技巧笔记:详解考场技巧/常数优化
Aw顿顿
2020-04-07 08:05:00
# 详解考场技巧/常数优化
By Aw顿顿
## 目录
- $-1.$ 前言之前的话
### $0.$ 前言
- $\rm R:$ 常数是什么
### $1.$ 卡常技巧
- $1.1$读入优化
- $\rm R:$ 关于位运算
- $1.2$ 输出优化
- $1.2.0\ \rm register$ 优化
- $1.2.1\ \rm inline$ 优化
- $1.3.0$ 内存优化
- $1.3.1$双目运算优化
- $1.4$ 其他优化
- $\rm R:$ 关于STL
- $1.5$ C语言优化
### $2.$ 考场技巧
- 循环顺序
- 选择容器
- 内置函数
- 定义变量
- 循环展开
- 判断语句
- 函数
- 做题顺序
### 参考资料
### 鸣谢
-----------
## $-1.$ 前言之前的话
因为洛谷日报很多的内容都较为复杂,所以写了这一篇文章来介绍比较**容易理解**的内容,会尽可能讲解的详细。
现在 OI 比赛中,越来越**复杂的题面**和题目内容,越来越卡常的题目,很多时候可能会造成一些不必要的问题,所以,我准备写这篇文章,来为大家介绍一下我所知道的考场技巧。
注:带有 $\rm R$ 前缀的为拓展知识。
## $0.$ 前言
> OI 竞赛,也就是“**信息学奥赛**”是一项全球化的、令无数同学向往的赛事。从 CCF(中国计算机学会)的 NOIp(或者说CSP) 开始,到省选、国家集训队,APIO、NOI、CTSC等一系列赛事,都是为了选拔优秀的信息学奥赛选手,我们通常称之为 OIer。
关于 OI 比赛更加详细的内容,请访问:[OI Wiki - OI 赛事与赛制](https://oi-wiki.org/intro/oi/)。
在今天的 OI 比赛中,我们面临着越来越奇特、毒瘤的考试,为了能够更好的拿分,今天我们一起来探讨一些和算法关系相对较少,但是分外重要的内容。
**内容包括:卡常数技巧,考场注意事项和其他一些可能有用的内容。**
#### $\rm R$ 常数是什么
> 卡常数,又称底层常数优化,是信息学竞赛中一种针对程序基本操作进行空间或时间上优化的行为,与时间复杂度或剪枝有别。
也指程序虽然渐进时间复杂度可以接受,但是由于实现/算法本身的时间常数因子较大,使得无法在 OI/ACM-ICPC 等算法竞赛规定的时限内运行结束。
摘自 [百度百科 - 卡常数](https://baike.baidu.com/item/%E5%8D%A1%E5%B8%B8%E6%95%B0/16211104?fr=aladdin)。
简单来说,就是除去一个程序运行部分次数最大的一项以外,其他的不被算进时间复杂度的内容近似于常数。
借用 @ix35 神仙(感谢他的回答)的讲解:
“(常数)大概就是 $\lim\limits_{x\to \infty} \dfrac{T(x)}{f(x)}=c$ 中的 $c$,其中 $T(x)$ 是运行次数,$f(x)$ 是复杂度。”
## $1.$ 一些卡常技巧
比较专业的内容,详见 [noip的博客 - OI中简单的常数优化的介绍](https://www.luogu.com.cn/blog/user3296/oi-zhong-jian-dan-di-chang-shuo-you-hua)。
### $1.1$ 读入优化
常见的读入有以下几个:
\* 数据整理于 lxl 博客。
| 读入类型 | 耗时 |
| :----------: | :----------: |
| `cin` 读入 | $119.1\ s$ |
| `scanf` 读入 | $71.14\ s$ |
| 快速读入 | $28.74\ s$ |
| `fread` 读入 | $1.535\ s$ |
------------------
这时候我们会发现,`fread` 的效率会明显比其他的读入要高,因为他直接从文件中读取二进制数:
```cpp
struct FastIO {
static const int S = 1e7;
int wpos;
char wbuf[S];
FastIO() : wpos(0) {}
inline int xchar() {
static char buf[S];
static int len = 0, pos = 0;
if (pos == len)
pos = 0, len = fread(buf, 1, S, stdin);
if (pos == len) exit(0);
return buf[pos++];
}
inline int xuint() {
int c = xchar(), x = 0;
while (c <= 32) c = xchar();
for (; '0' <= c && c <= '9'; c = xchar()) x = x * 10 + c - '0';
return x;
}
inline int xint()
{
int s = 1, c = xchar(), x = 0;
while (c <= 32) c = xchar();
if (c == '-') s = -1, c = xchar();
for (; '0' <= c && c <= '9'; c = xchar()) x = x * 10 + c - '0';
return x * s;
}
inline void xstring(char *s)
{
int c = xchar();
while (c <= 32) c = xchar();
for (; c > 32; c = xchar()) * s++ = c;
*s = 0;
}
inline void wchar(int x)
{
if (wpos == S) fwrite(wbuf, 1, S, stdout), wpos = 0;
wbuf[wpos++] = x;
}
inline void wint(ll x)
{
if (x < 0) wchar('-'), x = -x;
char s[24];
int n = 0;
while (x || !n) s[n++] = '0' + x % 10, x /= 10;
while (n--) wchar(s[n]);
wchar('\n');
}
inline void wstring(const char *s)
{
while (*s) wchar(*s++);
}
~FastIO()
{
if (wpos) fwrite(wbuf, 1, wpos, stdout), wpos = 0;
}
} io;
```
但是在考试中通常不会这样卡常的题目(Ynoi 除外),所以我们通常使用快速读入即可。
通常来说,快速读入是这样的:
```cpp
inline int read(){
int s=0,f=1;
char ch=getchar();
while((ch<'0'||ch>'9')&&ch!=EOF){
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
s=s*10+ch-'0';
ch=getchar();
}
return s*f;
}
```
事实上我们知道,单个读入字符要比读入数字快得多,因为一个字符所占的字节数比起整数来说是少很多的。
但是,一个个字符读入还是太慢了,如果想要加快速度,可以使用经过读入优化的快速读入:
```cpp
inline char gt(){
static char buf[100000],*p1=buf,*p2=buf;
return
p1==p2&&(p2=(p1=buf)+fread(buf,1,100000,stdin),p1==p2)?EOF:*p1++;
}
inline int read(){
char ch=gt();
int sm=0;
while(!(ch>='0'&&ch<='9'))
ch=gt();
while(ch>='0'&&ch<='9')
sm=sm*10+ch-48,ch=nc();
return sm;
}
```
其中,和原来对比,`gt` 函数似乎是取代了 `getchar();`,更快的原因是因为他**整段读取**,把输入流中整段都**存储与处理**,操作更加**连续**,直到数组处理完毕再继续输入。
(请记住,连续是卡常的一个重点)
既然讲到了字节数,一个数据类型所占字节数可以通过 `sizeof()` 函数得到。
具体来说:
| 数据类型 | $32$ 位机器 | $64$ 位机器 |
|:---:|:---:|:---:|
| `char` 类型 | $1$ | $1$ |
| `short` 类型 | $2$ | $2$ |
| `int` 类型 | $4$ | $4$ |
| `long` 类型 | $4$ | $4$ |
| `long long` 类型 | $8$ | $8$ |
| `char *` 类型 | $4$ | $8$ |
| `float` 类型 | $4$ | $4$ |
| `double` 类型 | $8$ | $8$ |
不同数据类型所占用的空间**并非固定**,空间标准仅规定最少空间及不同数据类型占用空间的大小关系,具体空间与编译器有关,但是,数据类型的占用空间比例是近似的,能够正确估计并分配空间是很重要的一个话题。
因此,我们可以以字符(`char`)的形式读入,然后通过一系列操作计算出其对应数字的值,可以有效节约很大一部分时间。
在判断过程中,判断是否是数字可以使用到的函数是:
- `isdigit()` 函数
同理,`isalpha()` 可以判断字母,其书写比较简单,使程序更易于理解。
使用方式:
```cpp
char c;
cin>>c;
if(isdigit(c)){
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
//判断一个字符是否是数字
char ch;
cin>>ch;
if(isalpha(ch)){
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
//判断一个字符是否是字母
```
此函数在应用的时候需要
```
#include <cctype>
```
方可以使用。
接下来,让我们注意到当中的转换内容:
- 重要语句 `s=s*10+ch-'0';` 是 `x=(x<<1)+(x<<3)+(ch^48);` 的另一种表达形式。
想必大家都知道,`<<` 是位运算中的左移,其运算效果相当于 `*2` ,而其汇编代码是一模一样的。一般来说,位运算的优先级低但是速度快,所以很容易理解这个代码的用处就是进位和将字符转换为数字,与此类似, `^` 是异或的意思。
若特殊输入包含大量空格,可以考虑是否使用 `scanf`,或者是 `cin` 读入优化,因为此时使用快速读入可能会造成一些调试上的困难,读入方面的 bug 总是千奇百怪。
需要知道的是,使用 `a*10` 和 `(a<<3)+(a<<1)` 在运算效率上相差不大,而通常来说,`(a<<3)+(a<<1)`的办法还可能导致重复操作,因此导致负优化。因为系统自动转换比人工转换快的缘故,此类问题我们直接用乘法就行,大可不必位运算+加法。
既然提及了位运算的快速特性,此处整理一下位运算的内容:
| 操作符 | 功能 | 用法 |
| :---: | :---: | :---: |
| `~` | 位求反 | `s=~b` |
| `<<` | 左移 | `s=n<<2`|
| `>>` | 右移 | `s=a>>3` |
| `&` | 位与 | `(a&1)==0` |
| `^` | 位异或 | `k=m^n` |
| `|` | 位或 | `s=(a|2)` |
这些位运算都具有两个特点:
- 运算速度快,直接对二进制位进行处理。
- 运算优先级低,比普通四则运算的优先级低很多。
所以,正是因为其运算处理方式和我们直观的印象差别巨大,所以常常会导致我们所期望的程序结果和实际运行输出不符。这时候合理使用括号可以有效明晰其运算顺序,否则很容易引起调试困难,因为此类问题很难察觉。
------------
#### $\rm R:$ 关于位运算
资料源于:[百度百科 - 位运算](https://baike.baidu.com/item/%E4%BD%8D%E8%BF%90%E7%AE%97/6888804?fr=aladdin)
程序中的所有数在计算机内存中都是以**二进制的形式**储存的。位运算就是直接对整数在内存中的**二进制位**进行操作。
如:
- `and`(&)运算作为位运算符,可以再整数与整数之间进行`and`运算。
- 异或($\operatorname{xor}$)运算的逆运算是它本身,也就是说两次异或同一个数最后结果不变,即 $a \operatorname{xor} b\operatorname{xor}b=a$
举个例子,$6$ 的二进制是 $110$,$11$的二进制是$1011$,那么$6\&11$ 的结果就是 $2$,它是二进制对应位进行逻辑运算的结果($0$表示 False,$1$ 表示 True,空位都当 $0$ 处理)。
更多具体的内容详见:[OI Wiki - 位运算](https://oi-wiki.org/math/bit/)。
当然往期日报也有提及 [二进制与位运算](https://www.luogu.com.cn/blog/chengni5673/er-jin-zhi-yu-wei-yun-suan)。
------
我们回归读入优化的话题,此处贴上 `fread` 简化版的代码,同样来自 lxl 的博客。
```cpp
struct io {
char ibuf[900 << 20] , * s;
io() {
fread( s = ibuf , 1 , 900 << 20 , stdin );
}
inline int read() {
register int u = 0;
while( * s < 48 ) s++;
while( * s > 32 )
u = u * 10 + * s++ - 48;
return u;
}
} ip;
```
结束了输入优化的章节,自然而然的,就到了输出优化。
### $1.2$ 输出优化
首先,类似快速读入,快速输出利用 `putchar` 来进行优化,依然是使用字符类型:
```cpp
void write(int x){
if(x<0){
putchar('-');
x=-x;
}
if(x>9)write(x/10);
putchar(x%10+'0');
}
```
接着是 `fwrite` 的输出优化,同样,速度快但是操作相对复杂:
```cpp
template< class T >
inline void print( register T u ){
static int * q = a;
if( !u ) * t++ = 48;
else {
if( u < 0 )
* t++ = 45 , u *= -1;
while( u ) * q++ = u % 10 + 48 , u /= 10;
while( q != a )
* t++ = * --q;
}
}
```
注意到 noip 博客有一句话:
> 由于一般输出量都比较小,所以输出优化意义不大。
所以我们常见的是快速读入+`printf` 的组合已经可以满足需求。
如果仅输出一个字符,建议使用 `putchar('a');` ,如果是一个字符串,可以使用自带换行的 `puts("chen_zhe AK IOI!");`。
但是如果是有输出方案等内容,输出优化依然有一定的重要性。
-------------
### $1.2.0$ $\rm register$ 优化
`register` 的意思是“寄存器”,即把循环变量放到寄存器里面。
其实很多情况下,其优化效果并不明显,在 `int` 中的优化效果相对比较明显,而如果是在 STL(标准模板库)的迭代器中使用,效果将会十分明显,同理,其原因是需要寄存的内容较多。
不过开了 O2 优化的程序会将大多数适合寄存器的内容放入寄存器,所以手动的 $\rm register$ 就几乎没有优化了。
使用方式:
```cpp
for(register int i=0;i<=n;++i)cout<<i<<' ';
```
它的作用是声明一个反复使用的局部变量,不在内存中开辟空间而使用寄存器。
此时我们来看一个表格:
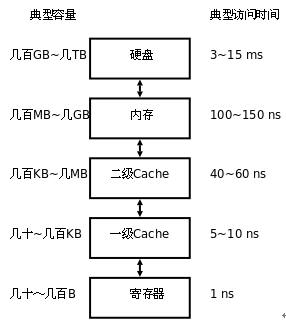
大概介绍了寄存器的优化程度。
----------
### $1.2.1$ $\rm inline$ 优化
> 如果一个简单函数调用次数很多,属于瓶颈,调用时的传参可能会大大影响程序效率
这种情况下可以把这个函数给inline掉
inline就是把一个函数内联,可以减少跳转和传参的代价
是不是看着很蒙?其实,简单来说就是:
实际上,就是把整个函数进程放入一个地址中,按一定的顺序运行。引入内联函数实际上就是为了解决这一问题,减少了函数的跳转过程,同时整体的连贯性比较强,也就优化了整体时间。
同时,他避免了函数调用多余的进出栈操作,进行进一步优化,而且简单的程序反复调用产生的瓶颈效应会导致时间大大增加,此时牺牲一定空间 $\rm inline$ 这个函数,就可以达到很好的优化效果。
比如:
```cpp
inline void big(int x,int y){
if(x>=y)cout<<"Big"<<endl;
return;
}
```
-----------
### $1.3.0$ 内存优化
这个优化和时间相关内容不大,是可以避免 MLE 的一个办法。
首先就是估计程序所需范围了,要是数组开小了不是 RE 就是 WA,RE 的原因通常是越界,而 WA 的原因通常是找不到/存不下。
然后如果可以使用 `bool` 类型作为标记,可以不使用 `int` 类型,同样的,如果只是存储一个字符,`char` 类型必然会比 `long long` 要好。那么这就已经是常识范围的事情了。
### $1.3.1$ 双目运算优化
首先,是**取模操作**。
取模操作基本可以说是算术操作中最慢的,所以经常浪费大量时间。
此处需要用到的性质是 $x\ \bmod\ 2^k$ 等同于和 $x\&(2^k-1)$。
例如对 $8$ 取模,可以进行按位与操作,位运算上面已经介绍过了。
所以可以得到一个等式:`n%8==(n&7)`。
同样,经常有一些递推式,要求“输出对 $10^9+7$ 取模”,这时可以利用**有限范围**的特性,一个加法/减法解决qwq。
还有的**基础四则运算**~~信仰~~优化:
- 乘法:直接乘 $2$ 的指数倍可以用位运算。
- 除法:同理,用位运算。
事实上,他们的汇编代码是一样的,所以没有差距,~~加不加就是信仰了~~。
需要澄清一下,很多的所谓“位运算”速度快的举例都是直接把四则运算变成位运算,其实这是不正确的,直接的装换并没有很大差距,具体内容因为汇编代码一致,想必“较快”的错觉是有主观因素在内的。
有一些其他内容确确实实可以优化的是:
- 普通除法优化:除法运算的耗时是乘法运算的几倍,能不用尽量不用,比如 `i/a>b` 可以换成 `i>a*b`,同理,利用不等式/等式的性质,可以化简的表达式也可以使用此操作。
举例:
```cpp
double a,b,c;
cin>>a>>b>>c;
a/=c; b/=c;
//在一些情况下可以替换为
double a,b,c,d;
cin>>a>>b>>c;
d=1/c;
a*=d; c*=d;
```
- 取模优化:
需要注意的是,这个优化并非速度上的优化,事实上它很慢,它的用途是当模数超过了 `int32` 时,两个数相乘会超出 `int64` 的范围导致错误,此类方法可以规避这个问题。
```cpp
typedef long long ll
ll mod(ll x ,ll y , ll md ) {
ll t=(x*y-(ll)((long double)x/md*y+0.5)*md);
return t<0?t+md:t;
}
```
这个方法其实十分巧妙。
重点:
#### Barrett Reduction 算法优化除法&取模运算
- 由 @yurzhang 提供,十分感谢。
假设 $b$ 为字长,对于一个除数 $M(2\le M<2^b)$,令
$$s=\left\lfloor\log_2(M-1)\right\rfloor$$
$$X=\left\lceil\frac{2^{b+s}}{M}\right\rceil$$
有 $X<2^b$,并且对于任意的
$$N\in[0,2^{b-1})$$
有:
$$\left\lfloor\frac{N}{M}\right\rfloor=\left\lfloor\frac{NX}{2^{b+s}}\right\rfloor$$
这意味着我们将除法运算变成了一次乘法运算和一次按位右移运算。
又有
$$N\bmod M=N-M\times\left\lfloor\dfrac{N}{M}\right\rfloor$$
所以取模也被优化到了两次乘法、一次按位右移、一次减法。
这个方法的正确性是显然的,因为直接抵消掉了可以除尽的部分,其他的特殊情况读者可以自行体会。
-----------
### $1.4$ 其他优化
首先是一些前置知识:
#### $\rm R: $ 关于 STL
STL是`Standard Template Library`的简称,中文名`标准模板库`,从根本上说,STL是一些“容器”的集合。
重要的内容有:
- 手写 STL 优化
建议先使用 STL 将程序框架写好,确保思路正确,再将当中 STL 一一换为手写的内容。如果是 `queue` `deque` 和 `stack` 等较为简单的内容,可以手写,如果是 `set` 这一类不仅难写而且没必要手写的内容就算了吧。
同时,是否手写还可以参考下文的“根据数据范围选择容器”。
- 松式基排优化
普通基排,就是以 $65536$ 为底,用位运算,把一个数拆成两部分,要循环两遍。
松式基排,就是以 $256$ 为底,用位运算把一个数拆成四部分,要循环四遍。
这样就可以有效减少时间了。~~虽然通常不会去卡这个东西~~。
- 玄学优化(优化性能不确定/较小的)
比如 `++` 前置可以减少运算次数。
> 《C专家编程》中有如下描述(P276,人民邮电出版社):
> `++a`表示取 $a$ 的地址,增加它的内容,然后把值放在寄存器中,`a++`表示取 $a$ 的地址,把它的值装入寄存器,然后增加内存中的a的值;(也就是说操作的时候用到的都是寄存器里面的值,即自增前的值)但是这种优化其实很大程度上是自我安慰,具体原因参照 CCF 少爷机。
但是如果这是使用 STL 中的迭代器,其优势会变得明显,这是因为汇编代码不能对于 STL 中的代码块进行编译优化。
理由如上述。
- 地址连续访问优化
还有,遍历数组时最好按数组存放顺序遍历,可以减少查询地址的时间。
在某种程度上:
- 函数在参数前取地址也可以优化速度。
- 三目运算符可以减少码量,但是速度并不比 `if` 快。
- 大多数情况下,如果能够调用更少次数的全局变量比多次调用局部要快。
- 同时,全局变量的自动初始化是一个很好的特性。
但是,为了防止一些奇怪的问题(如变量重名),是否使用全局变量还是依据情况而定。
矩阵乘法交换循环顺序可以使访问地址连续,可以加快速度。
```cpp
int ans;
ans=pow(a,4);
//可以优化为:
ans=a*a*a*a;
//也可以
ans=ksm(a,4);
```
当中利用二分思想的“快速幂”如下:
```cpp
int quickpow(int a,int b){
int s=1;
while(b){
if(b&1)s=(s*a)%mod;
a=(a*a)%mod;
b>>=1;
}
return s%mod;
}
```
注意取模。
其核心思想为:$a^n=a^{n\div 2}\times a^{n\div 2}$,当然也可以写成相对较慢的递归形式。
同理,还有短路运算符优化等内容,尽量减少运算的次数。
另外部分关于 `bitset` 指令集之类的优化暂时不说,优化开关等火车头内容详见 [Aw顿顿 - 基础模板全集](https://www.luogu.com.cn/paste/0kez7qrf)。
### $1.5$ C语言优化
专门分出一个栏目因为资料整理自**C代码优化方案**。
首先,是选择适合的数据结构。
~~~
举例来说,对于插入删除操作较多的内容,可以使用链表。
举例来说,对于指向性强的内容,指针比数组会更快。
一个是因为其空间占用少,另一个是因为其指向/引用等方面十分灵活。
但是使用指针一定要注意,容易混淆的一些概念。
~~~
减少运算的次数/衡量同思想不同实现方式的优劣
可以打表后输出,也可以做一部分的**预处理**,这样可以减少重复的工作。
----------
至此,常数优化内容已经全部讲解完毕,接下来要讲解考场技巧的内容了。
-----------
## $2.$ 一些考场技巧
- #### 减少重复而没有必要的函数调用
```cpp
for(int i=0;i<str.size();++i);
//重复调用了 .size 函数
int l=s.size();
for(int i=0;i<l;++i);
//利用变量减少调用次数
```
与其类似,通过**减少循环次数**,增加手写操作次数来进行操作,同时也减少不必要的判断:
```cpp
for(int i=1;i<=n;i++)for(int j=1;j<=n;j++){
if(i!=j)a[i][j]=0;
}
//可以转换为
for(int i=1;i<=n;i++)for(int j=1;j<i;j++){
a[i][j]=a[j][i]=0;
}
```
同时,我个人不大喜欢,但是 [`OI Wiki - 常见技巧`](https://oi-wiki.org/intro/common-tricks/) 有摘录的一个技巧是**宏定义化简代码**:
> 我们写代码时,像下面这样的循环代码写得会非常多:
```cpp
for (int i = 0; i < N; i++) {
}
```
> 为了简化这样的循环代码,我们可以使用宏定义:
```cpp
#define f(x, y, z) for (int x = (y), __ = (z); x < __; ++x)
```
同时,比较推荐的是:
```cpp
#define endl '\n'
#define INF 0x7fffffff
```
这样减少码量,提升速度,也让代码更加可读。
新手常犯的错误是在宏定义最后加上分号。但是,考虑到宏定义是以字符串的形式对于两个替换内容来处理的,很容易知道为什么不能出现多余的分号。
适量使用宏定义是可以有效提高代码可读/调试性的,但是一定要注意适量,物极必反,过多的`define` 可能会让 Debug 出现混乱。
在利用宏定义的情况下,一些可能隐藏的问题不容易被发现,所以考场上使用 `Dev-C++` 的时候建议开启 `Wall` ,从而增加可能出现的警告,发现一些极其容易被忽略的 UB。
什么?你不知道 UB(未定义行为)是什么?可以阅读:
[Studying Father's luogu blog - 关于 C++ 未定义行为的一些事](https://studyingfather.blog.luogu.org/undefined-behavior)
简单来说,UB 就是**没有被定义的行为**,如溢出等。
另外,需要反复调用的复杂表达式可以用换元法,利用变量减少码量。
- #### 注意循环顺序:
```cpp
//矩阵乘法和或者Floyd
//循环顺序可能导致程序错误
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)
for(int k=1;k<=n;++k)
d[i][j]=max(d[i][j],d[i][k]+d[k][j]);
//变成这样:
for(int k=1;k<=n;++k)
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)
d[i][j]=max(d[i][j],d[i][k]+d[k][j]);
```
循环顺序与时间无关,只是有的顺序有后效性,但这依然是一个值得思考的问题。
- #### 根据情况选择容器
不过对应刚才 STL 的介绍,还有一个是需要注意的,如果题目出现这种表述:
有 $n$ 个种类,每个种类 $m$ 个。
$1\le n,m\le 10^6$
$1\le nm\le 10^9$
此时建议使用 STL 动态存储空间,既不会 MLE,也不会开的空间过小。
- #### 关于内置函数
个人尽量不要使用内置的函数,比如 `max` 等,较为简单的函数建议直接放在运行语句中。
```cpp
inline int mx(int a,int b){
return a>b?a:b;
}
//这种方法和内置函数没有很大差别。
```
- #### 定义变量
当编译器分配空间时,变量地址顺序和它们定义的顺序一样,同类变量应当一起定义,使用连续,同时也可以使定义更加清晰。如果第一个变量对齐了,其它变量就会连续的存放,不用填充字节自然就会对齐。
在结构体内/类与对象内依然是这样的规则,可以提升代码的 Debug 能力。
同时,提取公共部分并存储是优化的一个重要思想,如用变量提取公共式,或者对于一些不需要循环变量参加运算的任务可以把它们放到循环外面。
- #### 循环展开
对于中间变量或结果更改/重赋值的操作,编译程序通常不会自动展开,这时候就需要人工循环展开了。
能够手动的操作绝不循环,如:
```cpp
for(int i=0;i<3;i++)cout<<a[i]<<' ';
//优化结果如下:
cout<<a[0]<<' '<<a[1]<<' '<<a[2]<<'endl;
```
补充:死循环用`for(;;)`而非`while(1)`。
- #### 判断语句
`if`和`switch` 语句按照发生可能性来排序(短路运算符亦如此)可以减少非理想状态的运算次数。
同时,如果可以使用`if……else if……else`就不要使用连续的`if`,因为前者在一个满足的情况下就不会继续运行,而后者会全部判断一遍。
接着是一些关于考场心态的内容:
- #### 函数
函数定义是,如果函数返回值不会用到,那就该使用`void`类型来声明函数。
同理,在可行的范围内尽可能减少返回值的字节数,不必要的参数不要调用。
使用`const`而非`define`。
- #### 函数
同时声明多个变量优于单独声明变量。
在明确意思的前提下,减少变量的长度。
如`answer_of_questions=1`显然不如`ans=1`。
- #### 做题顺序
正常来说 NOIp/CSP PJ 可以顺次做,T1通常是签到或者是橙题难度-,所以一定要先做,不过要注意细节问题(文件名、文件输入输出)
提高组的每天的 T2 和 T3 可以认真观察后再写,因为不一定难度按顺序。
同理,如果有很容易拿到的部分分先拿,因为如果一开始就奔着正解去很可能就忽略了很多机会。
另外,认真读题,认真思考算法,因为第一次想到的算法不一定是正解,而且可能容易构造出 hack 数据。
最后,我们的讲解就到这里了,祝大家以后的考试都`rp++`。
求点赞、收藏、评论三连哦qwq。
## Reference参考资料
整理了一些对笔者有帮助的,且内容相对来说比较容易理解的资料:
【已经上日报】汇编语言相关:https://blog.zhaojinxi.top/2020/02/03/optimize/
卡常的意义和是否必要:https://www.zhihu.com/question/378318028/answer/1073368248
考试心态/技巧:https://www.luogu.com.cn/blog/zyf2004/fu-sai-shi-yao-ji-zhu-di-30-gou-hua
考场常见技巧:https://oi-wiki.org/intro/common-tricks/
常数优化介绍:https://www.luogu.com.cn/blog/user3296/oi-zhong-jian-dan-di-chang-shuo-you-hua
常数优化技巧:https://margatroid.xyz/posts/constant-optimization/#%E5%BE%AA%E7%8E%AF%E5%B1%95%E5%BC%80
C语言优化方案:http://www.uml.org.cn/c++/200811103.asp
## 鸣谢
感谢以下的用户帮助我找出了一些错误/补充了知识点/提示了更好的写法:
| @灵光一闪 | @HoneyLemon | @一扶苏一 | @Aehnuwx | @yurzhang |
| -----------: | -----------: | -----------: | -----------: | -----------: |