【学习笔记】ACAM(有图哟~)
Tomwsc
·
2026-02-14 10:29:37
·
算法·理论
前言
书接上回,学习字符串实在太过于痛苦,未尝深刻理解。故作此文,用以加深印象。
同时,在这里给大家道歉,由于本人太菜,刷题量很少,所以例题放得太简单了!请各位谅解。
\text{ACAM} 前置知识:\text{Trie} 、\text{KMP} (其实不会也无大碍)。
# 引入
我们通过一个[简单的问题](https://www.luogu.com.cn/problem/P3808)引入 $\text{ACAM}$:
> 给定 $n$ 个模式串 $s_i$ 和一个文本串 $t$。求有多少个 $s_i$ 在 $t$ 中出现过,$\sum|s_i|,t\le5\times 10^6$。
考虑一个最暴力的做法,直接枚举 $t$ 的每一个子串,判断是否存在 $s_i$ 与其相等。这个东西可以 $\text{hash}$ 加上 ```unordered_map``` 实现,做到 $O(n^2)$。但显然这并不能通过此题。如何优化,注意到这是多模式串问题,所以想到建 $\text{Trie}$。建出 $\text{Trie}$ 后可以在每一个 $s_i$ 的结束字符上进行标记,然后匹配时用 $t$ 在 $\text{Trie}$ 上走就行了。由于这个是 $\text{Trie}$ 的经典应用,故在此不展开。
可是在 $\text{Trie}$ 上匹配的最劣时间复杂度仍然是 $O(n^2)$ 的,具体地说,如果当前 $t_i$ 匹配到 $\text{Trie}$ 中的节点 $u$,但 $u$ 不存在一个子节点满足 $son_u=t_{i+1}$,那么此时我们称其为失配了。而在现在,处理失配唯一的方法便是从最初始的 $t_x$ 的下一位 $t_{x+1}$ 开始从 $\text{Trie}$ 的根节点重新匹配。
所以如果我们能在 $O(1)$ 的时间内处理失配的问题,那就可以做到线性。观察失配的问题出在哪里?对于下面这一组数据:
- $t$ 为 `abcd`。
- $s_i$ 分别为 `abc`、`bc`。
那么对于 $s$ 建出的 $\text{Trie}$ 就长这样:
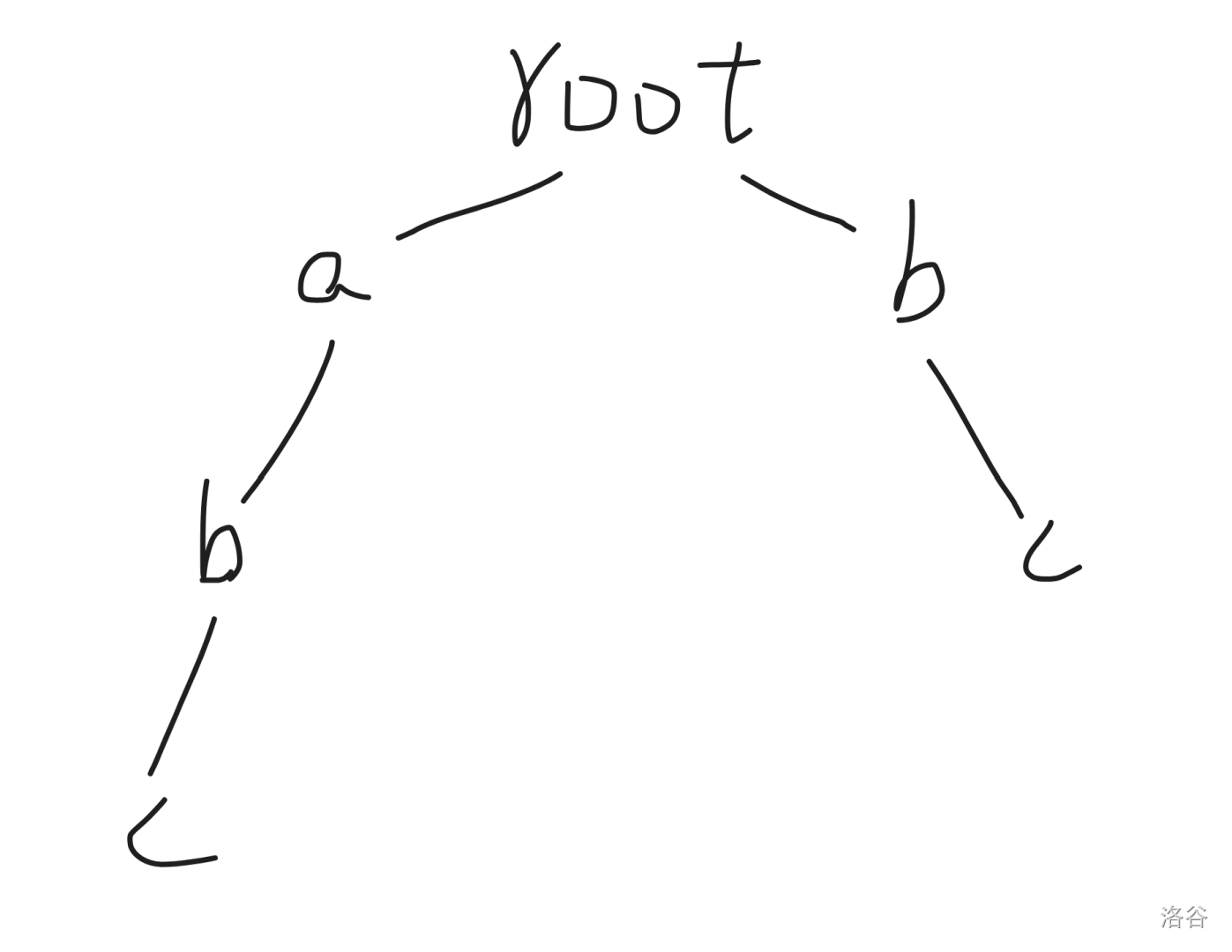
不妨模拟一下匹配的过程,发现是先从根走到 `a`,然后再依次走到 `b`、`c`。再想往下匹配时发现不存在 `d` 这个子节点了,所以重新退回根,然后用 $t$ 的初始的下一位 `b` 再进行第二次匹配。这样我们便可以匹配出 `abc` 和 `bc` 这两个子串,但是观察一下就会发现,在第一次匹配时因为 `abc` 已经包含 `bc` 作为后缀,所以如果我们对于所有的 `abc` 的后缀都标记一下,就可以直接往下匹配 `d` 了。由此,我们引出了 $\text{fail}$ 指针的概念。
# $\text{fail}$ 指针
$\text{fail}$ 指针,又称失配指针,可以很好地处理上文所提及的失配问题。
详细地说,我们先仍然对 $s$ 建出 $\text{Trie}$,而每一个 $\text{Trie}$ 中的节点的对应的状态就是它所代表的 $s_i$ 的一段前缀。然后记 $\text{Trie}$ 中状态 $u$ 的失配指针 $\text{fail}_u$ 指向的是 $u$ 的最长后缀 $v$。这其实就和 $\text{KMP}$ 中的 $\text{next}$ 指针有几分相似。
比如上面那个 $\text{Trie}$ 中便存在这么**一个** $\text{fail}$ 指针(红色的边):
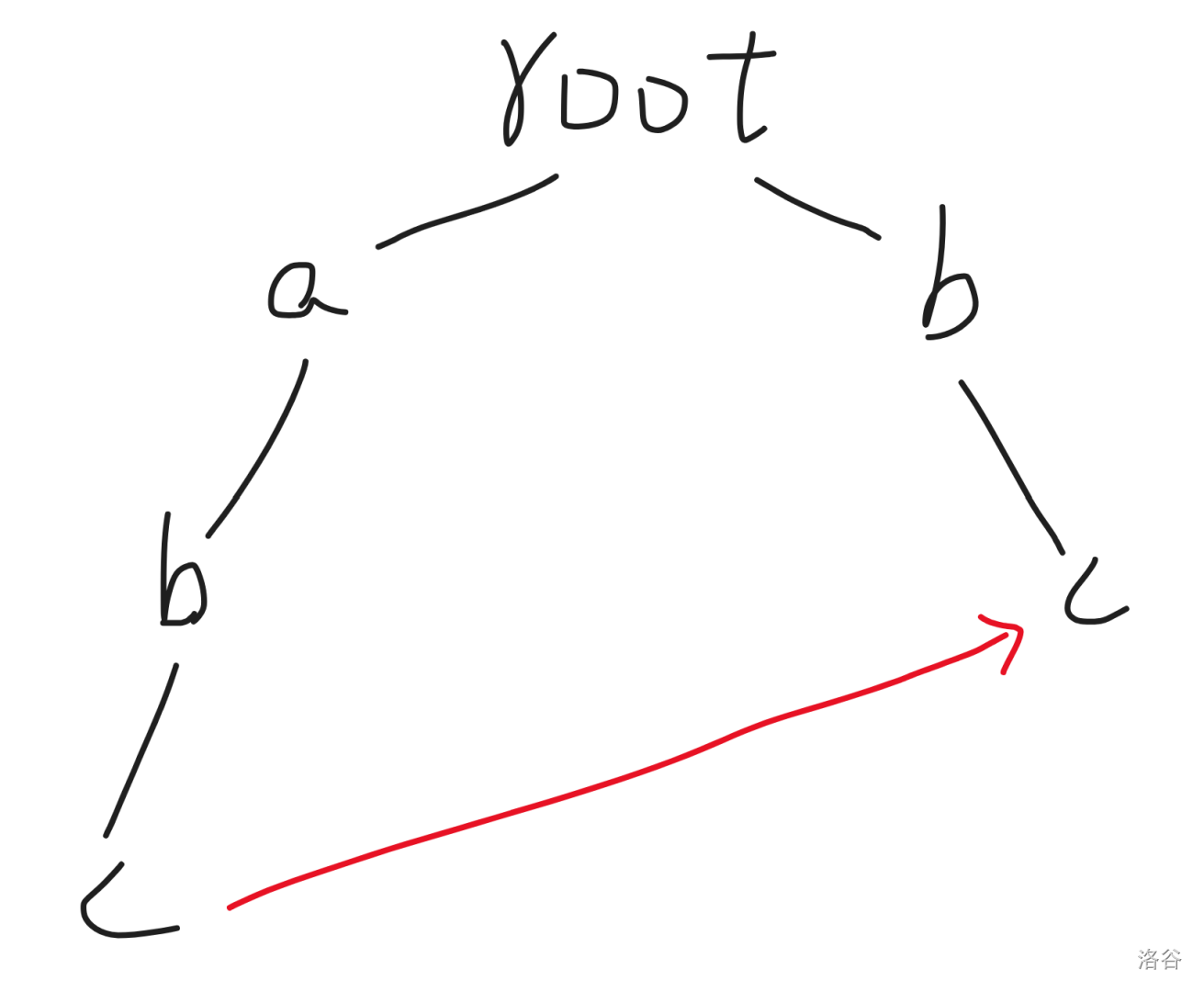
因为 `bc` 是 $\text{Trie}$ 中 `abc` 的最长后缀,所以这条 $\text{fail}$ 指针存在。
而由于这条 $\text{fail}$ 指针的存在,我们可以在走到 `c` 的时候按照这个 $\text{fail}$ 指针跳到 `bc` 的结尾,这样就可以把这两个字符串都标记为出现过。更一般的情况下,一个状态 $u$ 可能可以到达 $\text{fail}_u,\text{fail}_{\text{fail}_u}\cdots$,所以我们需要不断地沿着 $\text{fail}$ 指针往上跳,然后将跳到的状态标记为存在。考虑到如果跳到了一个已经被标记的状态 $u$,我们便可以停止了,因为 $u$ 的 $\text{fail}$ 指针指向的一系列状态都被标记过了。因此每一个状态最多只会被标记一次,时间复杂度是线性的。
每次跳 $\text{fail}$ 都会到达原状态的最长后缀,所以可以做到不漏标记状态,正确性显然。
## $\text{fail}$ 指针的构建
接下来考虑 $\text{fail}$ 指针的构建方法。
由于 $\text{fail}$ 指针和 $\text{next}$ 指针的十分相似,所以可以参考 $\text{next}$ 指针的构建方法。
具体地说,假设当前构建到 $\text{Trie}$ 中的状态 $u$,$u$ 对应的字符为 $x$,$son(u, c)$ 表示 $u$ 的儿子且该儿子对应的字符为 $c$, $u$ 在 $\text{Trie}$ 中的父亲为 $v$。则循环执行以下过程:
- 若 $\text{Trie}$ 中存在 $\text{fail}_{v}\rightarrow son(\text{fail}_{v}, x)$ 的边,则令 $fail_u\leftarrow son(\text{fail}_{v}, x)$。
- 否则令 $v\leftarrow \text{fail}_v$。
- 若 $v$ 跳到根节点却仍未找到,就令 $\text{fail}_u\leftarrow 0$(钦定 $0$ 为 $\text{Trie}$ 的根)。
为什么这是正确的?
首先,$\text{fail}_v$ 对应的是状态 $v$ 的最长后缀,那么如果存在 $son(\text{fail}_{v}, x)$,则状态 $son(\text{fail}_{v}, x)$ 一定是 $u$ 的最长后缀。
而如果不存在,就不断对 $v$ 跳 $\text{fail}$,因为 $\text{fail}_v$ 对应的仍然是状态 $v$ 的最长后缀,所以第一次找到存在的 $son(\text{fail}_{v}, x)$ 时,状态 $son(\text{fail}_{v}, x)$ 一定也是 $u$ 的最长后缀。
最后,如果整个 $\text{Trie}$ 中都不存在 $son(\text{fail}_{v}, x)$,那么最长后缀为空,所以指向根节点是没问题的。
因为构建过程维持了 $\text{fail}_u$ 的性质,即指向 $u$ 的最长后缀,所以是正确的。
容易发现,在构建过程中我们需要知道所有深度比 $u$ 小的状态的 $\text{fail}$ 指针,所以需要采用 $\text{bfs}$ 构建。
接下来看一个例子:
> 对于 `heatt`、`att`、`earth` 这三个字符串构建 $\text{fail}$ 指针。
首先把 $\text{Trie}$ 建出来,长这样(橙色数字是状态的编号,红色边是 $\text{fail}$ 指针):
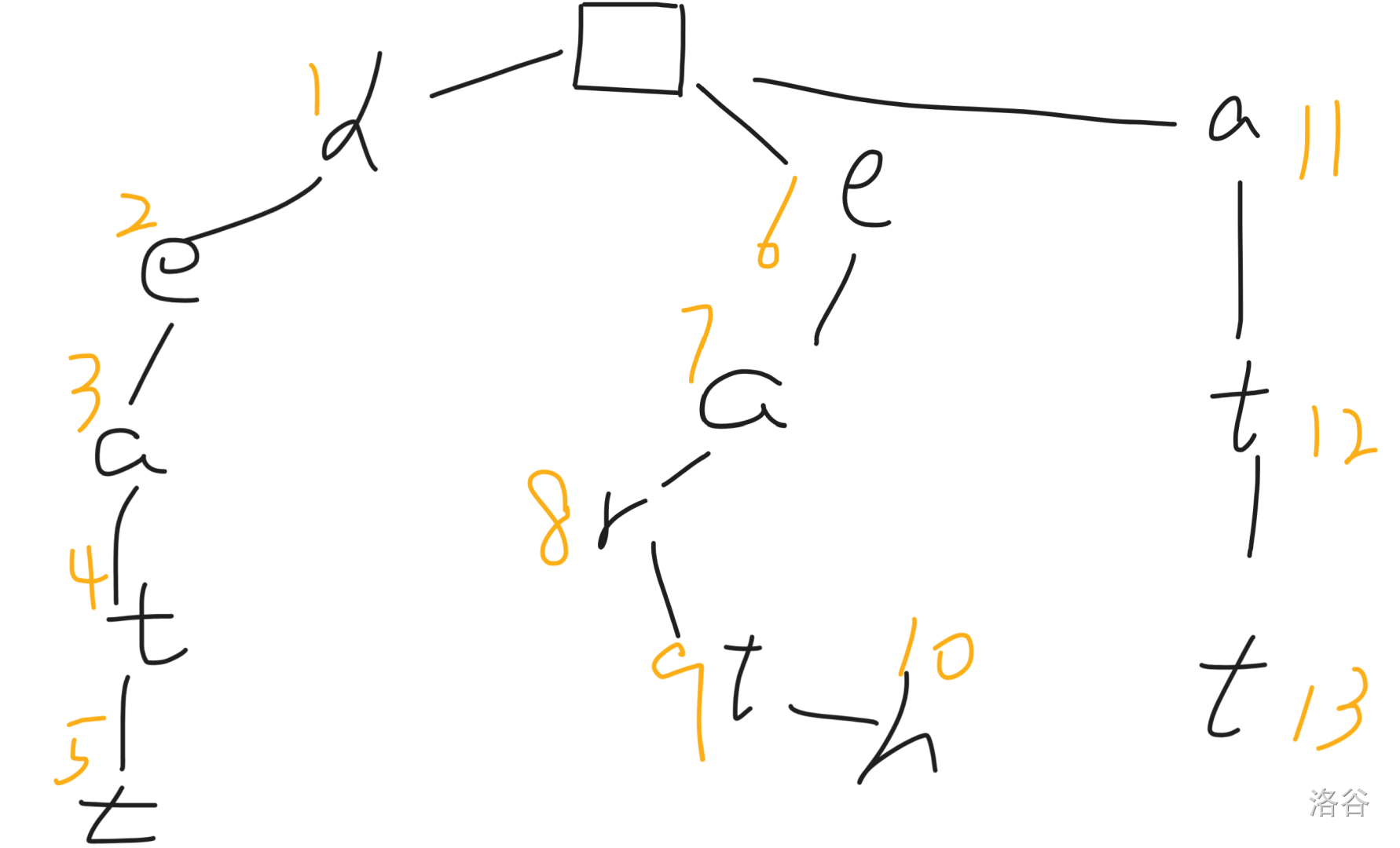
我们记根节点对应第 $0$ 层,则对于第 $1$ 层的每一个节点,其 $\text{fail}$ 指针直接指向根节点(这个是为了方便实现而做的),得到:
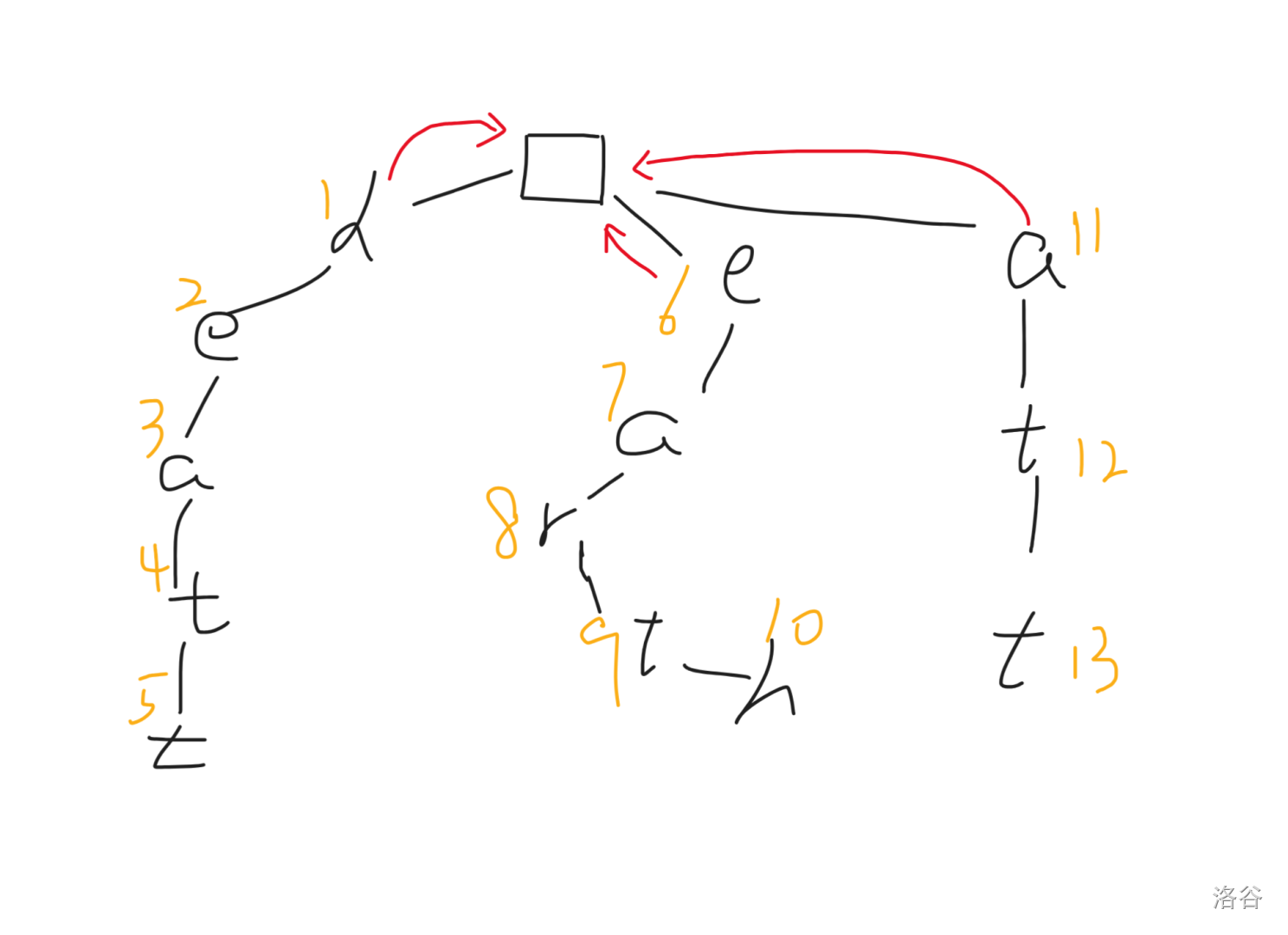
接着,$2$ 号节点的父亲的 $\text{fail}$ 指针指向根节点,且根节点存在字符为 `e` 的子节点 $6$,所以 $\text{fail}_2\leftarrow 6$,同理,$\text{fail}_7\leftarrow 11$。而节点 $12$ 因为没有找到存在的合法状态,所以 $\text{fail}_{12}\leftarrow \text{root}$。即:
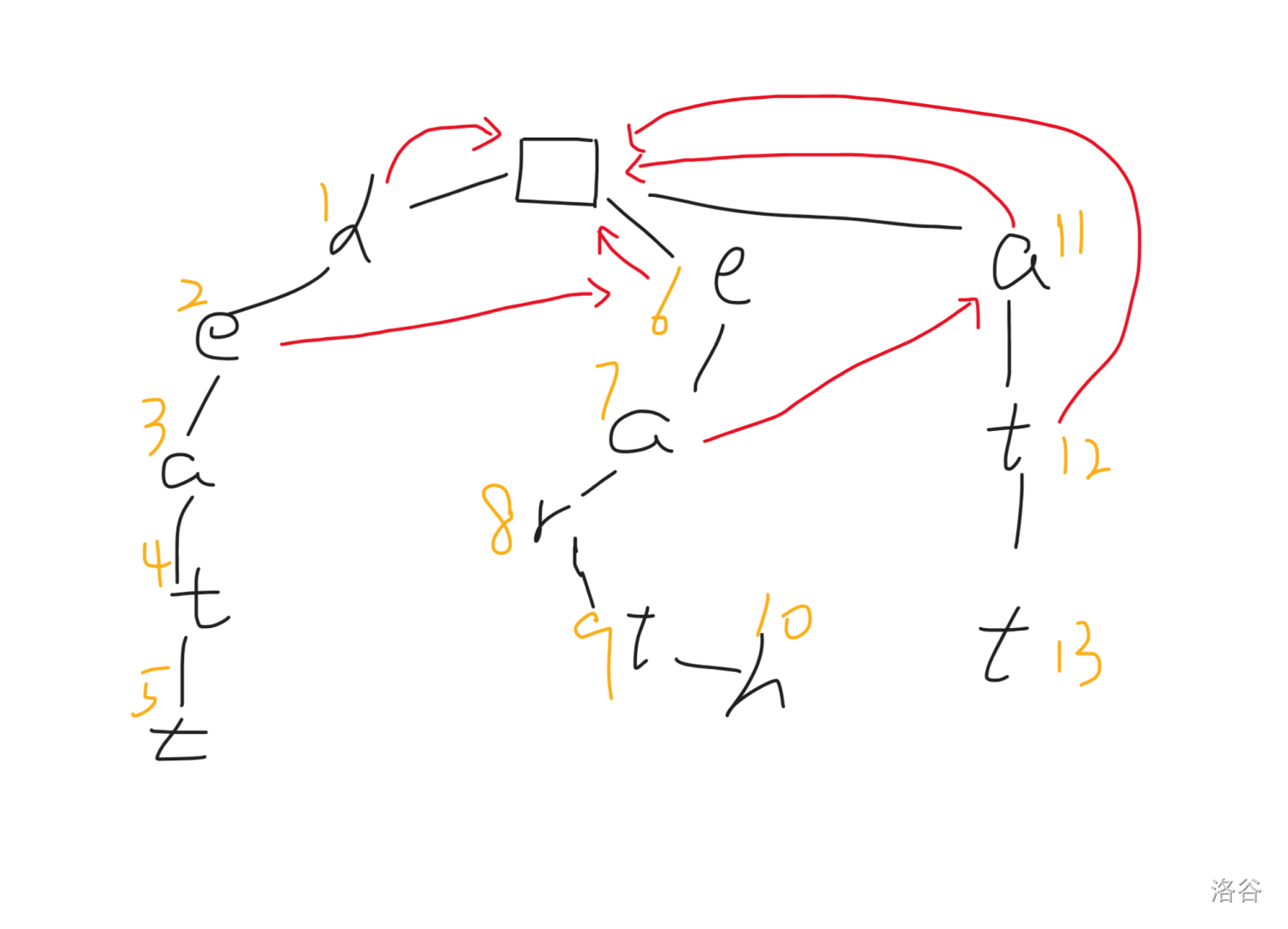
此时,$3$ 号节点对应的父亲 $2$ 的 $\text{fail}$ 指向了 $6$,而 $6$ 节点存在子节点满足字符为 `a`,所以 $\text{fail}_3\leftarrow 7$,而 $8$ 号节点和 $13$ 号节点因为没找到合法的状态,所以指向根节点。如图(~~稍微画得有点乱~~):
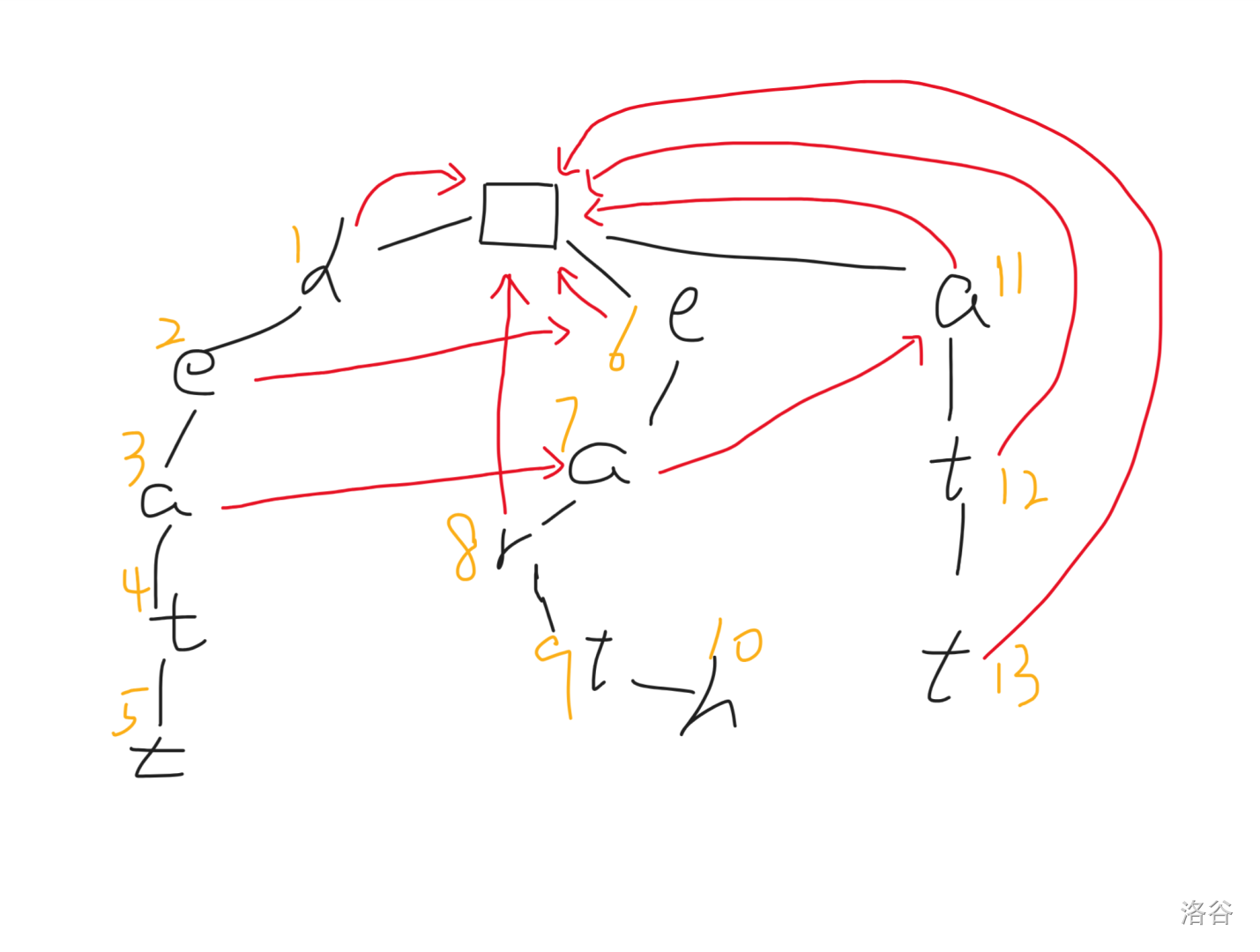
然后,当我们构建 $4$ 号节点的 $\text{fail}$ 指针时,发现其父亲指向的节点 $7$ 不存在一个字符为 `t` 的儿子,所以对其父亲 $3$ 跳 $\text{fail}$,令 $3\leftarrow fail_3$,此时我们再判断 $fail_7$ 是否存在。一个字符为 `t` 的子节点,发现是存在的,于是令 $\text{fail}_4\leftarrow 12$。而 $9$ 则还是连向根节点:
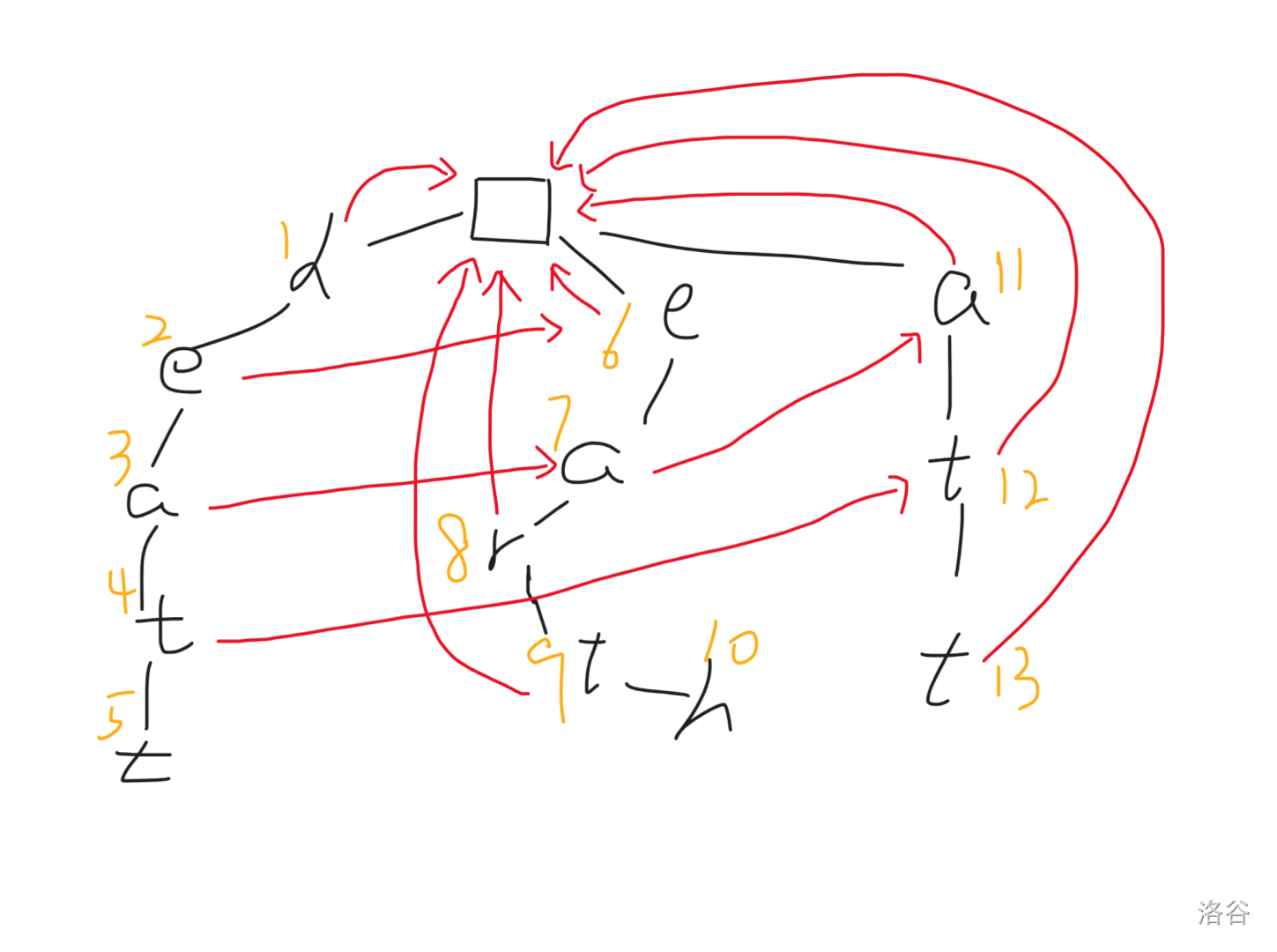
最后的两个节点的构建都是平凡的,不赘述了。构建完成后便是这样的:
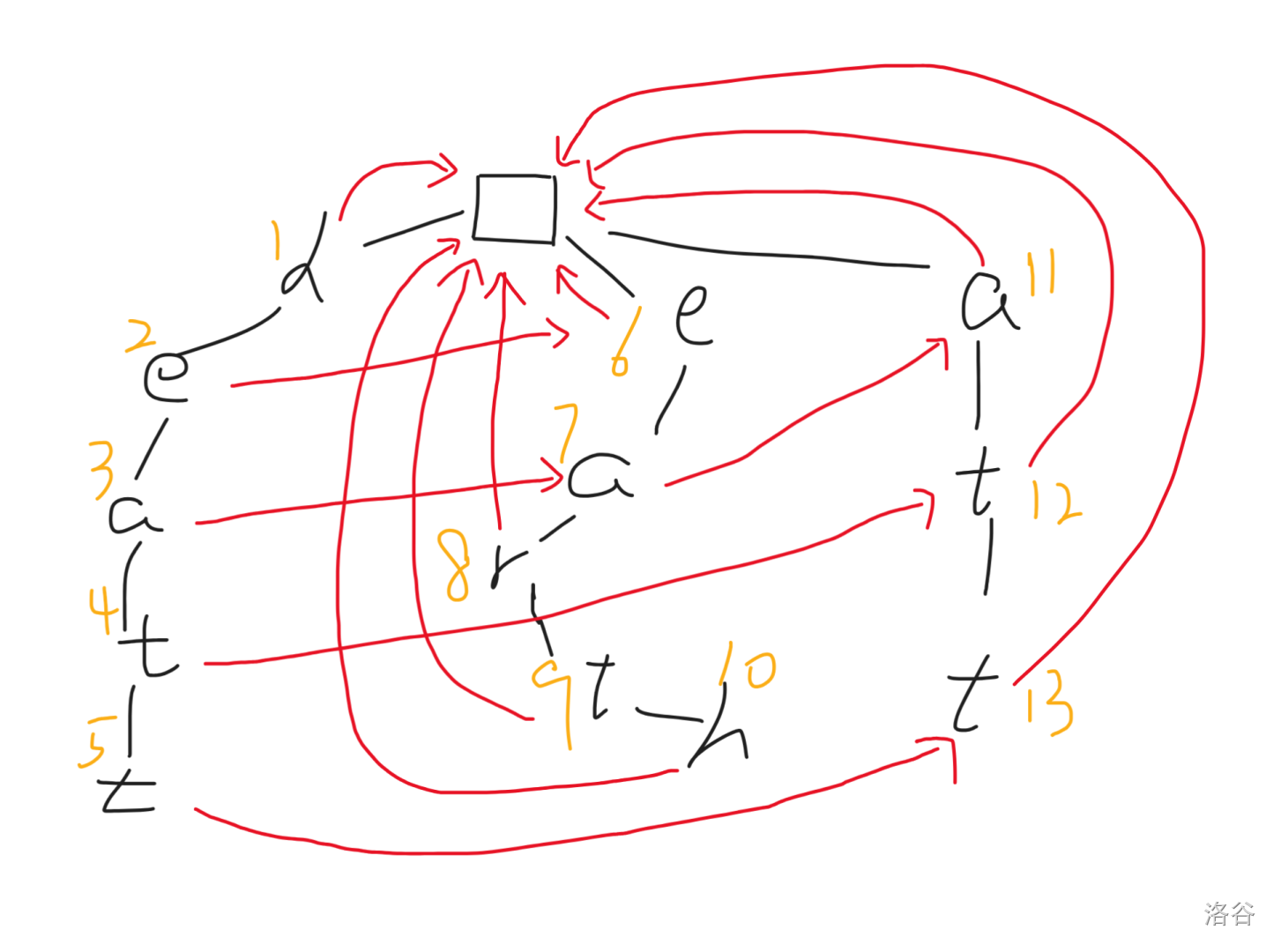
## $\text{Trie}$ 图
考虑刚刚那一个构建过程,发现如果每次都暴力跳 $\text{fail}$ 找是否存在合法子节点,这样的时间复杂度是 $O(n^2)$ 的,显然不能被接受。
此时可以使用一个类似并查集的路径压缩的优化,每次都将跳 $\text{fail}$ 的路径进行压缩。详细地说,若构建到状态 $u$:
- 若不存在 $son(u, x)$,则令 $son(u, x)\leftarrow son(\text{fail}_u, x)$。
- 否则,直接令 $\text{fail}_{son(u, x)}\leftarrow son(\text{fail}_u, x)$。
这样便可以做到线性构建自动机。
而在这个过程中,$\text{Trie}$ 已经不再是原先的形态,而是新增了一些“路径压缩”的转移边。我们称此时的 $\text{Trie}$ 为 $\text{Trie}$ 图。
在 $\text{Trie}$ 图中,新增的转移边其实就是指向了新增一个字符之后的最长后缀。所以在大多数多模匹配过程中,我们可以直接在 $\text{ACAM}$ 上依照文本串进行遍历,因为新增的转移边可以实现自动跳转最长后缀的功能。
例子的图太乱了,不好画,可以去看 oi-wiki 上的。
### 代码
下面给出构建 $\text{Trie}$ 图的代码:
::::info[Code]
```cpp
struct Node {
int c[26], fail;
} trie[N];
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].c[i]) {
q.push(trie[0].c[i]);
trie[trie[0].c[i]].fail = 0;
}
}
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[p].c[i]) trie[p].c[i] = trie[trie[p].fail].c[i];
else {
q.push(trie[p].c[i]);
trie[trie[p].c[i]].fail = trie[trie[p].fail].c[i];
}
}
}
}
```
::::
## 多模式串匹配
有了 $\text{ACAM}$,多模匹配问题就迎刃而解了。
直接从根节点开始进行匹配,每次走到一个状态就开始跳 $\text{fail}$,把所有未被标记的状态都标记上,遇到被标记过的状态就停止(原因在 $\text{fail}$ 指针那一部分有讲)。
这样的时间复杂度是线性的。
### 代码
引入部分的问题的代码:
::::info[Code]
```cpp
#include<bits/stdc++.h>
#define ll long long
#define ull unsigned long long
#define i128 __int128
#define inf (1ll << 62)
#define pb push_back
#define mp make_pair
#define PII pair<int , int>
#define fi first
#define se second
using namespace std;
const int MAXN = 1e6 + 10;
struct Node {
int c[26] , fail , cnt;
};
Node trie[MAXN];
int tot;
inline int getnum(char c) {return c - 'a';}
inline void insert(string s) {
int p = 0;
for(auto i : s) {
if(!trie[p].c[getnum(i)]) trie[p].c[getnum(i)] = ++ tot;
p = trie[p].c[getnum(i)];
}
trie[p].cnt ++;
return;
}
inline void build() {
queue<int>q;
for(int i = 0;i < 26;i ++) {
if(trie[0].c[i]) {
trie[trie[0].c[i]].fail = 0;
q.push(trie[0].c[i]);
}
}
while(!q.empty()) {
int u = q.front();
q.pop();
for(int i = 0;i < 26;i ++) {
if(trie[u].c[i]) {
trie[trie[u].c[i]].fail = trie[trie[u].fail].c[i];
q.push(trie[u].c[i]);
} else trie[u].c[i] = trie[trie[u].fail].c[i];
}
}
return;
}
inline int AC(string s) {
int ans = 0 , n = s.length() , p = 0;
for(int i = 0;i < n;i ++) {
p = trie[p].c[getnum(s[i])];
for(int j = p;j && trie[j].cnt != -1;j = trie[j].fail) {
ans += trie[j].cnt;
trie[j].cnt = -1;
}
}
return ans;
}
inline void solve() {
int n;
string s;
cin >> n;
for(int i = 1;i <= n;i ++) {
cin >> s;
insert(s);
}
build();
cin >> s;
cout << AC(s) << "\n";
return;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
while(t --) {
solve();
}
return 0;
}
```
::::
## $\text{fail}$ 树
有一个显然的结论是 $\text{ACAM}$ 中的 $\text{fail}$ 指针共同构成一棵树。我们称其为 $\text{fail}$ 树。
因为每一个状态的 $\text{fail}$ 指针都会指向比其深度小的状态,所以不会形成环。故会形成 $\text{fail}$ 树。
刚刚那一个例子的 $\text{fail}$ 树如下:
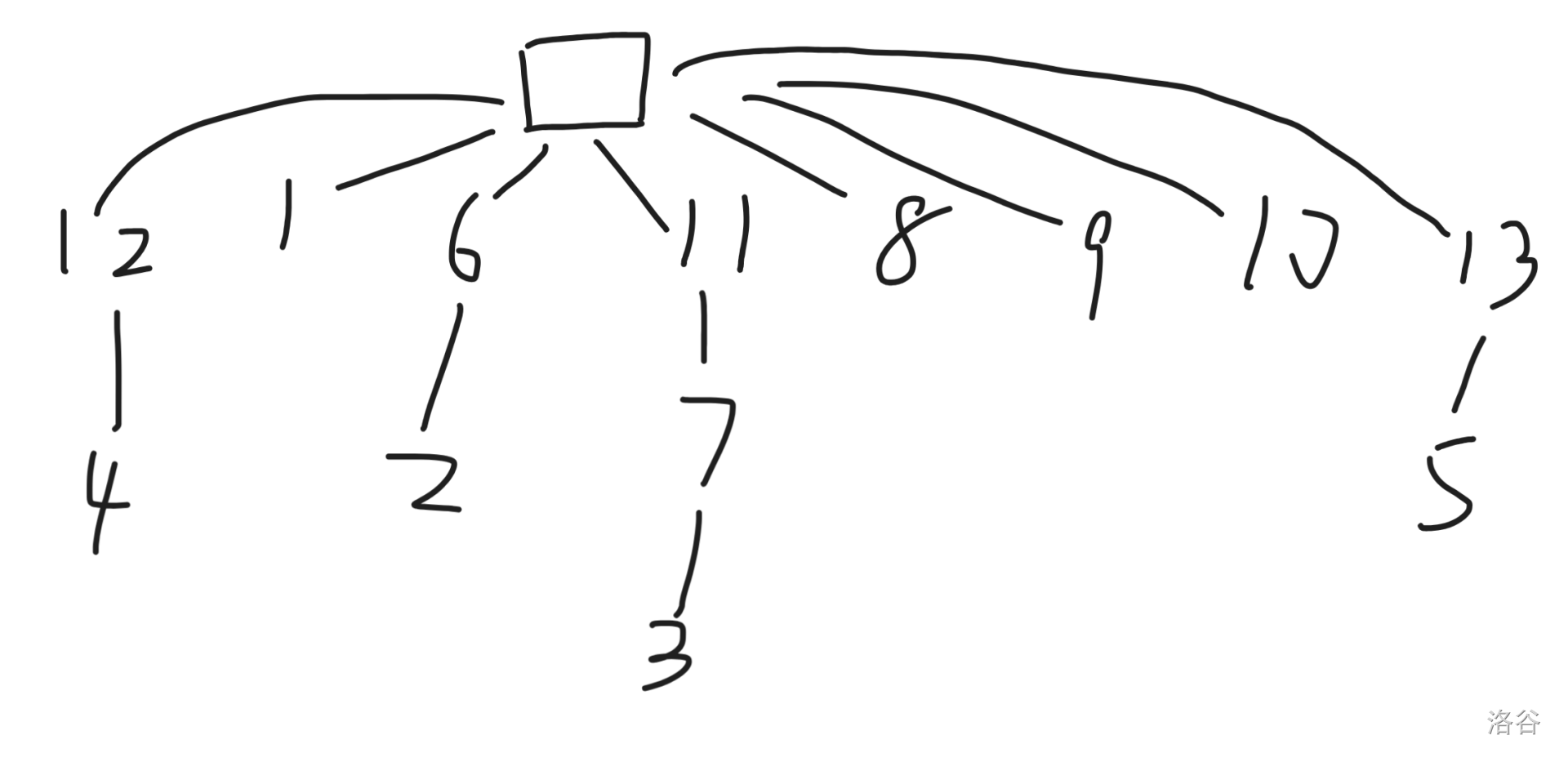
而在 $\text{fail}$ 树中一个很重要的性质是:以 $u$ 为根的子树中所有的状态都包含状态 $u$ 作为后缀。这个性质会在很多题目中发挥极其美妙的作用。
## 拓扑排序优化
再看一道[题](https://www.luogu.com.cn/problem/P5357):
> 给定一个文本串 $s$ 和 $n$ 个模式串 $t_i$,求每个模式串 $t_i$ 在 $s$ 中的出现次数。$\sum|t_i|, s\le 2\times 10^6$。
在这题中,如果我们选择在匹配的过程中不断跳 $\text{fail}$ 然后对跳到的状态的答案进行 $+1$ 的时间复杂度是 $O(n^2)$ 的,因为我们需要把每一个 $\text{fail}$ 的答案都 $+1$。如何优化呢?
观察到,每次走到一个状态 $u$,那么会在 $\text{fail}$ 树中对 $u$ 到根节点的路径上的所有状态的答案增加 $1$。而因为 $\text{fail}$ 指针构成一棵树,所以我们可以将每次在 $u$ 处增加的答案记录下来,最后做一遍拓扑排序更新其到 $\text{fail}$ 树根节点的答案。
### 代码
::::info[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 2e5 + 10;
int n;
string s;
namespace acam {
int tot = N - 1;
struct Trie {
int son[62], fail, cnt, deg, id, ans;
} trie[N];
vector<vector<int>> d(N); //相同的模式串的映射
void Init() {
for (int i = 0; i < n; i++) {
d.clear();
}
for (int i = 0; i <= tot; i++) {
for (int j = 0; j < 62; j++) {
trie[i].son[j] = 0;
}
trie[i].fail = trie[i].cnt = trie[i].deg = trie[i].ans = 0;
trie[i].id = -1;
}
tot = 0;
}
int get(char c) {
if ('0' <= c && c <= '9') return c - '0';
else if ('A' <= c && c <= 'Z') return 10 + c - 'A';
else if ('a' <= c && c <= 'z') return 36 + c - 'a';
}
void update(string s, int id) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].son[x]) {
trie[p].son[x] = ++tot;
}
p = trie[p].son[x];
}
if (trie[p].id == -1) trie[p].id = id;
d[trie[p].id].push_back(id);
}
void build() {
queue<int> q;
for (int i = 0; i < 62; i++) {
if (trie[0].son[i]) {
trie[trie[0].son[i]].fail = 0;
q.push(trie[0].son[i]);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 62; i++) {
if (!trie[u].son[i]) trie[u].son[i] = trie[trie[u].fail].son[i];
else {
trie[trie[u].son[i]].fail = trie[trie[u].fail].son[i];
trie[trie[trie[u].son[i]].fail].deg++;
q.push(trie[u].son[i]);
}
}
}
}
void ac(string t) {
int p = 0;
for (auto i : t) {
int x = get(i);
p = trie[p].son[x];
trie[p].ans++;
}
}
void topu(vector<int>& ans) {
int n = ans.size();
queue<int> q;
for (int i = 1; i <= tot; i++) {
if (!trie[i].deg) {
q.push(i);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
int p = trie[u].fail;
trie[p].ans += trie[u].ans;
trie[trie[u].fail].deg--;
if (!trie[trie[u].fail].deg) {
q.push(trie[u].fail);
}
}
for (int i = 1; i <= tot; i++) {
if (trie[i].id != -1) {
ans[trie[i].id] = trie[i].ans;
}
}
for (int i = 0; i < n; i++) {
if (!d[i].size()) continue;
for (auto j : d[i]) {
ans[j] = ans[d[i][0]];
}
}
}
}
using namespace acam;
void solve() {
cin >> n;
Init();
for (int i = 0; i < n; i++) {
string s;
cin >> s;
update(s, i);
}
build();
vector<int> ans(n);
string t;
cin >> t;
ac(t);
topu(ans);
for (int i = 0; i < n; i++) {
cout << ans[i] << "\n";
}
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
while (t--) {
solve();
}
return 0;
}
```
::::
## 例题
### [P3121](https://www.luogu.com.cn/problem/P3121)
::::info[题意]{open}
给定一个文本串 $s$ 和 $n$ 个模式串 $t_{1\dots n}$。Farmer John 每次从 $s$ 中找到出现最早的模式串,然后将其删除,直到文本串中不再包含模式串。
- 保证 $t_i$ 在 $s$ 中起始位置互不相同,且 $t_i$ 之间不存在包含关系。
- $\sum|t_i|,|s|\le 10^5$。
::::
::::success[做法]
观察到是多模匹配,所以先对模式串建出 $\text{ACAM}$。
需要注意到是,在文本串中删去一个模式串后可能会产生新的模式串。但容易发现,这个删除的过程其实可以用栈来模拟。即在匹配时将到达的点的编号压入栈中,然后每次走到代表模式串 $t_i$ 结尾的状态,就弹出 $|t_i|$ 个元素,再回到栈顶的所记录的节点编号。
因为每一个 $s$ 中的字符最多出栈入栈一次,所以时间复杂度是线性的。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr int N = 1e5 + 10;
int n, tot;
struct Trie {
int fail, son[26], len;
} trie[N];
string s;
stack<int> st, stk;
int get(char c) {
return c - 'a';
}
void update(string t) {
int p = 0;
for (auto i : t) {
if (!trie[p].son[get(i)]) {
trie[p].son[get(i)] = ++tot;
}
p = trie[p].son[get(i)];
}
trie[p].len = t.length();
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].son[i]) {
q.push(trie[0].son[i]);
trie[trie[0].son[i]].fail = 0;
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[u].son[i]) trie[u].son[i] = trie[trie[u].fail].son[i];
else {
trie[trie[u].son[i]].fail = trie[trie[u].fail].son[i];
q.push(trie[u].son[i]);
}
}
}
}
void query() {
int p = 0;
for (int i = 0; i < s.length(); i++) {
p = trie[p].son[get(s[i])];
st.push(i);
stk.push(p);
if (trie[p].len) {
int k = trie[p].len;
while (k--) {
st.pop();
stk.pop();
}
if (!stk.empty()) {
p = stk.top();
} else {
p = 0;
}
}
}
}
void solve() {
cin >> s >> n;
for (int i = 0; i < n; i++) {
string t;
cin >> t;
update(t);
}
build();
query();
vector<char> ans;
while (!st.empty()) {
ans.push_back(s[st.top()]);
st.pop();
}
reverse(ans.begin(), ans.end());
for (auto i : ans) {
cout << i;
}
cout << "\n";
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [AT_abc268_h](https://www.luogu.com.cn/problem/AT_abc268_h)
::::info[题意]{open}
给定一个字符串 $S$,可以对 $S$ 进行任意次操作(包括 $0$ 次):
- 选择一个整数 $i$,满足 $1\le i\le |S|$,将 $S_i$ 变成 `*`。
请求出若想要 $T_1,T_2,\cdots,T_n$ **不再作为 $S$ 的子串出现**,至少需要进行多少次操作。
- $\sum |T_i|,|S|\le 5\times 10^5$。
- $T_i$ 两两互不相同。
- $T_i$ 和 $S$ 仅包含小写英文字母。
::::
::::success[做法]
容易发现,如果找出了每一个存在于文本串中的模式串,并将这些模式串的左右边界的下标标记出来,记作 $l_i$ 与 $r_i$。则问题就转变成了一个很典的区间选点,即在 $i\in[1, n]$ 中的每一个区间 $[l_i, r_i]$ 中都至少有一个位置被改变。这个东西直接以右端点为第一关键字排序再贪心就行了。所以我们只需要找出文本串中每一个模式串的位置,这就是个多模式串匹配,直接上 $\text{ACAM}$。
假设现在在 $\text{ACAM}$ 上匹配到点 $u$,则由区间选点的贪心考虑,只需要选其最短真后缀且该后缀为模式串,然后放进要贪心的区间中即可。最短真后缀可以在预处理 $\text{fail}$ 的时候计算出来。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 5e5 + 10;
struct acam {
int tot = 0;
struct Node {
int c[26], fail, depth, flag, cnt;
};
vector<Node> trie;
acam(int n) {
trie.resize(n);
trie[0].depth = trie[0].flag = 0;
}
int get(char c) {
return c - 'a';
}
void insert(string s) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].c[x]) {
trie[p].c[x] = ++tot;
trie[tot].depth = trie[p].depth + 1;
}
p = trie[p].c[x];
}
trie[p].flag = 1;
trie[p].cnt = trie[p].depth;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].c[i]) {
q.push(trie[0].c[i]);
}
}
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[p].c[i]) trie[p].c[i] = trie[trie[p].fail].c[i];
else {
q.push(trie[p].c[i]);
trie[trie[p].c[i]].fail = trie[trie[p].fail].c[i];
trie[trie[p].c[i]].flag |= trie[trie[trie[p].c[i]].fail].flag;
if (trie[trie[trie[p].c[i]].fail].cnt) {
trie[trie[p].c[i]].cnt = trie[trie[trie[p].c[i]].fail].cnt;
}
}
}
}
}
vector<PII> calc(string t) {
vector<PII> v;
int p = 0;
for (int i = 0; i < t.size(); i++) {
int x = get(t[i]);
p = trie[p].c[x];
if (trie[p].cnt) {
v.emplace_back(i - trie[p].cnt + 1, i);
}
}
return v;
}
};
void solve() {
int n;
string s;
cin >> s >> n;
acam ac(N);
for (int i = 0; i < n; i++) {
string t;
cin >> t;
ac.insert(t);
}
ac.build();
vector<PII> v = ac.calc(s);
sort(v.begin(), v.end(), [&](PII a, PII b) {
if (a.second == b.second) return a.first < b.first;
return a.second < b.second;
});
int lst = -1, ans = 0;
for (auto [l, r] : v) {
if (l > lst) {
ans++;
lst = r;
}
}
cout << ans << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int t = 1;
// cin >> t;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [P14363](https://www.luogu.com.cn/problem/P14363)
::::info[题意]{open}
Replace。
::::
::::success[做法]
观察直接做似乎很困难,所以想办法对字符串进行一些变换。
容易发现,如果我们要将 $t_1$ 替换成 $t_2$,那么一定要换的部分是除去 $t_1,t_2$ 的最长公共前缀和 $t_1,t_2$ 的最长公共后缀之后的中间的不同的部分。而其最长公共前缀和后缀则是可换可不换的。因此我们有了一个初步的替换方案,即:
- 记 $t_1,t_2$ 的最长公共前缀为 $A$,最长公共后缀为 $B$,$t_1$ 剩下的部分为 $C$,$t_2$ 剩下的部分为 $D$,则将 $t_1$ 与 $t_2$ 拼成 $ACDB$。
我们可以对于字符串二元组 $(s_1, s_2)$ 也进行这样的变换,然后进行多模匹配。
但这会引出一个问题,就是可能 $(s_1,s_2)$ 变换完之后会变成 $AB$,这样显然不满足条件。所以我们要插入特殊字符,使匹配成功当且仅当模式串包含 $CD$。此时我们可以将 $ACDB$ 变成 $A?CD?B$,$(s_1,s_2)$ 同理,这样就可以避免这个问题了。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 6e6 + 10;
constexpr char C = char('a' + 26);
int n, q;
struct acam {
int tot = 0;
struct Trie {
int son[27], fail, cnt;
};
vector<Trie> trie;
acam(int _n) {
trie.resize(_n);
}
int get(char c) {
return c - 'a';
}
void update(string s) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].son[x]) {
trie[p].son[x] = ++tot;
}
p = trie[p].son[x];
}
trie[p].cnt++;
}
void build() {
queue<int> q;
for (int i = 0; i < 27; i++) {
if (trie[0].son[i]) {
trie[trie[0].son[i]].fail = 0;
q.push(trie[0].son[i]);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 27; i++) {
if (!trie[u].son[i]) trie[u].son[i] = trie[trie[u].fail].son[i];
else {
trie[trie[u].son[i]].fail = trie[trie[u].fail].son[i];
trie[trie[u].son[i]].cnt += trie[trie[trie[u].son[i]].fail].cnt;
q.push(trie[u].son[i]);
}
}
}
}
int query(string s) {
int p = 0, ans = 0;
for (auto i : s) {
int x = get(i);
p = trie[p].son[x];
ans += trie[p].cnt;
}
return ans;
}
};
void solve() {
cin >> n >> q;
acam ac(N);
for (int i = 0; i < n; i++) {
vector<string> s(2);
for (int j = 0; j < 2; j++) {
cin >> s[j];
}
string t1 = "", t2 = "";
int l = -1, r = -1;
for (int j = 0; j < s[0].size(); j++) {
if (s[0][j] != s[1][j]) {
l = j;
break;
}
t1 += s[0][j];
}
for (int j = s[0].size() - 1; j >= 0; j--) {
if (s[0][j] != s[1][j]) {
r = j;
break;
}
t2 += s[0][j];
}
reverse(t2.begin(), t2.end());
ac.update(t1 + C + (l != -1 ? s[0].substr(l, r - l + 1) + s[1].substr(l, r - l + 1) : "") + C + t2);
}
ac.build();
while (q--) {
vector<string> s(2);
for (int j = 0; j < 2; j++) {
cin >> s[j];
}
string t1 = "", t2 = "";
int l = -1, r = -1;
for (int j = 0; j < s[0].size(); j++) {
if (s[0][j] != s[1][j]) {
l = j;
break;
}
t1 += s[0][j];
}
for (int j = s[0].size() - 1; j >= 0; j--) {
if (s[0][j] != s[1][j]) {
r = j;
break;
}
t2 += s[0][j];
}
reverse(t2.begin(), t2.end());
string t = t1 + C + (l != -1 ? s[0].substr(l, r - l + 1) + s[1].substr(l, r - l + 1) : "") + C + t2;
cout << ac.query(t) << "\n";
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int t = 1;
// cin >> t;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [P2444](https://www.luogu.com.cn/problem/P2444)
::::info[题意]{open}
给出 $n$ 个非空 $01$ 串 $s_{1\dots n}$,判断是否存在无限长的 $01$ 串 $t$,使 $t$ 不包含任何一个 $s_i$。
- $\sum|s_i|\le 3\times 10^4$。
::::
::::success[做法]
考虑先对于 $s_i$ 建出 $\text{ACAM}$,然后因为 $\text{ACAM}$ 的本质就是将 $\text{Trie}$ 树变成 $\text{Trie}$ 图,所以如果把一个无限长的满足题意的字符串丢到 $\text{ACAM}$ 上取匹配。那么就会一直走不到 $s_i$ 的结束状态且会绕着一个环走。
故我们只需要在 $\text{ACAM}$ 上找是否存在从根节点出发的环即可。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 6e7 + 10;
int n;
struct acam {
int tot = 0;
struct Node {
int c[2], fail;
bool flag;
} trie[N];
bitset<N> vis, flag;
int get(char c) { return c - '0'; }
void insert(string s) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].c[x]) {
trie[p].c[x] = ++tot;
}
p = trie[p].c[x];
}
trie[p].flag = true;
}
void build() {
queue<int> q;
for (int i = 0; i < 2; i++) {
if (trie[0].c[i]) {
q.push(trie[0].c[i]);
trie[trie[0].c[i]].fail = 0;
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 2; i++) {
if (!trie[u].c[i]) trie[u].c[i] = trie[trie[u].fail].c[i];
else {
q.push(trie[u].c[i]);
trie[trie[u].c[i]].fail = trie[trie[u].fail].c[i];
if (trie[trie[trie[u].c[i]].fail].flag) {
trie[trie[u].c[i]].flag = true;
}
}
}
}
}
void dfs(int u) {
vis[u] = true;
flag[u] = true;
for (int i = 0; i < 2; i++) {
int x = trie[u].c[i];
if (vis[x]) {
cout << "TAK";
exit(0);
}
if (trie[x].flag || flag[x]) continue;
dfs(x);
}
vis[u] = false;
}
} ac;
void solve() {
cin >> n;
for (int i = 0; i < n; i++) {
string s;
cin >> s;
ac.insert(s);
}
ac.build();
ac.dfs(0);
cout << "NIE";
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [CF1202E](https://www.luogu.com.cn/problem/CF1202E)
::::info[题意]{open}
给定一个字符串 $t$ 和 $n$ 个字符串 $s_1,s_2,\cdots,s_n$。
令 $f(t,s)$ 表示字符串 $s$ 作为子串在 $t$ 中的出现次数。
计算 $\sum\limits_{i=1}^n\sum\limits_{j=1}^n f(t,s_i+s_j)$。$s_i+s_j$ 表示 $s_j$ 拼接在 $s_i$ 之后形成的字符串。
- 字符串中仅包含小写英文字母。
- $\sum|s_i|, t\le 2\times 10^5$。
::::
::::success[做法]
设 $m=|t|$。
拆贡献,然后考虑在 $t$ 中枚举划分点,即枚举 $x$,而 $s_i$ 是 $t[1: x]$ 的后缀,$s_j$ 则是 $t[x+1: m]$ 的前缀。
根据乘法原理,记 $f_x$ 表示是 $t[1: x]$ 的后缀的字符串个数,$g_x$ 表示是 $t[x+1: m]$ 的前缀的字符串个数,答案就是 $\sum_{i=1}^{m-1} f_ig_{i+1}$。
考虑如何求 $f$,发现在对于 $s_i$ 建出的 $\text{ACAM}$ 上匹配到一个点时,字符串个数即为在 $\text{fail}$ 树上,其到根节点的的路径上有几个字符串的终止节点。这个东西直接在 `build` 的时候可以累加预处理出来。
$g$ 的求法同理,只需要反转然后匹配就行了。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 2e5 + 10;
struct acam {
int tot = 0;
struct Node {
int son[26], val, fail;
} trie[N];
int get(char c) { return c - 'a'; }
void insert(string s) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].son[x]) trie[p].son[x] = ++tot;
p = trie[p].son[x];
}
trie[p].val++;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].son[i]) {
trie[trie[0].son[i]].fail = 0;
q.push(trie[0].son[i]);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[u].son[i]) trie[u].son[i] = trie[trie[u].fail].son[i];
else {
trie[trie[u].son[i]].fail = trie[trie[u].fail].son[i];
trie[trie[u].son[i]].val += trie[trie[trie[u].fail].son[i]].val;
q.push(trie[u].son[i]);
}
}
}
}
vector<ll> query(string s) {
int p = 0, n = s.length();
vector<ll> ans(n);
for (int i = 0; i < n; i++) {
int x = get(s[i]);
p = trie[p].son[x];
ans[i] = trie[p].val;
}
return ans;
}
} ac1, ac2;
void solve() {
string t;
int n;
cin >> t >> n;
for (int i = 0; i < n; i++) {
string s;
cin >> s;
ac1.insert(s);
reverse(s.begin(), s.end());
ac2.insert(s);
}
ac1.build();
ac2.build();
vector<ll> f1 = ac1.query(t);
reverse(t.begin(), t.end());
vector<ll> f2 = ac2.query(t);
ll ans = 0;
for (int i = 1; i < t.length(); i++) {
ans += f1[i - 1] * f2[t.length() - i - 1];
}
cout << ans << "\n";
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
// cin >> t;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [CF547E](https://www.luogu.com.cn/problem/CF547E)
::::info[题意]{open}
给定 $n$ 个串串 $s_{1\dots n}$,设 $f(i, j)$ 表示 $s_j$ 在 $s_i$ 中出现的次数。有 $q$ 次询问,给定 $l$、$r$ 和 $k$,求:
$$\sum_{i=l}^{r}f(i, k)$$
- $n,\sum|s_i|\le 2\times 10^5,q\le 5\times 10^5$。
::::
::::success[做法]
观察到直接做非常难,所以离线下来,想办法简化问题。
通过前缀和进行转化,每次询问可以变成:
$$\sum_{i=1}^{r}f(i, k)-\sum_{i=1}^{l-1}f(i,k)$$
此时我们将询问的左端点定下来了。考虑先对 $s_i$ 建出 $\text{ACAM}$。然后因为 $\text{fail}$ 树有一个重要的性质,那就是 $u$ 的子树中的状态都包含 $u$ 作为后缀。所以想到把询问丢到 $\text{fail}$ 树上去考虑。发现对于 $f(x, y)$ 这个函数,我们只需要知道有多少个 $x$ 的前缀在 $\text{fail}$ 树中的状态包含 $y$ 作为后缀就能得到其值。而包含 $y$ 的后缀的状态则显然都在 $y$ 的终止状态的子树中,所以我们可以把 $x$ 在 $\text{fail}$ 树中的状态都 $+1$,然后查询 $y$ 的子树和。
故考虑扫描线,从左往右扫,每次都将扫到的 $s_i$ 的所有状态 $+1$,然后查询只需要查终止状态的子树和即可。可以用树状数组维护 $\text{dfs}$ 序实现。
[P2414](https://www.luogu.com.cn/problem/P2414) 和此题十分相似,可以做一下。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 5e5 + 10;
template <typename T> void chkmax(T& a, T b) { a = max(a, b); }
template <typename T> void chkmin(T& a, T b) { a = min(a, b); }
int n, q, tot = 0, endpos[N];
struct Node {
int c[26], fail;
};
vector<Node> trie(N);
vector<vector<int>> G(N);
int get(char c) { return c - 'a'; }
void insert(string s, int id) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].c[x]) {
trie[p].c[x] = ++tot;
}
p = trie[p].c[x];
}
endpos[id] = p;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].c[i]) {
q.push(trie[0].c[i]);
G[0].emplace_back(trie[0].c[i]);
G[trie[0].c[i]].emplace_back(0);
}
}
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[p].c[i]) {
trie[p].c[i] = trie[trie[p].fail].c[i];
} else {
q.push(trie[p].c[i]);
trie[trie[p].c[i]].fail = trie[trie[p].fail].c[i];
G[trie[p].c[i]].emplace_back(trie[trie[p].c[i]].fail);
G[trie[trie[p].c[i]].fail].emplace_back(trie[p].c[i]);
}
}
}
}
int cnt, dfn[N], sz[N];
void dfs(int u, int fa) {
dfn[u] = ++cnt;
sz[u] = 1;
for (auto v : G[u]) {
if (v == fa) continue;
dfs(v, u);
sz[u] += sz[v];
}
}
struct info {
int k, id, w;
};
template <typename T>
struct BIT {
int n;
vector<T> bit;
BIT(int _n) : n(_n) {
bit.resize(n + 1);
}
int lowbit(int x) {
return x & (-x);
}
void update(int x, T k) {
for (int i = x; i <= n; i += lowbit(i)) {
bit[i] += k;
}
}
T sum(int x) {
T ans = 0;
for (int i = x; i; i -= lowbit(i)) {
ans += bit[i];
}
return ans;
}
T query(int l, int r) {
return sum(r) - sum(l - 1);
}
void clear() {
for (int i = 1; i <= n; i++) {
bit[i] = 0;
}
}
};
void solve() {
cin >> n >> q;
vector<string> s(n);
for (int i = 0; i < n; i++) {
cin >> s[i];
insert(s[i], i);
}
build();
dfs(0, -1);
vector<vector<info>> pos(n);
for (int i = 0; i < q; i++) {
int l, r, k;
cin >> l >> r >> k;
l--;
r--;
k--;
if (l) {
pos[l - 1].emplace_back(k, i, -1);
}
pos[r].emplace_back(k, i, 1);
}
BIT<int> bit(tot + 5);
vector<int> ans(q);
for (int i = 0; i < n; i++) {
string t = s[i];
int p = 0;
for (auto j : t) {
int x = get(j);
p = trie[p].c[x];
bit.update(dfn[p], 1);
}
for (auto [j, id, w] : pos[i]) {
ans[id] += w * bit.query(dfn[endpos[j]], dfn[endpos[j]] + sz[endpos[j]] - 1);
}
}
for (int i = 0; i < q; i++) {
cout << ans[i] << "\n";
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int t = 1;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [CF587F](https://www.luogu.com.cn/problem/CF587F)
::::info[题意]{open}
给定 $n$ 个字符串 $s_{1\dots n}$。设 $f(x, y)$ 表示 $s_x$ 在 $s_y$ 中出现的次数。有 $q$ 次询问,每次给出 $l$、$r$ 和 $k$。请求出:
$$\sum_{i=l}^{r}f(i, k)$$
- $n, q, \sum|s_i|\le 10^5$。
::::
::::success[做法]
神奇的题目。
先建出 $\text{ACAM}$,然后考虑根号分治。钦定阈值 $B$,有:
若 $|s_k|\ge B$,则这样的 $s_k$ 只有 $O(\frac{\sum|s_i|}{B})$ 个,可以直接对于每一个 $s_k$ 线性暴力地去做。即直接枚举其它串串在 $s_k$ 中的出现次数。这只需要用到 $\text{fail}$ 树的性质就行了。
否则,可以 $O(|s_k|)$ 处理每一次询问。所以直接扫描线,用树状数组维护 $s_i$ 终止节点处的子树加 $1$,然后暴力在 $\text{fail}$ 树上查 $s_k$ 每一个节点的贡献。这个东西放到 $\text{dfs}$ 序上是区间加,单点查,在树状数组上用差分维护即可。
记 $m=\sum |s_i|$,平衡一下,当 $B$ 取 $\frac{m}{\sqrt{q\log m}}$ 时最优。总时间复杂度是 $O(n\log m+
q\log q+m\sqrt{q\log m})$。
:::success[Code]
```cpp
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 1e5 + 10;
template <typename T> void chkmax(T& a, T b) { a = max(a, b); }
template <typename T> void chkmin(T& a, T b) { a = min(a, b); }
int n, q, B, endpos[N], tot, m, sum, dfn[N], sz[N], val[N];
ll ans[N];
string s[N];
vector<vector<int>> adj(N);
struct Node {
int fail, c[26];
} trie[N];
int get(char c) { return c - 'a'; }
void insert(string s, int id) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].c[x]) trie[p].c[x] = ++tot;
p = trie[p].c[x];
}
endpos[id] = p;
}
#define fail(p) trie[p].fail
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].c[i]) {
q.push(trie[0].c[i]);
fail(trie[0].c[i]) = 0;
adj[0].emplace_back(trie[0].c[i]);
}
}
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[p].c[i]) trie[p].c[i] = trie[fail(p)].c[i];
else {
q.push(trie[p].c[i]);
fail(trie[p].c[i]) = trie[fail(p)].c[i];
adj[fail(trie[p].c[i])].emplace_back(trie[p].c[i]);
}
}
}
}
#undef fail
template <typename T>
struct BIT {
int n;
vector<T> bit;
BIT(int _n) : n(_n) {
bit.resize(n + 1);
}
int lowbit(int x) {
return x & (-x);
}
void update(int x, T k) {
for (int i = x; i <= n; i += lowbit(i)) {
bit[i] += k;
}
}
T sum(int x) {
T ans = 0;
for (int i = x; i; i -= lowbit(i)) {
ans += bit[i];
}
return ans;
}
T query(int l, int r) {
return sum(r) - sum(l - 1);
}
void clear() {
for (int i = 1; i <= n; i++) {
bit[i] = 0;
}
}
};
void dfs(int u) {
sz[u] = 1;
dfn[u] = ++tot;
for (auto v : adj[u]) {
dfs(v);
sz[u] += sz[v];
}
}
void calc(int u) {
for (auto v : adj[u]) {
calc(v);
val[u] += val[v];
}
}
struct Query {
int pos, w, id;
};
void solve() {
cin >> n >> q;
for (int i = 1; i <= n; i++) {
cin >> s[i];
m += s[i].size();
insert(s[i], i);
}
build();
tot = -1;
dfs(0);
B = m / sqrt(q * __lg(m));
vector<vector<Query>> qry(n + 1), qry1(n + 1);
for (int i = 0; i < q; i++) {
int l, r, k;
cin >> l >> r >> k;
if (s[k].size() >= B) {
if (l > 1) qry[k].emplace_back(l - 1, -1, i);
qry[k].emplace_back(r, 1, i);
} else {
if (l > 1) qry1[l - 1].emplace_back(k, -1, i);
qry1[r].emplace_back(k, 1, i);
}
}
auto add = [&](ll w, int i) -> void {
int p = 0;
for (auto j : s[i]) {
int x = get(j);
p = trie[p].c[x];
val[p] += w;
}
};
for (int i = 1; i <= n; i++) {
if (!qry[i].size()) continue;
add(1, i);
calc(0);
vector<ll> pre(n + 1);
for (int j = 1; j <= n; j++) {
pre[j] = pre[j - 1] + val[endpos[j]];
}
for (auto [pos, w, id] : qry[i]) {
ans[id] += pre[pos] * w;
}
for (int j = 0; j <= tot; j++) {
val[j] = 0;
}
}
BIT<ll> bit(tot);
for (int i = 1; i <= n; i++) {
bit.update(dfn[endpos[i]], 1);
if (dfn[endpos[i]] + sz[endpos[i]] <= tot) {
bit.update(dfn[endpos[i]] + sz[endpos[i]], -1);
}
for (auto [pos, w, id] : qry1[i]) {
int p = 0;
for (auto j : s[pos]) {
int x = get(j); p = trie[p].c[x];
ans[id] += w * bit.query(1, dfn[p]);
}
}
}
for (int i = 0; i < q; i++) {
cout << ans[i] << "\n";
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int t = 1;
// cin >> t;
while (t--) {
solve();
}
return 0;
}
```
:::
::::
### [P8571](https://www.luogu.com.cn/problem/P8571)
::::info[题意]{open}
对于字符串 $x,y$,定义 $w(x,y)$ 为 $x$ 在 $y$ 中的出现次数。
给定 $n$ 个字符串 $s_{1\dots n}$,$m$ 次询问,每次询问给定 $l,r,k$,求 $\max_{i=l}^r w(s_i,s_k)$。
- $n, m\le 10^5,\sum|s_i|\le 5\times 10^5$。
::::
::::success[做法]
这题耗了我一个下午,妥妥重工业。
受到 [CF587F](https://www.luogu.com.cn/problem/CF587F) 的启发,考虑根号分治一下。设 $\sum|s_i|=m$,钦定阈值 $B$,则:
- 若 $|s_k|\ge B$,则将 $s_k$ 的节点在 $\text{fail}$ 树上标记为 $1$,然后暴力枚举每一个 $s_i$,查询其终止状态在 $\text{fail}$ 树中子树的权值和。然后用线段树维护一下询问。则这部分的时间复杂度为:$O(\frac{mn}{B}+q\log n)$。
- 若 $|s_k|<B$,发现最终答案不会超过 $B$ 且不同的答案不会超过 $2B$ 种。所以考虑对于每一个 $s_k$ 建立虚树,然后如果对于一个虚树上的点 $u$,若存在 $u$ 的一个祖先节点且该节点为询问 $i\in [l, r]$ 区间中 $s_i$ 的终止节点,则该次询问的答案至少为 $sz_u$(是虚树中的 $sz$)。故考虑扫描线,把询问挂到 $r$ 上去,每次枚举虚树中的点查答案就行了。判断是否存在 $i\in [l, r]$ 只需要维护当前 $\text{fail}$ 树中每一个节点对应的最大 $i$。所以可以用分块维护 $\text{dfs}$ 序,然后在扫描线的时候将扫到的串串结束位置的子树取 $\max$,每次询问单点查询。用 $O(\sqrt{N})-O(1)$ 分块可以做到:$O(m\log m+n\sqrt{m}+qB)$。
总时间复杂度为:$O(\frac{mn}{B}+q\log n+m\log m+n\sqrt{m}+qB)$。取 $B=\sqrt{m}$,可以做到 $O((n+q)\sqrt{m}+q\log n+m\log m)$。
代码太长,放[剪贴板](https://www.luogu.com.cn/paste/v7ddb8jb)里了。
::::
### [P4052](https://www.luogu.com.cn/problem/P4052)
::::info[题意]{open}
给定 $n$ 个字符串 $s_{1\dots n}$,需要计算有多少个长度为 $m$ 的串串 $t$ 满足 $t$ 至少包含一个 $s_i$ 作为子串。**答案对 $10^4+7$ 取模**。
- $n\le 60, m,|s_i|\le 100$。
::::
::::success[做法]
$\text{ACAM}$ 上 $\text{dp}$ 的板子。
考虑先对 $s_i$ 建出 $\text{ACAM}$,然后在上面 $\text{dp}$。设:
- $f_{i, j, 0}$ 表示 $\text{dp}$ 完 $t$ 的前 $i$ 位,当前这一位走到 $\text{ACAM}$ 上的节点 $j$ 且还不包含任意一个 $s_i$ 作为子串。
- $f_{i, j, 1}$ 则表示已经包含至少一个 $s_i$ 作为子串。
记 $fa_u$ 表示 $u$ 在 $\text{ACAM}$ 中的父亲,转移是十分容易的:
- $f_{i, j, 0}\leftarrow f_{i-1, fa_j, 0}
f_{i,j,1}\leftarrow f_{i-1,fa_j,1}+f_{i-1,fa_j,0}\times [j\ \text{is}\ \text{an}\ \text{endposition}]
注意,这里的 \text{endposition} 需要在 build 时预处理出来,因为若 j 的 \text{fail} 指针指向的状态包含 s_i ,则说明 j 也包含 s_i 。
:::success[Code]
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 2e5 + 10;
int n, m;
struct acam {
int tot = 0, mod;
struct Trie {
int son[26], fail, flag;
};
vector<Trie> trie;
acam(int _n, int _mod) : mod(_mod) {
trie.resize(_n);
}
int get(char c) {
return c - 'A';
}
void insert(string s) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].son[x]) {
trie[p].son[x] = ++tot;
}
p = trie[p].son[x];
}
trie[p].flag = 1;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].son[i]) {
trie[trie[0].son[i]].fail = 0;
q.push(trie[0].son[i]);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[u].son[i]) trie[u].son[i] = trie[trie[u].fail].son[i];
else {
trie[trie[u].son[i]].fail = trie[trie[u].fail].son[i];
trie[trie[u].son[i]].flag |= trie[trie[trie[u].son[i]].fail].flag;
q.push(trie[u].son[i]);
}
}
}
}
void add(ll& x, ll y) {
x += y;
if (x >= mod) {
x -= mod;
}
}
ll calc(int len) {
vector<vector<array<ll, 2>>> f(tot + 1);
for (int i = 0; i <= tot; i++) {
f[i].resize(len + 1);
}
for (int i = 0; i < 26; i++) {
if (trie[trie[0].son[i]].flag) {
add(f[trie[0].son[i]][1][1], 1);
} else {
add(f[trie[0].son[i]][1][0], 1);
}
}
for (int i = 1; i < len; i++) {
for (int j = 0; j <= tot; j++) {
for (int k = 0; k < 26; k++) {
if (trie[trie[j].son[k]].flag) {
add(f[trie[j].son[k]][i + 1][1], f[j][i][0]);
add(f[trie[j].son[k]][i + 1][1], f[j][i][1]);
} else {
add(f[trie[j].son[k]][i + 1][1], f[j][i][1]);
add(f[trie[j].son[k]][i + 1][0], f[j][i][0]);
}
}
}
}
ll ans = 0;
for (int i = 0; i <= tot; i++) {
add(ans, f[i][len][1]);
}
return ans;
}
};
void solve() {
cin >> n >> m;
acam ac(N, 1e4 + 7);
for (int i = 0; i < n; i++) {
string s;
cin >> s;
ac.insert(s);
}
ac.build();
cout << ac.calc(m) << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int t = 1;
// cin >> t;
while (t--) {
solve();
}
return 0;
};;;
::::
CF696D
::::info[题意]{open}
给定 n 个字符串 s_{1\dots n} 和其价值 a_{1\dots n} 。求长度不超过 l 的字符串 t 的最大价值是多少。
::::
::::success[做法]
如果 $l$ 的值域很小,则可以直接暴力 $\text{ACAM}$ 上 $\text{dp}$。但 $l$ 取到了 $10^{14}$,所以得考虑如何进行优化。
不妨先把状态和转移方程写出来。设 f_{u, i} 表示走到 \text{ACAM} 上的点 u 且当前处理的字符串长度为 i 的最大答案。转移就是刷表,w_u 是贡献,可以在建 \text{ACAM} 时顺便处理 \text{fail} 指针算出来:
f_{u,i}\leftarrow f_{fa_u, i-1}+w_u
观察到,这个转移式其实等同于从 fa_u 向 u 走过了一条边权为 w_u 的边。而求长度不超过 l 的字符串其实就相当于在 \text{ACAM} 上从根节点开始走 l 步。由此联想到邻接矩阵加矩阵快速幂。但此时应使用广义矩阵乘,每次计算的是 c_{i,j}=\max\{a_{i,k}+b_{k,j}\} 。
时间复杂度为 O(n^3\log l) 。
:::success[Code]
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using ull = unsigned long long;
using i128 = __int128;
using PII = pair<int, int>;
using PLL = pair<ll, ll>;
constexpr ll inf = (1ll << 62);
constexpr int N = 2e5 + 10;
template <typename T> void chkmax(T& a, T b) { a = max(a, b); }
template <typename T> void chkmin(T& a, T b) { a = min(a, b); }
template <typename T>
struct Matrix {
int n;
vector<vector<T>> mat;
Matrix(int _n) : n(_n) {
mat.resize(n + 1, vector<T> (n + 1));
for (int i = 0; i <= n; i++) {
mat[i][i] = 1;
}
}
Matrix(int _n, T flag) : n(_n) {
mat.resize(n + 1, vector<T> (n + 1, flag));
}
Matrix operator*(const Matrix& a) {
Matrix<T> c(n, -1);
for (int i = 0; i <= n; i++) {
for (int j = 0; j <= n; j++) {
for (int k = 0; k <= n; k++) {
if (mat[i][k] < 0 || a.mat[k][j] < 0) continue;
// cout << i << " " << k << " " << mat[i][k] << " 1\n";
// cout << k << " " << j << " " << a.mat[k][j] << " 2\n";
chkmax(c.mat[i][j], mat[i][k] + a.mat[k][j]);
}
}
}
return c;
}
Matrix qpow(ll x) const {
Matrix<T> base = *this;
Matrix<T> res = base;
x--;
while (x) {
if (x & 1) res = res * base;
x >>= 1;
base = base * base;
}
return res;
}
};
template <typename T>
struct ACAM {
int tot = 0;
struct Trie {
int son[26], fail, ans;
Trie() : fail(0), ans(0) {
memset(son, 0, sizeof(son));
}
};
vector<Trie> trie;
vector<int> a;
ACAM(int _n) {
trie.resize(_n + 1);
a.resize(_n + 1);
}
int get(char c) {
return c - 'a';
}
void insert(string s, int id) {
int p = 0;
for (auto i : s) {
int x = get(i);
if (!trie[p].son[x]) {
trie[p].son[x] = ++tot;
}
p = trie[p].son[x];
}
trie[p].ans += a[id];
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++) {
if (trie[0].son[i]) {
trie[trie[0].son[i]].fail = 0;
q.push(trie[0].son[i]);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (!trie[u].son[i]) trie[u].son[i] = trie[trie[u].fail].son[i];
else {
trie[trie[u].son[i]].fail = trie[trie[u].fail].son[i];
trie[trie[u].son[i]].ans += trie[trie[trie[u].son[i]].fail].ans;
q.push(trie[u].son[i]);
}
}
}
}
T calc(ll l) {
Matrix<T> mapp(tot, -1);
for (int i = 0; i <= tot; i++) {
for (int j = 0; j < 26; j++) {
mapp.mat[i][trie[i].son[j]] = trie[trie[i].son[j]].ans;
}
}
mapp = mapp.qpow(l);
T ans = 0;
for (int i = 0; i <= tot; i++) {
chkmax(ans, mapp.mat[0][i]);
}
return ans;
}
};
void solve() {
int n;
ll l;
cin >> n >> l;
ACAM<ll> ac(210);
for (int i = 1; i <= n; i++) {
cin >> ac.a[i];
}
for (int i = 1; i <= n; i++) {
string s;
cin >> s;
ac.insert(s, i);
}
ac.build();
cout << ac.calc(l) << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int t = 1;
// cin >> t;
while (t--) {
solve();
}
return 0;
}:::
::::
后记
给两个题单:一、二。第一个是我自己做过的一些简单 \text{ACAM} ,拜谢 fjy666。
真的爆肝了数天啊,给个赞吧!