浅谈AC自动机(附Trie&KMP)
吹雪吹雪吹
2018-07-20 18:29:46
## Aho-Corasick Automaton · AC自动机
AC自动机是一个高效的字符串多模匹配算法,它的核心想法是把KMP的失配指针做到Trie上,从而实现对于所有模板字符串而言的单次文本串扫描出结果。由此可见,若要整下AC自动机,必须先掌握Trie和KMP。
**注意!**请务必仔细阅读并~~深入~~理解KMP,否则看AC机会有点困难
另外,AC自动机真的不是自动帮你AC的机子 ~~其实你可以找AK自动机~~。
下文涉及的Trie以及KMP主要为AC自动机做铺垫,详细算法介绍请见相应文章。~~KMP好像比较详细的呢~~
---
## Part.1 - 字典树(Trie)
其实字典树、前缀树什么的是同一个东西。
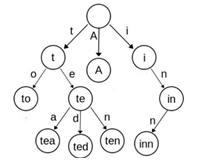
不难看出,树上每个节点都对应了一个单词。Trie就是这样一颗多叉树(26叉较常用,图中省略了空子树),它的边用一个大小为26的数组记录,这样就可以实现O(1)向下查找。例如单词“tea”,它对应树中路径root (第零层) > 1-1(第一层左往右第一个) > 2-2 > 3-1 。
插入:从根开始,顺着边往下走(O(1)递进,实现见代码),当走到词的末位时标记当前节点
查询:从根开始,顺着边往下走(中途走不通视为查询失败),当走到词的末位时检查当前节点,确认是否被标记。
实现方法:~~市面上~~ 有两种:数组模拟和充斥着指针的动态实现,建议初学者使用静态数组,dalao们请随意
代码~~一言不合就封装~~:
```cpp
class Trie
{
private:
class Nodes
{
public:
Nodes* nxt[26];
bool end;
Nodes()
{
for(int i=0;i<26;++i)
nxt[i]=NULL;
end=false;
}
void init()
{
for(int i=0;i<26;++i)
nxt[i]=NULL;
end=false;
}
};
Nodes root,*now;
public:
Trie()
{
this->root.init();
this->now=NULL;
}
void init()
{
this->root.init();
this->now=NULL;
}
int insert(const char *s)
{
if(!s)
return 0;
this->now=&this->root;
for(int i=0;s[i];++i)
{
char ch=(s[i]>='a'&&s[i]<='z'?s[i]-'a':s[i]-'A');//假定大小写通用
//一般情况下这样写: char ch=s[i]-'a';
if(!this->now->nxt[ch])
{
if((this->now->nxt[ch]=new Nodes)==NULL)
{
return -1;//申请内存失败,返回错误信息
}
}
this->now=this->now->nxt[ch];
}
this->now->end=true;//标记单词末尾
return 1;
}
bool find(const char *s)
{
this->now=&this->root;
for(int i=0;s[i];++i)
{
char ch=(s[i]>='a'&&s[i]<='z'?s[i]-'a':s[i]-'A');
if(!this->now->nxt[ch])
{
return false;
}
this->now=this->now->nxt[ch];
}
return this->now->end;
}/*
~Trie()
{
}*/
};
```
---
## Part.2 - ~~看毛片~~(KMP)
看毛片算法至关重要,请务必仔细阅读并理解相应的内容。
#### ·浅谈一发
暴力求解时,有i指针在文章里,j指针在单词里,我们发现i和j总是在瞎jb乱跳。那么,能不能使其中一个递增,然后利用已有信息求出当前j的最大值呢?
假定我们有办法利用已有信息在log以内求出max(j),那么匹配就很顺利了:当前位置匹配则长度+1,否则求解max(j),后移j指针,直到j==0或者下一位匹配。
回到求解max(j):
我们已有一段匹配的子串,长度为len,那么max(j)一定小于len(废话)。再进一步,设max(j)=k,那么s[1..k]=s[(j-k+1)..j],否则k不合法。
观察:```s[1..k]=s[(j-k+1)..j]```,这不就是最长公共前后缀吗!
#### 部分匹配值
· 我也不知道是不是这么叫,反正实际上是最长公共前后缀。
· 最长公共前后缀: 找到max(len),使得字符串长度为len的前缀和后缀完全匹配。第三个栗子: ABCAB的最长公共前后缀为AB,len=2
~~算了还是说一下前缀和后缀吧:~~
```cpp
ABCBCD
len 前缀 后缀
0 (空串) (空串)
1 A D
2 AB CD
3 ABC BCD
4 ABCB CBCD
5 ABCBC BCBCD
......
6 ABCBCD ABCBCD
```
~~(如果您还是不会,自行Ctrl+w并百度)~~
#### 部分匹配值的获取(get_next函数)
· 惯例:如果你还不知道部分匹配值,请按Ctrl+w
next数组的意义:nxt[i]表示搜索词从开头(第零位)到第i位的部分匹配值
```cpp
void mknxt(int nxt[],int lw,char w[])
{
int k=0,i=1;//k是上一次的匹配值,i务必从1开始
for(k=0,i=1;i<lw;++i)
{
while(k>0&&w[i]!=w[k])//k>0不解释,w[i]!=w[k]即当前匹配不成功
k=nxt[k-1];//我也不想解释,可就是难解释啊
if(w[i]==w[k])//当前位置匹配成功
k++;
nxt[i]=k;
}
}
```
当前位置匹配成功的操作很好理解,k+1即可。
关键在于不相等的情况:k=nxt[k-1]是什么鬼!

w[k]与w[i]不等的处理方法:显然长度为k的前后缀是不能用了,所以应当去考虑短一点的前后缀。展开图中大条子,出现上下两个小条子,小条子的结构也是绿黄绿,而且(1-1)=(1-2),(2-1)=(2-2)。我们知道(大条子绿色前缀)=(大条子绿色后缀),所以(1-1)=(1-2)=(2-1)=(2-2)。然后执行k=nxt[k-1],原图变为:

现在,大条子中的绿色部分已经缩短,k的值改变为原来的nxt[k-1]。再次检查w[k]和w[i]。
#### 查找
```cpp
void KMP()
{
for(int i=0,k=0;i<ls;++i)
{
while(k>0&&w[k]!=s[i])
k=nxt[k-1];
if(w[k]==s[i])
k++;
if(k==lw)
printf("Pattern occurs with shift:%d\n",(i-lw+1));
}
}
```
如果你看懂了next数组的构造,这里也就不需要解释了
---
## Part.3 - AC自动机
当需要找的东西太多时,KMP就显得很磨叽(需要对每一个模板串构造一次nxt数组并在所有文本串中找一次),因此引入AC自动机。
#### #关于AC自动机
~~当然是自动帮你AC题目的机器啦~~
一种多模式串匹配算法,该算法在1975年产生于贝尔实验室,是著名的多模式匹配算法之一。
有限状态自动机中最简单的一种。
#### ·浅谈AC自动机(怎么现在才讲啊!)
某dalao:AC自动机就是爬到树上看毛片。
dalao说的很好!~~但是看毛片是违法的~~ AC自动机实际上是把KMP与Trie结合,将KMP中的next转变为fail指针挂到Trie上。
显然,在KMP匹配的过程中,i指针**递增**,j指针(已匹配的末位)总是在"乱跳"。AC自动机的匹配过程如KMP类似,i指针递增,j指针在图上跳。
我们的目的是最大化当前匹配部分,也就是最大化j的值(在Trie上是节点深度)。
来回顾KMP:j+1与i不匹配时,借助next数组前推j指针,使得j'最大。
KMP是仅有一个单词的情况,那么当单词有多个呢?
显然,我们可以在别的单词里去找next。这时next已经被做成指针了,也就是fail(也叫失配边)
假设我们已经求得fail指针,那么接下来要做的是匹配。
与KMP类似,若新字符匹配成功则j指针下移一层,否则j不断沿着失配边走下去,直到j的深度为0(root),或者下一位成功匹配。
由于单词有多个,可能存在s为t的后缀的情况,因此追加一个后缀链接方便查找。
再举个例子:
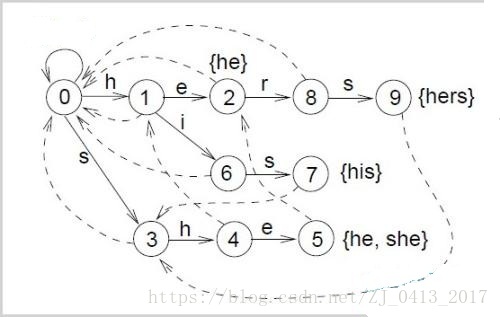
现有单词:{"SAY","SHE","SHR","HER"}
首先构造出Trie如图:

接下来从第一层开始构造失配边(红色边):
由于到这一层的串再Trie中均没有合法的后缀,故把这一层所有点的失配边指回Root(可以理解为空串是其合法后缀)

---
第二层,出现了"H"是当前"SH"的后缀,将第二层'H'点的失配边指向第一层的'H',其余节点的fail指回Root

---
第三层,出现了"HE"是"SHE"的后缀,将第三层'E'的fail指向第二层'E'。
这时,虽然有"R"是"SHR"的后缀,但是"R"并不是一个从Root开始的合法串,故仍将'R'的失配边指向Root

接下来开始实现:
#### ·实现
#### #构造Trie
将模板串全部读入并构造Trie,这里需要在之前的Trie基础上新增last和fail指针,前者叫做后缀链接(后头再解释),后者就是失配边。
#### #~~画图~~构造失配边与后缀链接
失配边类似于KMP中的next,实际上指向了一个串的后缀(只需要满足后缀的关系就行),有了这玩意儿可以极大的方便查找;
后缀链接指向串的后缀(废话)且**该后缀是一个完整的单词**。后缀链接的作用很显然,如果有{"fubuki","ki"},某时刻已经找到了"fubuki",那么顺着后缀链接就能找到"ki",这样一来,后缀链接就可以进行递归累计。
```cpp
void ACA()//BFS构造失配边
{
queue<Trie*>que;
for(int i=0;i<26;++i)
{
now=root.nxt[i];
if(now)
{
que.push(now);
now->f=&root;
}
}//初始化队列
while(!que.empty())
{//逐层构造
Trie *hed=que.front();
que.pop();
for(int i=0;i<26;++i)
{//构造对于now->nxt[i]的fail与last
Trie *j=hed->f;
now=hed->nxt[i];
if(!now)
{
if(j)
hed->nxt[i]=j->nxt[i];//这句过会儿解释,请暂忽略
continue;
}
que.push(now);
while(j&&!j->nxt[i])//从hed->f的基础上获取hed->nxt[i]->f,找一个hed的后缀,且这个后缀的后一个字符为i
j=j->f;
/* <???>"*********"'字符' hed->nxt[i]对应的串(双引号内为已经确定fail的部分)和当前字符
"*********"'未知字符' hed->f对应的串及其下一个字符(未知)
显然,两端中双引号内字符串完全匹配,只需考虑二者的下一个字符是否相等
*/
if(j)//数组版无需判断,这里是指针防越界(空指针)
{
now->f=j->nxt[i];
now->lst=now->f->flg?now->f:now->f->lst;//如果失配边指向一个单词就直接记录lst,否则看看失配边指向的lst
}
if(!now->f)//空串是任意串的后缀,无法构造fail的就指回root Ps.数组版还是不需要。。。
now->f=&root;
}
}
}
```
#### #匹配(查询)
与KMP的Find相差无几,只不过由推动下标变为推动节点指针
```cpp
void find()
{
now=&root;
for(int i=0;s[i];++i)
{
int j=s[i]-'a';
while(now&&!now->nxt[j])//如果当前节点没有儿子i就顺着失配边走直到新节点有儿子i或走回root
now=now->f;
if(now)//再次防越界(空指针)
{
now=now->nxt[j];//相当于KMP里的指针后移
if(now->flg)//当前节点记录了单词
count(now);//递归累加出现次数
else if(now->lst)//当前串的后缀可能是个单词
count(now->lst);
}
else//now为空意味着走回root
now=&root;
}
return;
}
/*构造失配边时有一句:hed->nxt[i]=j->nxt[i];
实际上是加上一条不存在的边,把nxt[i]变成了另一个fail指针
如果构造时写了这句话,匹配的时候就无需写while(now&&!now->nxt[j])了*/
void count(Trie *now)
{
if(!now)
return;
cnt[now->flg]++;
count(now->lst);//当前串的后缀可能又是一个单词
}
```
---
#### #最后贴上完整代码,写的很粗鲁大家见谅
```cpp
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
int n,m,cnt[1005];
char s[1005];//不要在意大小
class Trie
{
public:
Trie *nxt[26],*f,*lst;
int flg;
Trie()
{
for(int i=0;i<26;++i)
nxt[i]=NULL;
f=lst=NULL;
flg=0;
}
}root,*now;//Trie
void count(Trie *now)
{
if(!now)//
return;
cnt[now->flg]++;
count(now->lst);
}//累计答案用的,不同题目会要求不同答案
void find()
{
now=&root;
for(int i=0;s[i];++i)
{
int j=s[i]-'a';
while(now&&!now->nxt[j])
now=now->f;
if(now)
{
now=now->nxt[j];
if(now->flg)
count(now);
else if(now->lst)
count(now->lst);
}
else
now=&root;
}
}
void ACA()//BFS构造失配边
{
queue<Trie*>que;
for(int i=0;i<26;++i)
{
now=root.nxt[i];
if(now)
{
que.push(now);
now->f=&root;
}
}
while(!que.empty())
{
Trie *hed=que.front();
que.pop();
for(int i=0;i<26;++i)
{
Trie *j=hed->f;
now=hed->nxt[i];
if(!now)
{
if(j)
hed->nxt[i]=j->nxt[i];
continue;
}
que.push(now);
while(j&&!j->nxt[i])
j=j->f;
if(j)
{
now->f=j->nxt[i];
now->lst=now->f->flg?now->f:now->f->lst;
}
if(!now->f)
now->f=&root;
}
}
}
int main()
{
freopen("test.in","r",stdin);
freopen("test.out","w",stdout);
scanf("%d%d",&n,&m);
for(int i=1;i<=n;++i)
{
now=&root;
scanf("%s",s);
for(int j=0;s[j];++j)
{
if(!now->nxt[s[j]-'a'])
now->nxt[s[j]-'a']=new Trie;
now=now->nxt[s[j]-'a'];
}
now->flg=i;
}
ACA();
for(int i=1;i<=m;++i)
{
scanf("%s",s);
find();
}
for(int i=1;i<=n;++i)
printf("%d ",cnt[i]);
return 0;
}
```
---
#### ·偷懒的我
为啥AC自动机写的比KMP短? ——你都理解KMP了,上树不就行了吗!
---
#### ·写在后边
如果哪一位dalao会 AK自动机 请尽快联系本蒟蒻,必有重谢!
本文多有不妥之处,欢迎批评指正!
~~本文不会有人转的。。。~~转载请注明出处。
参考:
刘汝佳《算法竞赛入门经典(训练指南)》
徐玄長(好吧我自己)[《KMP·看毛片》](https://blog.csdn.net/zj_0413_2017/article/details/80214703)