void chg(int& r, int p, int v) {
int f = re[p].f;
if (f) re[f].s[re[f].s[0] != p] = re[p].f = 0;
else r = re[p].f = 0; //断开与父节点的边
re[p].v = v; //改权值
r = merge(r, p); //合并回去
}//修改操作
inline void init() {
for (int i = 1;i <= n;++i)
cin >> re[i].v, rt[i] = i;
}
inline void del(int h, int p) {
chg(rt[h], p, INT_MIN); //设置要删除的节点权值极小,也就是置于堆顶
re[rt[h] = merge(re[rt[h]].s[0], re[rt[h]].s[1])].f = 0; //删除堆顶
}//从堆 h 中删去元素 p
inline int top(int h)const { return re[rt[h]].v; }
inline void merh(int l, int r) {
re[rt[l] = merge(rt[l], rt[r])].f = 0;
}//合并两个堆
}mih;
```
### 随机堆
更潦草了,直接在合并的时候随机向左子树或者右子树合并,期望树高是 $O(\log)$ 的,对吧?
### 左偏树
这个稍微科学一点。我们定义一个节点的 $dist$ 为其到子树中最近的外节点所经过的边的数量。空节点的 $dist=0$。我们让这棵树保持左偏,即每个节点左儿子的 $dist$ 都 $\ge$ 右儿子的 $dist$。因此左偏树每个结点的 $dist$ 都等于右儿子的 $dist+1$。
所以一种常见的写法是将要合并的和右儿子合并,并且判断满不满足左偏性质,不满足就交换一下。复杂度证明参见[这里](https://oi.wiki/ds/leftist-tree/#复杂度证明)。
需要提醒一点,上面三种树理论上讲深度可能达到 $O(n)$,找一个点所在的堆顶要用并查集维护,不能直接暴力跳父亲。
### 线性建堆
这个会在图论的最小树形图中遇到,所以还是要讲一下。
其实很常见的写法是将要用到的数全部放到一个数组里,然后类似线段树建树的方式给他递归下去建树。
不过我们还有另一种略短一点的写法。我们将所有的值全部建出节点来,放到一个队列里面,然后不停的合并队列的前两个元素,直到只剩一个元素。
虽然还是很潦草,但是理想状态下队首的大小是 $1,1,\dots,1,2,2,\dots,2,4,4,\dots,4,8,\dots$。懂吧?如果不完全是 $2^n$ 形的数差的也不会太大。
## kd-tree
K-D Tree 是一种可以高效处理 $k$ 维空间信息的数据结构。
先讲建树:
k-D Tree 具有二叉搜索树的形态,二叉搜索树上的每个结点都对应 $k$ 维空间内的一个点。其每个子树中的点都在一个 $k$ 维的超长方体内,这个超长方体内的所有点也都在这个子树中。若当前超正方体只有一个点,就返回这个点,否则的话轮流选一个维度,并将这个维度的中位数作为这一维的分割标准。按照这一维的大小分成左右两部分。Eg.:
轮流选择多个维度可以使得树高降到 $\log n+O(1)$。正确性显然。查询复杂度是 $O(n^{1-\frac{1}{k}})$ 的。可见效果拔群(雾)。
那如果我们要修改呢?一种常见但是时间复杂度错误的写法是替罪羊树,这样会使得树高降到 $O(\log)$ 级别。而查询复杂度是建立在树高为 $\log n+O(1)$ 的基础上的。
有一种复杂度正确而且相对好写的方法叫做二进制分组。具体的,我们将这些树分成大小为 $2^0,2^1,\dots$ 的许多棵树,查询的时候每棵树查询一次,然后合并结果。如果某一层的大小超了就不停向上合并。均摊 $O(n\log^2n)$。可以证明查询复杂度仍然是 $O(n^{1-\frac{1}{k}})$ 的。
模板题参考代码如下:
```cpp
#include<bits/stdc++.h>
using namespace std;
int n, o, xa, ya, xb, yb, v;
inline void tmin(int& l, const int r) { (l > r) && (l = r); }
inline void tmax(int& l, const int r) { (l < r) && (l = r); }
using ini = initializer_list<int>;
template<const int wd>
struct pos {
int p[wd];
pos<wd>() { memset(p, 0, sizeof p); }
pos<wd>(ini pv) {
memcpy(p, pv.begin(), pv.size() << 2);
}
inline bool operator<(const pos<wd>& r) const{
for (int i = 0;i != wd;++i)
if (p[i] != r.p[i]) return p[i] < r.p[i];
return 1;
}
inline bool operator==(const pos<wd>& r) const{
for (int i = 0;i != wd;++i)
if (p[i] != r.p[i]) return 0;
return 1;
}
};
template<const int wd>
inline bool ninter(const pos<wd>& alu, const pos<wd>& ard, const pos<wd>& blu, const pos<wd>& brd) {
for (int i = 0;i != wd;++i) {
if (blu.p[i] > ard.p[i] || alu.p[i] > brd.p[i]) return 1;
}
return 0;
}
template<const int wd>
inline bool finter(const pos<wd>& alu, const pos<wd>& ard, const pos<wd>& blu, const pos<wd>& brd) {
for (int i = 0;i != wd;++i)
if (blu.p[i] < alu.p[i] || brd.p[i] > ard.p[i]) return 0;
return 1;
}
template<const int wd>
class kdtree {
struct node {
pos<wd> np, lu, rd;
int ls, rs, v, sm, f;
node() :ls(0), rs(0), v(0), sm(0), f(0) {};
}re[200005];
int rt[50]; stack<int>ps;
vector<pair<pos<wd>, int>>mt;
inline void ret(int p) { ps.emplace(p); }
inline int get() {
int p = ps.top(); ps.pop();
memset(&re[p], 0, sizeof(re[p]));
return p;
}
inline void pup(int p) {
re[p].sm = re[re[p].ls].sm + re[re[p].rs].sm + re[p].v;
re[p].lu = re[p].rd = re[p].np;
for (int i = 0;i != wd;++i) {
if (re[p].ls)
tmin(re[p].lu.p[i], re[re[p].ls].lu.p[i]),
tmax(re[p].rd.p[i], re[re[p].ls].rd.p[i]);
if (re[p].rs)
tmin(re[p].lu.p[i], re[re[p].rs].lu.p[i]),
tmax(re[p].rd.p[i], re[re[p].rs].rd.p[i]);
}
}
inline void getall(int p) {
mt.emplace_back(re[p].np, re[p].v);
if (re[p].ls) getall(re[p].ls);
if (re[p].rs) getall(re[p].rs);
ret(p);
}
inline int build(int l, int r, int cf) {
if (l > r) return 0;
int p = get();
if (l == r) {
re[p].np = mt[l].first;
re[p].v = mt[l].second;
re[p].f = cf;
pup(p);
return p;
}
int md = l + r >> 1;
nth_element(mt.begin() + l, mt.begin() + md, mt.begin() + r + 1,
[&](const pair<pos<wd>, int>& l, const pair<pos<wd>, int>& r) {
return l.first.p[cf] < r.first.p[cf];
});
re[p].np = mt[md].first;
re[p].v = mt[md].second;
re[p].f = cf; cf = (cf + 1) % wd;
re[p].ls = build(l, md - 1, cf);
re[p].rs = build(md + 1, r, cf);
pup(p);
return p;
}
inline int que(const pos<wd>& lu, const pos<wd>& rd, int p) {
if (!p || ninter(lu, rd, re[p].lu, re[p].rd)) return 0;
if (finter(lu, rd, re[p].lu, re[p].rd)) return re[p].sm;
int ret = 0;
if (finter(lu, rd, re[p].np, re[p].np)) ret += re[p].v;
ret += que(lu, rd, re[p].ls);
ret += que(lu, rd, re[p].rs);
return ret;
}
public:
inline void init() {
memset(rt, 0, sizeof rt);
for (int i = 2e5;i;i--) ret(i);
}
inline void add(int x, int y, int v) {
int lp = 0; mt.emplace_back(ini{ x, y }, v);
while (rt[lp]) getall(rt[lp]), rt[lp] = 0, lp++;
sort(mt.begin(), mt.end());
int j = -1;
for (int i = 0;i != mt.size();++i)
if (j != -1 && mt[i].first == mt[j].first)
mt[j].second += mt[i].second;
else mt[++j] = mt[i];
rt[lp] = build(0, j, 0); mt.clear();
}
inline int que(int xa, int ya, int xb, int yb) {
int ret = 0;
for (int i = 0;i != 20;++i)
ret += que(ini{ xa,ya }, ini{ xb,yb }, rt[i]);
return ret;
}
}; kdtree<2>kdt;
signed main() {
ios::sync_with_stdio(0);
cin >> n; int la = 0; kdt.init();
while (cin >> o, o != 3)
if (o & 1)
cin >> xa >> ya >> v,
xa ^= la, ya ^= la, v ^= la,
kdt.add(xa, ya, v);
else {
cin >> xa >> ya >> xb >> yb;
xa ^= la, ya ^= la, xb ^= la, yb ^= la;
cout << (la = kdt.que(xa, ya, xb, yb)) << endl;
}
}
```
不得不说真的非常屎山,考试的时候最好不要遇到。
# 数学
## 质数的判定
### 暴力
对于一个合数 $n$,他一定会有一个 $\lfloor\sqrt n\rfloor$ 以下的因数,由唯一分解定理,正确性显然。所以我们检验 $2$ 到 $\lfloor\sqrt n\rfloor$ 是不是 $n$ 的因数就完了。不给代码了。
### 埃氏筛
一个质数除自己以外的其他倍数一定是合数。所以我们从 $2$ 开始枚举,如果这个数没有标记就把他的其他倍数全部标记了。复杂度是 $O(n\log\log n)$ 的。代码如下:
```cpp
for (long long i = 2; i <= 1e6; ++i)
if (!isp[i])
for (int j = i; i * j <= 1e6; ++j)
isp[i * j] = 1;
//其实效率很高,手写 bitset 的话 3e8 能在 1.56s 内判完
```
### 欧拉筛
又名线性筛,真的是线性的。埃氏筛的复杂度不是严格线性,问题就在于同一个合数会所有的质数给标记。线性筛可以做到只被最小的质数标记。
我们思考对于每一个合数 $n=\prod_{i=1}^kp_i^{c_i},p_i<p_{i+1}$。那么他其实只有可能被 $n=\prod_{i=1}^kp_i^{c_i-[i=now]}$ 给标记到。这正是埃氏筛。但是因为有 `i % p[j] == 0 -> break`,所以说当 $now>1$ 的时候其标记到尝试会被更靠前的质数给禁用掉。所以只有在 $now=1$ 的时候才会被标记。从而是线性的。
代码如下:
```cpp
for (long long i = 2; i <= 1e7; ++i) {
if (!isp[i]) p[++pc] = i;
for (int j = 1; j <= pc && i * p[j] <= 1e7; ++j)
if (isp[i * p[j]] = 1, i % p[j] == 0) break;
}
//这个略微复杂一点,但是可以处理的真的很多!简单提一下:
//对于可以快速求出 f(p^k) 的积性函数,他可以做到线性复杂度求出 [1,n] 内的所有值
```
### Miller–Rabin
如果 $n$ 为素数,则 $\forall a<n$,设 $n−1=d\times 2^r,d$ 为奇数,则以下两个命题至少有一个成立:
1. $a^d\equiv 1\pmod n
\exist i\in[0,r-1],a^{d\times2^i}\equiv -1\pmod n
这个定理的逆定理并不成立,但是如果你取的 a 足够好,并且多测几组,那么总能将复杂度降下来。事实上如果你取 2,3,5,7,11,13,17,37,那么它在 long long 范围内的正确率是 100\%。
代码如下:
//2,3,5,7,11,13,17,37
//事实上下面这一组好像也是,不过这一组更好记
constexpr int ud[] = { 2,325,9375,28178,450775,9780504,1795265022 };
inline bool isprm(int n) {
if (n < 3 || n % 2 == 0) return n == 2;//特判
int u = n - 1, t = 0;
while (u % 2 == 0) u /= 2, ++t;
for (int a : ud){
int v = qpow(a, u, n);
if (v == 1 || v == n - 1 || v == 0) continue;
for (int j = 1; j <= t; j++){
v = mul(v, v, n);
if (v == n - 1 && j != t) { v = 1; break; }
if (v == 1) return 0;
}
if (v != 1) return 0;
}
return 1;
}