浅谈树状数组的优化及扩展
逆流之时
·
·
算法·理论
前置知识:
洛谷日报的两篇树状数组进阶:
https://www.luogu.org/blog/Chanis/super-BIT
https://www.luogu.org/blog/Chanis/super-BIT2
先放一张普通树状数组的图片,下面都会有用。
树状数组本身是占空间最小的区间数据结构之一,因为普通树状数组的空间规模总为n。也可以证明维护区间和的数据结构空间最小规模为n,因为区间数据结构的每个节点都相当于一个方程,形如sum_i=a_{x1}+a_{x2}+a_{x3}+...,而如果方程的个数不到n个,则方程有无数个解。其他数据结构如线段树等,虽然每次修改、查询等操作也都是O(logn),空间也是O(n),但都比不上树状数组代码短,方便迭代,常数极小的优点。
只有什么时候有大佬做出一个不依赖区间的的数据结构,或一个不依赖二进制拆分区间的数据结构,并且能解决区间问题,才可能突破目前树状数组的效率。
在这之前,我们就先优化一下树状数组吧。
0.树状数组预处理
(其实我之前期望还不熟,之前有的是依靠实验数据口胡的,还有写到最后忘记了前面在写什么的。非常感谢@ComeIntoPower 很用心地帮助我完善了证明,并提了一些建议)
树状数组本来有O(n)的预处理,但我看到还是很多人在用O(nlogn)的预处理方法,原来的洛谷日报也没有,所以这里再讲一下:
树状数组的O(n)建树思想简单来说就是把所有j+lowbit(j)=i的节点a[j](j<lowbit(i))累加到a[i]中。有两种建树方法,一种类似于动态规划的填表法,比较易懂:
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
for(int j=1;j<lowbit(i);j*=2){
a[i]+=a[i-j];
}
}
但这样建树的算法复杂度较难看出,所以我们可以用类似刷表法的建树方法来分析:
for(int i=1;i<=n;i++){
scanf("%lld",&x);
a[i]+=x;
if(i+lowbit(i)<=n)a[i+lowbit(i)]+=a[i];//注意这里的条件
}
前面的洛谷日报中第一期介绍区间最值建树方法时,就把第一种写法误说成是O(nlogn)了。这可能也是很多人的误区。
这里再提几个容易搞混的有关树状数组的期望值:
(最好结合树状数组那幅图理解)
(为了方便计算,假设下面的n是2的整数次方)
-
对x\in [1,n],有lowbit(x)的期望值为O(log_2n)。
证明:\sum_{i=1}^nlowbit(i)=(log_2n+2)\times \frac{n}{2}=O(nlogn)。这就是为什么n次upd操作建树的复杂度是O(nlogn)的原因。
-
对于d[i](d[i]是树状数组节点i的深度)的期望值\frac{1}{n}\sum_{i=1}^{n}d[i],E=O(\frac{1}{n}\sum_{i=1}^{\log_2 n} (\frac{n}{2^{i}})\times (log_2n-i+2))=O(log_2n)。事实上,\frac{1}{n}\sum_{i=1}^{n}d[i]=\frac{1}{n}\sum_{i=1}^{\log_2 n} (\frac{n}{2^{i}})\times (log_2n-i+2)=log_2n。也可以这么算:\frac{1}{n}\sum_{i=1}^{n}d[i]=\frac{1}{n}\sum_{i=1}^{n}(log_2\frac{n}{lowbit(i)}+1)=log_2n。
-
对i\in [1,n],有log_2lowbit(i)+1的期望值为O(1)。
证明:设n1=n\times2,则\sum_{i=1}^{n1}log_2lowbit(i)=\sum_{i=1}^{n}log_2lowbit(i)\times2+1。边界为n=1,log_2lowbit(1)+1=1。
也可以直接列式:从节点按照lowbit(i)的值可以分为几类这个角度出发,对每个常数a,统计lowbit(i)=a的i的个数,当n趋于无穷大时,就有E\leq\frac{1}{n}\sum_{i=0}^{\infty} (\frac{n}{2^i}-\frac{n}{2^{i+1}})(i+1)=\sum_{i=1}^{\infty}\frac{i}{2^{i}}= 2
这也解释了为什么第一种O(n)建树方法是O(n)的,而且可以转成第二种建树方法。
-
第一篇树状数组的洛谷日报里面有一个求区间最值的函数:
void add(int pos,int x){
a[pos]=x;
while(pos<=n){
c[pos]=a[pos];int t=lowbit(i);
for(int j=1;j<t;j*=2) c[i]=max(c[i],c[i-j]);
pos+=lowbit(pos);
}
}
看了上面的内容,可能有人会觉得这个函数也是logn的时间复杂度。但这个函数还是log^2n的期望时间复杂度。
证明:假设对[1,n]的所有节点都做一次更新,则节点i的被修改次数为lowbit(i),每次修改所需的取最值(赋值)次数为log_2lowbit(i)+1。对i\in [1,n],有sum_n=\sum_{i=1}^{n}lowbit(i)\times [(log_2lowbit(i)+1)]。结果为sum_n/n=O(log^2n)。
具体计算方法:设n1=n\times 2,n=2^k,sum_n=\sum_{i=1}^{n}[lowbit(i)\times (log_2lowbit(i)+1)],则sum_{n1}=sum_n\times 2+(k+3)\times 2^k。然后推出一般情况下n1=n\times 2^x时的情况,按高中的等差数列化简方法,可以得到最终结果。我们也可以换一种想法,像上面那样把节点按lowbit(i)的值分类统计,总共可以分成log_2n类,就可以看出两类想法会殊途同归,都可以得到E=O(\frac{1}{n}\sum_{i=0}^{\log_2 n} (\frac{n}{2^i}-\frac{n}{2^{i+1}})2^i\times i)=O(\frac{(\log_2n+1)\log_2n}{4})=O(\log_2^2 n)
也可以先实验。下面是实际计算得出的sum_n/n的结果:
1e9:235.106305904
1e6:106.767359
1e3:27.901
可以看出期望值基本按照log_2^2n的速度增长。
当我们得出结论时,我们也可以用特殊数据算一下sum_n:
16:160
32:432
验算,发现对我们两种推导的方法都符合,也可以多造几组数据测一下。
最开始时,我也是通过观察树状数组的图形寻找计算方法的,逐渐发现可以通过每次将树状数组规模扩大两倍,并把一个长度为n的矩形换成一个长度为n1的矩形来发现一般情况的规律。
1.查询优化
树状数组查询区间和的方式是求前缀和,然后算sum(r)-sum(l-1)。但这样子可能造成区间重复运算。比如计算sum(7)-sum(5),sum(7)计算了a_4+a_6+a_7,sum(5)计算了a_4+a_5。两者都计算了s_4,很明显我们可以不计算a_4以优化程序,因为它最终可以被消去。
这个优化的写法很简单,但要算出优化效果还要再证明一些定理。
int query(int l,int r){
l--;
int sum=0;
while(r>l)sum+=a[r],r-=lowbit(r);
while(l>r)sum-=a[l],l-=lowbit(l);
return sum;
}
这里我们不断将r与l-1互相逼近,用以取不用重复计算的那一部分。那为什么两者都逼近一次就可以了呢?
证明:设r在二进制下有x位,l-1有y位,他们的最大公共部分有z位,则r的第x-z位与l-1的第y-z位不同。因为r>l-1,所以如果z \neq 0,则x=y,且r的第x-z位为1,l-1的第y-z位为0。则在r不断减去lowbit(r)时,在减去他的第x-z位之前都有r>l-1。所以当r减去第x-z位之后,r \le l-1。之后的过程对l-1同理。
关于优化程度的计算式,我为了加快速度,直接写程序算了n=2^k(k \in Z)的情况,然后上oeis.org搜。得出:
对于长度为n(n=2^k,k \in Z)的树状数组的\frac{n\times(n+1)}{2}种区间,用了这里的区间优化后,加法操作减少的次数为
\frac{n^2-(log_2n+1)\times n}{4}
看起来是一个大数字,但用结果除以\frac{n\times(n+1)}{2}后,在n=10^5时结果为0.499340,平均每两次求区间和操作会优化一次。
不过,这个优化同时减少的调用函数等的次数也会为程序的常数带来一定优化。
2.k叉树状数组
(这一部分的树状数组查询操作均指区间查询,修改操作均指单点修改)
由于我们平常的树状数组都是基于二进制维护节点之间的关系的,所以我们可以想办法把树状数组变成其他类型的树,来对树状数组的常数稍作改变。
为方便比较,先列出二叉树状数组的理论时间(带常数):
查询理论时间:log_2n
修改理论时间:log_2n
最容易想到的就是三叉树状数组。
查询理论时间:2\times log_3n
修改理论时间:log_3n
他大概长这样:
我们看出,三叉树状数组的查询理论上比二叉树状数组慢,但修改更快一些。而在实际使用时,除了修改与查询一样多的题目,更多的是查询比修改多(毕竟只有查询有输出)。所以,如果有k叉树状数组(k<2),那么就能做到查询比二叉树状数组快。
这样,只能考虑k不为整数的情况。
区间树在某种意义上也可以构造出这样的结构。
如图,就是一棵以黄金分割(斐波那契数列)为基础的树状数组,可以把k看做1.618。
节点的区间长度可以这样计算:
for(int i=2;i<=30;i++)f[i]=f[i-1]+f[i-2];//斐波那契数列
a[1]=1;
a[2]=2;
for(int i=3;i<=n;i++){//这里可以在n<=8的范围内模拟一下
a[i]=a[i-f[now]];
if(a[i]==now-1)a[i]=++now;
}
虽然这样的树层数增多,影响修改的效率,但如果查询比修改多,这样的树状数组就能拥有理论上更小的常数。
我们也得到了这样的结论:对于k叉树状数组,k越大,查询越慢,修改越快;k越小,查询越快,修改越慢。
当然,实际应用中还是最好用二叉树状数组,由于有位运算,所以二叉树状数组的代码量最少,而且实际常数往往更小。而其他树状数组只能通过预处理一个数组来实现它们的类lowbit运算。
我们也同时发现树状数组和很多数据结构都有联系,其他很多数据结构实质是树状数组的变体,或树状数组是一些其他数据结构的结合:
$k=n$时,查询$O(n)$,修改$O(1)$,就是普通的暴力;
$k=\sqrt n$时,查询$O(\sqrt n)$,修改$O(1)$,即一个分块;
同时,我们也发现如果适当地缩小分块每层的节点数量而增加层数,可以在极小地增大单点修改的时间复杂度(都是$O(1)$)的同时大规模缩小部分区间操作的时间复杂度。(比如把分块变为4层,每个节点下面有$\sqrt[4]n$个节点)
$k=1$时,查询$O(1)$,修改$O(n)$,就是没有优化的前缀和。
树状数组也可以看成是优化后的动态前缀和或差分。
树状数组还是在线段树的基础上减少了一半线段树的节点(所有非叶节点的右儿子),只保留前缀部分以提高效率的数据结构。
其实对于线段树也可以这样划分区间:
黄金分割划分比较简单,只要把`mid=(l+r)/2`改成`mid=l+(r-l)*0.618`就可以了。这样的线段树查询更快,不过可能占用更大空间,因为线段树层数会更多。这样的线段树可能还有其他功能,比如这样的线段树就是左偏的。
三叉线段树也满足前面类似三叉树状数组的性质:查询较慢,修改较快。而且三叉线段树也有层数少,节点个数少的优点。
### 3.树状数组加延迟标记
可能很多人初学树状数组和线段树时都会试着把树状数组与线段树的延迟标记结合在一起。一般可能会想到对每一个节点建立一个延迟标记(如最前面的图),但很快就发现延迟标记每次下传会达到$logn$的复杂度,这样子的所有查询操作就都是$log^2n$的,于是就放弃了。
但是,其实我们可以像线段树一样建立延迟标记,即对每个节点和它们右边的空白位置都建立一个延迟标记。
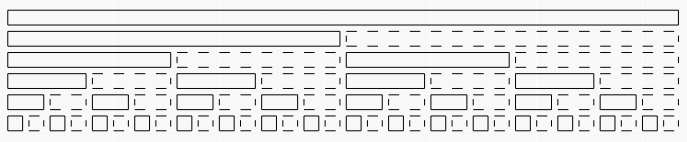
如图,所有实线矩形代表原树状数组,所有实线矩形和虚线矩形代表要建立延迟标记的位置。代码中用$add[N][2]$表示延迟标记,其中$add[x][0]$表示实线节点$x$的标记,$add[x][1]$表示节点$x$的右边兄弟虚线节点的标记。
我们把update和query函数都像树状数组一样拆成两部分:$update(l-1,x)$和$update(r,x)$。更新比较简单,就是先对区间刚好覆盖到的节点修改+标记延迟标记,然后对覆盖了一部分的区间修改一下,可以看出对于后面那步我们只需要从树状数组中被修改且深度最大的节点开始(就是$a[r]$或$a[l-1]$,因为把区间$[1,n]$拆成树状数组的节点,这些节点代表的长度总是递减的,深度也是递增的),然后一直往上走就可以了。可以模拟一下这个过程:从最深那个节点$x$沿着$x+=lowbit(x)$向上走,总是可以走遍图中区间$[1,x]$上方的所有节点。(其实这里我不太会非常严谨地证明)
而查询时就需要用延迟标记的$pushdown$操作。具体可以从根节点出发,一直往树状数组中要被累加且深度最大的节点走,同时$pushdown$,走到为止。(同样我还不会严谨地证明,也可能会补)
不管怎么样,代码已经通过对拍和洛谷测试了。下面是洛谷【模板】线段树1的代码:
```cpp
#include<cstdio>
typedef long long ll;
const int N=100005;
int n,m,l,r,op,lg=1;
ll x;
ll a[N],add[N][2];
inline int lowbit(int x){return x&(-x);}
void push_down(int x,bool d){
if(x>n||x<1||!add[x][d])return ;//这里记得特判
if(x&1){add[x][0]=add[x][1]=0;return ;}
if(d==0){
int x1=x-lowbit(x)/2;
a[x1]+=add[x][0]*lowbit(x1);
add[x1][0]+=add[x][0];
add[x1][1]+=add[x][0];
add[x][0]=0;
}
else{
int x1=x+lowbit(x)/2;
a[x1]+=add[x][1]*lowbit(x1);
add[x1][0]+=add[x][1];
add[x1][1]+=add[x][1];
add[x][1]=0;
}
}
void upd(int x,ll v){
if(!x)return ;
for(int x1=x;x1;x1-=lowbit(x1)){
a[x1]+=v*lowbit(x1);//正常累加
add[x1][0]+=v;//我第一次写的时候调了好久才发现我延迟标记忘写了
}
for(int x1=x+lowbit(x);x1<=n;x1+=lowbit(x1)){
a[x1]+=v*(x-(x1-lowbit(x1)));
}
}
ll query(int x){
if(!x)return 0;
ll ans=0;
for(int x1=lg;x1!=x;){
if(x1<x)push_down(x1,1),x1+=lowbit(x1)/2;//这里的x1有可能有时会超出n,所以push_down要特判
else push_down(x1,0),x1-=lowbit(x1)/2;
}
for(;x;x-=lowbit(x))ans+=a[x];//正常累加
return ans;
}
void build(){
scanf("%d",&n);
scanf("%d",&m);
//memset(a,0,sizeof(a));
//memset(add,0,sizeof(add));
ll x;
for(int i=1;i<=n;i++){
scanf("%lld",&x);
a[i]+=x;
if(i+lowbit(i)<=n)a[i+lowbit(i)]+=a[i];//注意这里要防越界
}
}
int main(){
build();
while(lg*2<=n)lg*=2;
while(m--){
scanf("%d%d%d",&op,&l,&r);
switch(op){
case 1:
scanf("%lld",&x);
upd(l-1,-x);
upd(r,x);
break;
case 2:
printf("%lld\n",query(r)-query(l-1));
break;
}
}
return 0;
}
```
有了延迟标记后,树状数组有了这样的优点:
1. 空间小。普通线段树至少需要$8n$的空间存线段树和延迟标记两个数组,同时还需要不小的空间递归和存函数参数。而树状数组和延迟标记只需要$3n$空间。数据结构的操作越多,这一点就越显著。
2. 常数小。树状数组天生自带迭代和位运算两个常数最小的操作,比递归的线段树好很多。
3. 应用更广泛。众所周知,原始线段树只有单点修改和区间查询两个操作,但可以经过扩展后用于平衡树、区间加+区间求和等操作。但有了延迟标记后,我们就可以用区间操作了。这样我们就可以实现基本具有线段树所有功能的树状数组了。(其他一些满足区间可并性而不满足区间可减性的操作,第一篇洛谷日报谈到过,而且上面也做了实验,虽然这些操作是$O(log^2n)$的,但在OI中树状数组的小常数可以使这一点被忽略)所以如果线段树常数相对大很多,树状数组就可以比线段树和zkw线段树快很多。
4. 易学。虽然上面的代码达到了1.4k,而标准线段树(【模板】线段树1中的)大约是1.6k。但上面的$pushdown$函数很容易缩减(这里不缩是为了代码思路更清楚)。而如果线段树把所有操作写成函数还会有$pushup$等操作。另外很多人都先学树状数组,所以学了基本的树状数组后就可以先学这样的树状数组来暂时代替线段树了。
同样,我们也可以按照类似的方法把zkw线段树改写成类似的形式:建立$a[N][2]$表示原数组,延迟标记也按类似的方法建立。这样也可以做到空间零浪费,而且更方便用$lowbit(x)$的常数小的优点优化zkw线段树。这个结构还可以同时兼容树状数组与zkw线段树的操作,达到高效通用双重优点,双倍快乐。~~虽然实际用起来过于花里胡哨,还不如放弃常数用普通线段树~~
还有一种能保证树状数组的区间最值等操作的复杂度的方法:建立两个树状数组,一个是前缀树状数组,一个是后缀树状数组。这样会使修改的常数放大到原来的两倍(但还是很小),但区间最值等操作的复杂度就变成了$O(logn)$。这样的树状数组就像一棵线段树,但还是可以用树状数组的方式写,而且具备上面的优点。
### 4.可持久化树状数组
既然树状数组能通过延迟标记模仿线段树,那么我们想到,我们习惯用动态开点线段树实现可持久化数组等,所以树状数组应该也可以动态开点实现可持久化。
还是看最上面那张图,我们要实现动态树状数组,就要确定节点间的父子关系。
怎么确定?
我们把节点$i$的左儿子设为$i-lowbit(i)/2$,把其右儿子设为$i+lowbit(i)/2$。对于有的情况下的根节点可能不满足,如$n=10$时的8号节点(8号节点为根节点,一棵可持久化树状数组的根节点为$2^{\lfloor log_2n \rfloor}$)。我们可能会想到把它的右儿子设为10号节点(反正本来10号节点也没有父亲)。但实际情况中,为了减少特判,我们会建立一些额外的节点来弥补空缺。比如在这里我们可以建立编号为12的节点,作为8号节点的右儿子和10号节点的父亲。
这样,我们就得到了一个可持久化树状数组(初始时,我们的空间规模就是可持久化线段树的$1/2$)。修改和查询时时我们只需要从根节点出发,往目标的位置走就行了。注意,因为对节点的左右儿子的定义不同,所以这里的“往目标的位置走”与上面的延迟标记树状数组的走法不一样,应该分开理解。
可持久化树状数组依然很高效。我们上面推导了$d[i](i\in [1,n])$的期望值为$log_2n$,而可持久化线段树的$d[i](i\in [1,n])$期望值为$log_2n+1$。比如在P3919 【模板】可持久化数组 一题中,$m=10^6$,这样我们的时间规模就比可持久化线段树减少了$10^6$,空间规模减少了$1.5 \times 10^6$。因为每个节点有左右儿子和权值3个信息,而修改操作的期望次数为$m/2$。
同时,可持久化树状数组的查询操作与可持久化线段树比起来常数小很多。可持久化树状数组的节点$i(i\in [1,n])$的查询操作次数为$log_2\frac{n}{lowbit(i)}+1$,则$i\in[1,n]$查询的期望规模也为$\frac{1}{n}\sum_{i=1}^{n}{log_2\frac{n}{lowbit(i)}+1}=\frac{1}{n}\sum_{i=1}^{n}d[i]=log_2n$(最前面证明过了),而可持久化线段树的查询期望规模为$log_2n+1$。明显可持久化树状数组常数小。
看似只有几百万的规模优化,但四舍五入,又是一个亿啊。
毕竟本来普通树状数组和线段树的修改和查询的时间复杂度也一样。
~~洛谷评测机貌似可以玄学评测,玄学优化?我的迭代树状数组跑得比递归的线段树还慢~~
下面给出代码。看似容易写的可持久化树状数组细节极多,导致我调了5小时。有递归和迭代两种版本供参考和理解。其中迭代的build函数是细节最多的,而且有4种情况。
p表示当前节点在实际代码中的数组中的位置,x表示目标节点的编号,v表示当前节点的编号。节点的编号在这里指节点代表的一棵普通树状数组上的一个节点的编号,这里最好结合代码和图片理解一下。
```cpp
#include<cstdio>
const int N=1000010;
int n,m,rtsize=1,tot;
int root[N];
int val[N*20],lc[N*20],rc[N*20];
inline int lowbit(int x){return x&(-x);}
#define div
#ifdef div
//递归版本
int build(int x){
int p=++tot;
if(x%2==0)lc[p]=build(x-lowbit(x)/2);
if(x<=n)scanf("%d",&val[p]);
if(x%2==0&&x<n)rc[p]=build(x+lowbit(x)/2);
return p;
}
int upd(int p,int x,int v,int k){
if(x==v){val[++tot]=k;lc[tot]=lc[p];rc[tot]=rc[p];return tot;}
int lastp=p;
val[++tot]=val[p],p=tot;
if(x<v)lc[p]=upd(lc[lastp],x,v-lowbit(v)/2,k),rc[p]=rc[lastp];
else rc[p]=upd(rc[lastp],x,v+lowbit(v)/2,k),lc[p]=lc[lastp];
return p;
}
int query(int p,int x,int v){
if(x==v)return val[p];
else if(x<v)return query(lc[p],x,v-lowbit(v)/2);
else return query(rc[p],x,v+lowbit(v)/2);
}
#else
//迭代版本
int build(){
while(rtsize*2<=n)rtsize*=2;
while(++tot<=n){
scanf("%d",&val[tot]);
lc[tot]=tot-lowbit(tot)/2;
rc[tot]=tot+lowbit(tot)/2;
}
tot--;
int v=rtsize,p=rtsize;
while(n!=v){
//printf("%d\n",lowbit(v));
if(v+lowbit(v)/2<=n)rc[p]=v+lowbit(v)/2,v+=lowbit(v)/2,p=rc[p];
else if(v<n)rc[p]=++tot,v+=lowbit(v)/2,p=rc[p];
else if(v-lowbit(v)/2>n)lc[p]=++tot,v-=lowbit(v)/2,p=lc[p];
else lc[p]=v-lowbit(v)/2,v-=lowbit(v)/2,p=lc[p];
}
return rtsize;
}
void upd(int p,int x,int v,int k){//bp是原版本,ap是新版本
int bp=p,ap=++tot;
while(x!=v){
//printf("%d\n",v);
val[ap]=val[bp];
if(x<v)lc[ap]=++tot,rc[ap]=rc[bp],v-=lowbit(v)/2,bp=lc[bp];
else rc[ap]=++tot,lc[ap]=lc[bp],v+=lowbit(v)/2,bp=rc[bp];
ap=tot;
}
val[ap]=k;
lc[ap]=lc[bp];//
rc[ap]=rc[bp];//这里最后也要复制一份 (因为此时的最终节点不一定是叶子结点,不同于动态线段树)
}
int query(int p,int x,int v){
while(x!=v){
if(x<v)p=lc[p],v-=lowbit(v)/2;
else p=rc[p],v+=lowbit(v)/2;
}
if(val[p]==0)printf("%d %d\n",p,tot);
return val[p];
}
#endif
int main(){
scanf("%d%d",&n,&m);
#ifdef div
while(rtsize*2<=n)rtsize*=2;//普通树状数组上根节点编号根节点
root[0]=build(rtsize);
#else
root[0]=build();
#endif
//for(int i=1;i<=8;i++)printf("%d %d %d\n",lc[i],rc[i],val[i]);
//printf("%d\n",tot);
for(int i=1;i<=m;i++){
int op,id,x,k;
scanf("%d%d%d",&id,&op,&x);
switch(op){
case 1:
scanf("%d",&k);
root[i]=tot+1;
upd(root[id],x,rtsize,k);
break;
case 2:
printf("%d\n",query(root[id],x,rtsize));
root[i]=root[id];//这里复制的是root[id],我调到最后才发现
break;
}
}
return 0;
}
```
可持久化树状数组同样可以实现可持久化线段树的静态区间第k小等操作。因为 我自己也想了挺久,这里说一下:
加一个$sum$数组,和主席树的$sum$数组差不多,然后像主席树一样顺着$sum$往下找。
至此,树状数组已经基本可以实现线段树的所有操作。
最后介绍一下我的画图方法:
(我的主页也有这些)
[几何小工具(用的时候要先随便在图上面点一个点,从第二行输入自己造的数据,再删掉这个点,不然自己造的数据绘制出来的图会乱,非常玄学)](https://csacademy.com/app/geometry_widget/)
[Waifu2X,用来提高截图像素 ~~这个网站通过机器学习放大galgame的图片像素得到了很好用的提高图片像素的算法,你也可以顾名思义~~](http://waifu2x.udp.jp/)
以及我用来大规模作图的数据生成器:(包含3种k叉树状数组及延迟标记树状数组)
```cpp
#include<cstdio>
#include<cmath>
const int N=500005;
int a[N];
int f[100]={1,1};
int n=32;
#define tri
#ifdef bin//二叉树状数组
int main(){
freopen("tree.out","w",stdout);
for(int i=1;i<=n;i++){
a[i]=log(i&(-i))/log(2);
printf(
"Polygon\n"
"%d %d\n"
"%d %.1lf\n"
"%.1lf %.1lf\n"
"%.1lf %d\n"
"...\n",
i-(i&(-i)),a[i],
i-(i&(-i)),a[i]+0.7,
i-0.3,a[i]+0.7,
i-0.3,a[i]
);
}
return 0;
}
#elif defined(fib)//斐波那契树状数组
int main(){
freopen("tree.out","w",stdout);
int now=2;
for(int i=2;i<=30;i++)f[i]=f[i-1]+f[i-2];
a[1]=1;
a[2]=2;
for(int i=1;i<=2;i++){
printf(
"Polygon\n"
"%d %d\n"
"%d %.1lf\n"
"%.1lf %.1lf\n"
"%.1lf %d\n"
"...\n",
i-f[a[i]],a[i],
i-f[a[i]],a[i]+0.7,
i-0.3,a[i]+0.7,
i-0.3,a[i]
);
}
for(int i=3;i<=n;i++){
a[i]=a[i-f[now]];
if(a[i]==now-1)a[i]=++now;
printf(
"Polygon\n"
"%d %d\n"
"%d %.1lf\n"
"%.1lf %.1lf\n"
"%.1lf %d\n"
"...\n",
i-f[a[i]],a[i],
i-f[a[i]],a[i]+0.7,
i-0.3,a[i]+0.7,
i-0.3,a[i]
);
}
return 0;
}
#elif defined(tri)//三叉树状数组
int main(){
freopen("tree.out","w",stdout);
for(int i=1,cnt=0;i<=n;i*=3,cnt++){
for(int j=i;j<=n;j+=i){
a[j]=cnt;
}
}
for(int i=1;i<=n;i++){
printf(
"Polygon\n"
"%.1lf %d\n"
"%.1lf %.1lf\n"
"%.1lf %.1lf\n"
"%.1lf %d\n"
"...\n",
i-pow(3,a[i]),a[i],
i-pow(3,a[i]),a[i]+0.7,
i-0.3,a[i]+0.7,
i-0.3,a[i]
);
}
return 0;
}
#elif defined(tag)//树状数组+延迟标记
int main(){
freopen("tree.out","w",stdout);
for(int i=1;i<=n;i++){
a[i]=log(i&(-i))/log(2);
printf(
"Polygon\n"
"%d %d\n"
"%d %.1lf\n"
"%.1lf %.1lf\n"
"%.1lf %d\n"
"...\n",
i-(i&(-i)),a[i],
i-(i&(-i)),a[i]+0.7,
i-0.3,a[i]+0.7,
i-0.3,a[i]
);
printf(
"Segment %d %.1lf %d %.1lf\n"
"Segment %.1lf %.1lf %.1lf %.1lf\n",
i,a[i]+0.2,i,a[i]+0.5,
i-0.3+(i&(-i)),a[i]+0.2,i-0.3+(i&(-i)),a[i]+0.5);
for(int j=i;j<=i-0.3+(i&(-i));j++){
printf(
"Segment %d %d %.1lf %d\n"
"Segment %d %.1lf %.1lf %.1lf\n",
j,a[i],j+0.5,a[i],
j,a[i]+0.7,j+0.5,a[i]+0.7);
}
}
return 0;
}
#endif
```