再学串串(七):哈希,倍增 & 诱导排序与 SA-IS 算法
过去的章节
- 再学串串(一):我真的学会 KMP 了吗?评「clx201022 式的傲慢」
- 再学串串(二):AC 自动机不是自动 AC 机
- 再学串串(三):被构造自动机上计数 DP 题吓晕
- 再学串串(四):后缀是后缀的后缀是后缀的后缀
- 再学串串(五):谁会不喜欢可爱的小马(拉车)呢?
- 再学串串(六):回文自动机动自文回:)六(串串学再
目前已同步在博客园更新。
如果觉得写得好麻烦动手点个赞谢谢喵,本喵会很开心的喵。
第七站:后缀数组(Suffix Array)
后缀数组包含两个数组:
给定一个串
因为按字典序排序所以也算作是后缀排序。
一般会在一些和字典序关联较强的题目中出现。
朴素求法
简单的问题复杂化,归约到串
预处理哈希可以做到
:::info[63 pts]
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
constexpr int maxn = 1e6, sigma = 'z';
constexpr ll mod = 1e9 + 7, base = 13331;
ll pw[maxn + 1], h[maxn + 1];
string s;
int sa[maxn + 1], rk[maxn + 1];
int main()
{
cin.tie(nullptr)->sync_with_stdio(false);
cin >> s;
int n = s.size();
s = " " + s;
pw[0] = 1;
for (int i = 1; i <= n; i++) pw[i] = pw[i - 1] * base % mod;
for (int i = 1; i <= n; i++) h[i] = (h[i - 1] * base % mod + s[i]) % mod;
auto geth = [&](int l, int r) -> ll
{
return (mod + h[r] - (h[l - 1] * pw[r - l + 1]) % mod) % mod;
};
auto cmp = [&](int x, int y) -> bool // 后缀 x < 后缀 y 吗?
{
if (x == y) return false;
int len = 0, r = n - max(x, y) + 1; // LCP 长度
while (len < r)
{
int mid = (len + r + 1) >> 1;
if(geth(x, x + mid - 1) == geth(y, y + mid - 1)) len = mid;
else r = mid - 1;
}
// len == r == LCP 长度
if (max(x, y) + len == n + 1)
{
// 在相同的部分内全部相等
// n - x + 1 < n - y + 1
return x > y; // 那就看后缀长度了
}
return s[x + len] < s[y + len]; // 直接比第一个不同的字符大小
};
for (int i = 1; i <= n; i++) sa[i] = i, rk[i] = 1;
sort(sa + 1, sa + n + 1, cmp);
for (int i = 1; i <= n; i++) rk[sa[i]] = i;
for (int i = 1; i <= n; i++) cout << sa[i] << " \n"[i == n];
return 0;
}:::
很不幸,这就是朴素做法的极限了,这是因为我们把它归约为了一个更复杂的问题。(如果字符串
能不能利用一些后缀的性质呢?
倍增做法
从哈希
引理 1.1
A<B$ 当且仅当 $A_{\operatorname{LCP}(A,B)+1} < B_{\operatorname{LCP}(A,B)+1}
比较两个后缀时,可以将其都分成长度相同的两段比较(超出的部分用
那么只需要先比较前面一段子串,前一段子串相等再比较后一段子串即可。
但怎么求更小子串之间的大小关系呢?很简单,因为主串是同一个所以只要求每个起点开头的相同长度的所有子串之间的大小关系即可,而这个问题是可以递归求直到只剩单个字符的。
考虑怎样劈成更小的段。显然从中间劈开会使得要比较大小的每一段长度相等,这样会非常好处理。
经典递归转迭代,从单个字符不停倍增直到涵盖整个主串为止。
核心是上一个长度为
否则,也即以下任意一项成立
T_i>T_{i+1} 此时
i 为L 型后缀。引理 2.2(后缀类型指导排序)
若后缀
A,B 满足A_1=B_1 且A 为S 型,B 为L 型,则A>B 。可由引理 1.2 和引理 2.1 推出。
LMS 子串
LMS 的意思是 Leftmost S-type。
称满足
注意
引理 2.3
作为一个例外的边界情况。 **引理 2.4** 对于 LMS 子串 $K\ne \epsilon$,总有 $|K|>2$。 由 $*$ 型的定义可知。 **引理 2.5**(原串折半) 任意串 $T$ 中 LMS 子串的数量不超过 $\lceil \frac{n}{2}\rceil$。 根据**引理 2.4** 可知。 **引理 2.6** 一个字符串 $T$ 的所有 LMS 子串长度之和不超过 $2n$。 所有 LMS 子串间除了 $*$ 型后缀开头的第一个字符外均不交。 **引理 2.7** 若令每个字符的字典序包含它的后缀类型作为第二关键字,其中 $\text{S-type} >\text{L-type}$。那么不存在一个 LMS 子串是另一个 LMS 子串的真前缀。 设 $A$ 是 $B$ 的真前缀,因为 $A$ 以 $*$ 型结尾,根据 $*$ 型的定义则 $B$ 中出现的 $A$ 最后必然包含一个 $*$ 型在中间,这与 LMS 子串的定义矛盾。 ``` acbbccbbccbab# SLSSLLSSLLLSLS __*___*____*_* ``` (`#` 在此指代 $\epsilon$) 虽然 $\texttt{bbccb}$ 是 $\texttt{bbccba}$ 的真前缀,但是前者的最后一个 $\texttt{b}$ 是 $S$ 型,后者的最后一个 $\texttt{b}$ 是 $L$ 型。
称将
T =
mmiissiissiippii#
LLSSLLSSLLSSLLLLS
__*___*___*_____*
2 =
iissi
SSLLS
1 =
iippii#
SSLLLLS
0 =
#
S
T' =
2210引理 2.8(问题缩减)
比较 $T'$ 中字符相当于比较 $T$ 中 LMS 子串。根据**引理 2.7**,不存在一个 LMS 子串是另一个 LMS 子串的真前缀所以 $T'$ 中两个任意后缀比较相当于 $T$ 中任意两个 $*$ 型后缀比较。 比如 $T$ 中 $*$ 型后缀 $i$ 和 $j$ 比较,按 LMS 子串划分成若干段。决定大小关系的即为相同段后一个个不同段。选用 LMS 子串的核心是不存在任意一个 LMS 子串为另一个 LMS 子串的真前缀:这样能够保证要么就在一段内的比较要么决出结果,要么扫过的前缀全等,不会出现虽然未得出结果但是扫过的前缀不全等的问题。 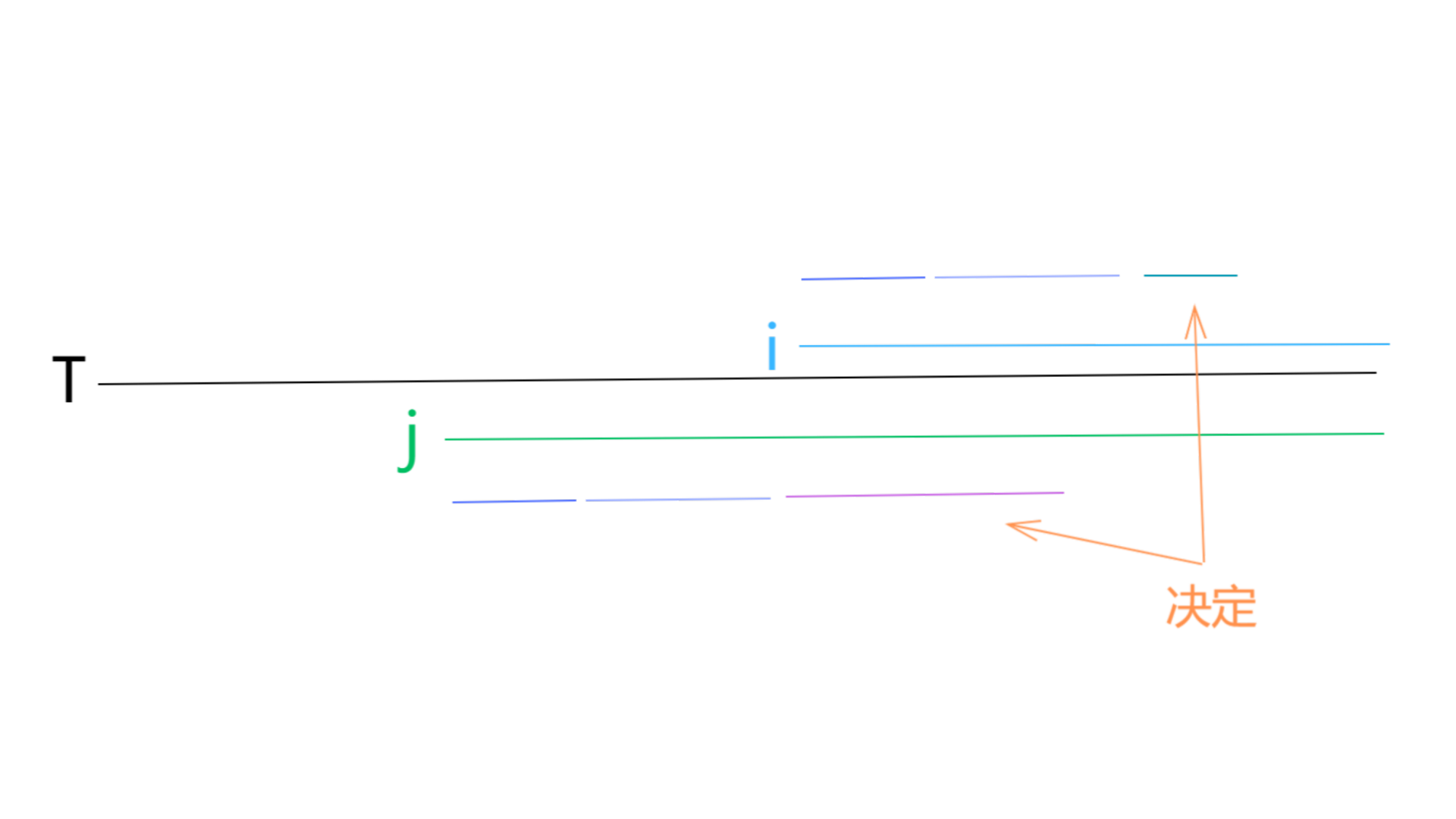
需要注意的是这里只是
诱导排序与 SA - IS 算法
设
自己手玩几把可以发现后缀排序时总是首字母相同的后缀相邻(显然)。
#
aaaab#
aaab#
aab#
aabaaaab#
ab#
abaaaab#
b#
baaaab#据引理 2.2 可知首字母相同的情况下总是类型相同的后缀相邻。将每种字符和两种类型看作关键字就可以计数排序了。
但你会发现首字母与类型均相同的后缀之间大小不好判,现在就要利用
用
开始前记得初始化
sa 数组以及确定S 型桶L 型桶的起始位置,其中S 型桶逆序排放。(计数排序基操)
- 按顺序扫一遍
sa' 的* 型后缀,依次放入sa 中。- 顺序遍历
sa ,然后对于所有非空的sa_i 且sa_i-1 是L 型的依次放入sa 中。- 重新确定
S 型起始位置,准备重排* 型后缀。逆序遍历sa 同时将sa_i-1 是S 型的依次放入sa 中。整体流程有点像基数排序的说。
对于
对 LMS 子串的排序,诱导排序流程中 1. 改为将
定义后缀
接下来证明改动后每一步的正确性。
- 桶的排列按照字典序保证了放入后的有序和首个字符、后缀类型不同时有序。
- 假设放入第
k+1 个L 型 LMS 前缀i 时前面放入的k 个L 型 LMS 前缀保持有序。此时只需要考虑首字母相同的其他L 型 LMS 前缀即可。假设存在j 的 LMS 前缀比i 的 LMS 前缀大,因为首字母相同,所以j+1 的 LMS 前缀比i+1 的 LMS 前缀大。与假设矛盾。根据数学归纳法可知在k=0 时情况成立,推广到任意k 。 - 类似,但这时
i 应理解为从其右边第一个* 型后缀开头开始,一步一步向左加字符得到的 LMS 子串。换句话说此步后所有的 LMS 子串就已经完成排序了。
时间复杂度是
:::success[SA-IS]
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
template<typename sigmatype = char>
vector<int> SAIS(const basic_string<sigmatype> &T, int Sigma)
{
int n = T.size(); // 包含末尾空字符的长度
if (n <= 1) return {0};
vector<bool> isStype(n + 1);
vector<int> pos(n + 1), name(n + 1, -1), sa(n, -1);
vector<int> bucket(Sigma + 1, 0), bucketL(Sigma + 1), bucketS(Sigma + 1);
auto isLMSchar = [&](int x) -> bool
{
return x > 0 && isStype[x] && !isStype[x - 1];
};
auto equal_substring = [&](int x, int y) -> bool
{
if (x == y) return true;
while (true) {
if (T[x] != T[y]) return false;
++x, ++y;
bool x_is_lms = isLMSchar(x);
bool y_is_lms = isLMSchar(y);
if (x_is_lms || y_is_lms)
{
return x_is_lms && y_is_lms;
}
}
return false;
};
auto induced_sort = [&]() -> void
{
for (int i = 0; i < n; i++)
{
if (sa[i] > 0 && !isStype[sa[i] - 1])
{
sa[bucketL[T[sa[i] - 1]]++] = sa[i] - 1;
}
}
bucketS[0] = 0;
for (int i = 1; i <= Sigma; i++) bucketS[i] = bucket[i] - 1;
for (int i = n - 1; i >= 0; i--)
{
if (sa[i] > 0 && isStype[sa[i] - 1])
{
sa[bucketS[T[sa[i] - 1]]--] = sa[i] - 1;
}
}
};
// 1. 确定后缀类型
isStype[n] = 1; // 空字符是 S 型
for (int i = n - 1; i >= 0; i--)
{
if (T[i] < T[i + 1]) isStype[i] = 1;
else if (T[i] > T[i + 1]) isStype[i] = 0;
else isStype[i] = isStype[i + 1];
}
// 2. 寻找 LMS 字符并放入桶中初步排序
int cnt = 0;
for (int i = 1; i <= n; i++)
{
if (isStype[i] && !isStype[i - 1]) pos[cnt++] = i;
}
// 计算桶边界
for (int i = 0; i < n; i++) bucket[T[i]]++;
bucketL[0] = bucketS[0] = 0;
for (int i = 1; i <= Sigma; i++)
{
bucket[i] += bucket[i - 1];
bucketL[i] = bucket[i - 1];
bucketS[i] = bucket[i] - 1;
}
for (int i = 0; i < cnt; i++) {
sa[bucketS[T[pos[i]]]--] = pos[i];
}
// 3. 第一次诱导排序
induced_sort();
// 4. 离散化命名
int lstLMS = -1, namecnt = 0;
bool flag = false;
for (int i = 0; i < n; i++) {
if (isLMSchar(sa[i])) {
if (lstLMS != -1) {
if (!equal_substring(sa[i], lstLMS)) ++namecnt;
else flag = true;
} else {
namecnt = 0;
}
name[lstLMS = sa[i]] = namecnt;
}
}
name[n] = 0;
// 5. 生成 T1 并递归求解
basic_string<int> T1(cnt, 0);
int post = 0;
for (int i = 0; i <= n; i++) {
if (name[i] != -1) {
T1[post++] = name[i];
}
}
vector<int> sa1(cnt);
if (!flag) {
for (int i = 0; i < cnt; i++) sa1[T1[i]] = i;
} else {
sa1 = SAIS<int>(T1, namecnt + 1);
}
// 6. 最终诱导排序
fill(bucket.begin(), bucket.end(), 0);
for (int i = 0; i < n; i++) bucket[T[i]]++;
bucketL[0] = bucketS[0] = 0;
for (int i = 1; i <= Sigma; i++)
{
bucket[i] += bucket[i - 1];
bucketL[i] = bucket[i - 1];
bucketS[i] = bucket[i] - 1;
}
fill(sa.begin(), sa.end(), -1);
for (int i = cnt - 1; i >= 0; i--) sa[bucketS[T[pos[sa1[i]]]]--] = pos[sa1[i]];
induced_sort();
return sa;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
string s;
cin >> s;
// 关键修复:手动追加一个值为 0 的空字符,确保最后一个后缀是 S 型
s.push_back(0);
// 'z' 的 ASCII 为 122,加上空字符 0,值域设为 123 足够安全
auto sa = SAIS(s, 123);
// 输出结果,跳过索引 0 (即空字符的位置),并将 0-indexed 转为 1-indexed
for (size_t i = 1; i < sa.size(); i++)
{
cout << sa[i] + 1;
if (i != sa.size() - 1) cout << " ";
}
cout << "\n";
return 0;
}
/*
AI 使用声明:此段代码使用 Qwen3.7 - 千问辅助调试
但文章原有文字内容和代码主体均为纯人工写就
神必 Lambda 码风也是人工的,AI 只是辅助调试用
*/:::
例题什么的后面会再开一篇专题,毕竟到这里已经超过一万字符(算上代码)了。
参考资料
- 《诱导排序与 SA - IS 算法》
- Nong, Ge; Zhang, Sen; Chan, Wai Hong (2009): Linear Suffix Array Construction by Almost Pure Induced-Sorting
- 《还在写倍增后缀数组? SA-IS算法了解一下~》
创作声明
本文遵循 CC BY-NC-SA 4.0 协议。
保证本文文字说明部分未使用 GenAI 工具辅助创作。
转载例如下:
[原文](https://www.luogu.com.cn/article/73yg70al)作者为 [clx201022](https://www.luogu.com.cn/user/552688),转载人保证会遵循 [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh-hans) 协议:以适当的方式署名,不以盈利为目的进行转载,并以相同方式共享。