CSP/NOIP初赛整理之知识点
wuhao2005
·
·
个人记录
得复习初赛了
前言:感谢 @jasonfan 和 @MOONPIE 帮忙整理部分资料。若博文中转载资料的部分涉及侵犯版权,请作者私信我,我看到后会处理的,谢谢。
时间分配:
**赛时提醒**:
注意手模动归、记忆化搜索和暴力,能看懂就看懂,不能看懂就先预估时间,如果不够用先做后面的,防止突然慌张。
## **贼无聊的常识**
**1**. IPV4 与 IPV6
IPV4 地址有 $32$ 位, IPV6 地址有 $128$ 位。
IPV4 地址是以小数表示的二进制数。 IPV6 地址是以十六进制表示的二进制数。
IPv4 协议的地址可以通过手动或 DHCP 配置的,但 IPV6 不行。
**2**.电子管->晶体管->集成电路->超大规模集成电路
**3**.1946 年诞生于美国宾夕法尼亚大学的 ENIAC 属于电子管计算机。
**4**.2020 年 IOI 中国金牌共 $4$ 枚。
**5**.真正能唯一标识出一台计算机网络中一台计算机的地址是MAC地址
**6**.CCF主办的赛事活动
CCF :(组织)
```cpp
中国计算机学会
学会前身是成立于1962年的中国电子学会计算机专业委员会
1966年至1978年文革期间停止活动,
1979年1月在北京召开恢复学会活动大会,改名为中国电子学会计算机学会
1985年3月中国科学技术协会转发国家体改委批准成立中国计算机学会
```
NOI :
```cpp
CCF全国青少年信息学奥林匹克 竞赛
CCF National Olympiad in Informatics,NOI
是全国青少年计算机程序设计竞赛,于1984年创办。
```
CCSP :
```cpp
CCF大学生计算机系统与程序设计竞赛
CCF Collegiate Computer Systems & Programming Contest,CCSP
由中国计算机学会(CCF)于2016年发起的一个面向大学生的竞赛
```
CSP :
```cpp
CSP,CCF计算机软件能力认证,2019年开始举办
CCF Certified Software Professional,CSP
旨在考察软件开发者算法设计和编程能力。
```
NOIP :
```cpp
全国青少年信息学奥林匹克 联赛
National Olympiad in Informatics in Provinces,简称NOIP
自1995年至2018年已举办24次。每年由中国计算机学会统一组织。
复赛可使用C、C++、Pascal语言,2022年后将不可使用Pascal、C语言,只能使用C++。
2019年,由于某种原因,由CCF主办的全国青少年信息学奥林匹克联赛NOIP暂停 ,但NOIP在2020年恢复
```
CTSC :
```cpp
国际信息学奥林匹克中国队选拔赛
```
CNCC :
```cpp
中国计算机大会
```
**Attention**:联赛和竞赛是两码子概念。
---------
**7**.存储器
计算机硬件
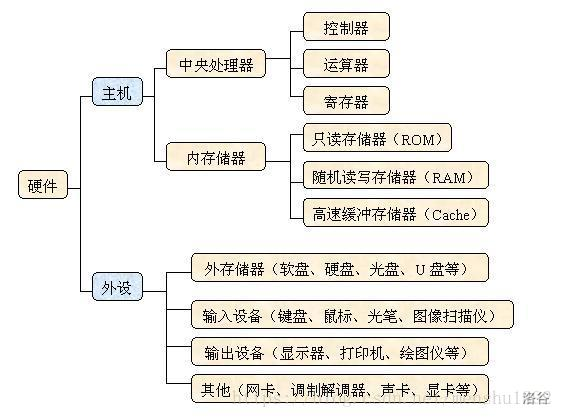
存储器(总)
存储器是分层次的,离CPU越近的存储器,速度越快,每字节的成本越高,同时容量也因此越小。
寄存器速度最快,离CPU最近,成本最高,所以个数容量有限,
其次是高速缓存(缓存也是分级,有L1,L2等缓存),再次是主存(普通内存),再次是本地磁盘。
寄存器>cache>RAM>ROM>外存
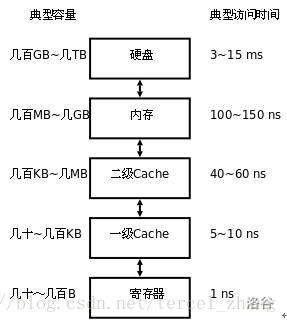
寄存器
寄存器是CPU的组成部分,因为在CPU内,所以CPU对其读写速度是最快的,不需要IO传输,(即访问速度最快)
但同时也决定了此类寄存器数量非常有限,有限到几乎每个存储都有自己的名字,而且有些还有多个名字。
Cache
高速缓冲存储器,在计算机存储系统的层次结构中,
介于中央处理器和主存储器之间的高速小容量存储器。
它和主存储器一起构成一级的存储器。
高速缓冲存储器和主存储器之间信息的调度和传送是由硬件自动进行的。
某些机器甚至有二级三级缓存,每级缓存比前一级缓存速度慢且容量大。
RAM:
随机存取存储器(英语:Random Access Memory,缩写:RAM),
也叫主存,是与CPU直接交换数据的内部存储器。
ROM:
只读内存(Read-Only Memory),简称英文简称ROM。
ROM所存数据,一般是装入整机前事先写好的,
整机工作过程中只能读出,
而不像随机存储器那样能快速地、方便地加以改写。
在微机系统中,最基本的输入输出模块BIOS存放在ROM中
考点:
RAM和ROM相比,两者的最大区别是RAM在断电以后保存在上面的数据会自动消失,而ROM不会自动消失,可以长时间断电保存。
硬盘:
电脑硬盘是计算机最主要的存储设备。
硬盘的容量以兆字节(MB)或千兆字节(GB)为单位,
1GB=1024MB,1TB=1024GB。
-----
**8**.网络协议
1. **TCP/IP**
Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议
**最基础和核心的协议**
2. **OSI**
开放式系统互联通信参考模型 Open System Interconnection Reference Model
对比 TCP/IP , OSI
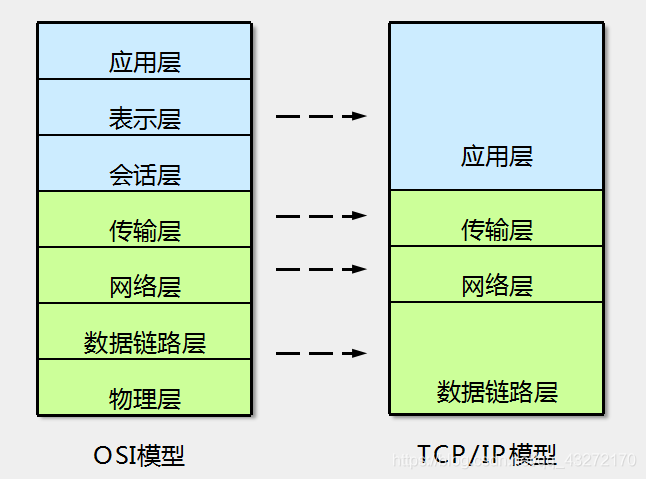
------
**9**.常用协议:
- FTP协议:属于**应用层**协议,FTP 是**文件传输协议**
- UDP协议:属于**传输层**协议,UDP是**用户数据报协议**
- IP协议:属于**网络层**协议, IP地址具有**唯一**性,根据用户性质的不同,可以分为5类。(A~D)
- TCP协议:属于**传输层**协议,TCP(传输控制协议)
- HTTP协议:属于**应用层**协议,**超文本传输协议**是互联网上应用最为广泛的一种网络协议
- SMTP协议:属于**应用层**协议,SMTP即简单**邮件**传输协议。
**注:** 主要的邮件协议有SMTP、POP3、IMAP4
---
**10**.原码,反码,补码
**原码** 最高位为符号位,符号位正数位0 ,负数为1,其余为数值绝对值的二进制
**反码** 正数反码与原码一致,**负数**反码为**原码符号位不变其余按位取反**
**补码** 负数的补码是在反码的基础上**加1**,正数不变
----
**转换**
**注:** 对于某非负数(编码中最高位为0),记为 $C$ ,看作二进制数 $S$ ,则对 $C$ 全位取反表示的数值为 $-1-S
转换原则:
- 正整数的原码、反码、补码完全一样,即符号位固定为0,数值位相同
-
负整数的符号位固定为1,由原码变为补码时,规则如下:
- 原码符号位1不变,整数的每一位二进制数位求反,得到反码
- 反码符号位1不变,反码数值位最低位加1,得到补码
3.由补码变为原码,若最高位为 0 ,为正数补码,与原码一致。若最高为 1 ,为负数补码,其余位先取反再加 1 ,或者先减 1 ,再取反。
11.IP 地址及相关
图中每类后的 0/10/110/1110/11110 表示 IP 地址第一个数字的8位二级制编码的前缀。
如 B 类前缀为 10,则 B 类一定得从 1\times 2^7+0\times 2^6 开始编号,到1\times 2^7 + 0\times 2^6+ (111111)_2 为止。
12.hash 函数
一:直接定址法
取关键字的某个线性函数值作为散列地址:
f(key)=a*key+b
直接定址法获取得到的散列函数有点就是简单,均匀也不会产生冲突
但问题是这需要事先知道关键字的分布情况
适合查找表较小且连续的情况
由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用
二:数字分析法
如果关键字是位数较多的数字(比如手机号),
且这些数字部分存在相同规律
则可以采用抽取剩余不同规律部分作为散列地址
比如手机号前三位是接入号,中间四位是 HLR 识别号,只有后四位才是真正的用户号
也就是说,如果手机号作为关键字,那么极有可能前 7 位是相同的
此时我们选择后四位作为散列地址就是不错的选择
三:平方取中法
即取关键字平方的中间位数作为散列地址
比如假设关键字是 4321,那么它的平方就是18671041中间的 3 位就可以是 671,也可以是 710,用做散列地址
平方取中法比较适合于不知道关键字的分布,而位数又不是很大的情况
四:折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短些)
然后将这几部分叠加求和
并按散列表表长,取后几位作为散列地址
五:除留余数法
此方法为最常用的构造散列函数方法
对于散列表长为m列函数公式为:f(key)=key%p
六:随机数法
选择一个随机数,关键字的随机函数值为它的散列地址,f(key)=random(key)
13.存储方式
散列存储:
即hash表,一般查找是通过将关键字值与给定值比较来确定位置,效率取决于比较次数。
是一种力图将数据元素的存储位置与关键码之间建立确定对应关系的查找技术。
理想的方法是:不需要比较,根据给定值能直接定位记录的存储位置。
顺序存储:
在计算机中用一组地址连续的存储单元依次存储线性表的各个数据元素,称作线性表的顺序存储结构。
特点:
1、随机存取表中元素。
2、插入和删除操作需要移动元素。
链接存储:
在计算机中用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。
它不要求逻辑上相邻的元素在物理位置上也相邻.因此它没有顺序存储结构所具有的弱点,但也同时失去了顺序表可随机存取的优点。
特点:
1、比顺序存储结构的存储密度小 (每个节点都由数据域和指针域组成,所以相同空间内假设全存满的话顺序比链式存储更多)。
2、逻辑上相邻的节点物理上不必相邻。
3、插入、删除灵活 (不必移动节点,只要改变节点中的指针)。
4、查找结点时链式存储要比顺序存储慢。
5、每个结点是由数据域和指针域组成。
索引存储:
除建立存储结点信息外,还建立附加的索引表来标识结点的地址。索引表由若干索引项组成。
特点:
索引存储结构是用结点的索引号来确定结点存储地址,其优点是检索速度快,缺点是增加了附加的索引表,会占用较多的存储空间。
压缩存储:
对矩阵的存储方式,压缩空间,保留非0元素。
14.逻辑运算符号
以下为一些基本运算符号的真值表:
前四者应该不需要解释,解释一下后两者的含义:
- $P\to Q$(条件): 如果 $P$ 为真那么 $Q$ 必须为真,其等价于 $\neg P \vee Q
**注:** ~~一般题目问你两逻辑表达式是否等价,如果变量比较少,其实直接暴力代数值(Ture/False)即可。~~ (这是迫不得已才干的)
**优先级:** 括号 > 非 > 与 > 或 ,其它的会加括号。
**运算法则:**
与或的运算满足 "结合律","交换律","分配律"。
还有一些恒等的东西如下:
$A\to B=\neg A \vee B
A\vee(A\wedge B)=A\wedge(A\vee B)=A
\neg(A\vee B)=\neg A\wedge\neg B
\neg(A\wedge B)=\neg A\vee\neg B
15.冯诺依曼计算机模型的核心思想有
1、采用二进制表示数据和指令
2、采用“存储程序”工作方式
3、计算机硬件有五大部件(运算器、控制器、存储器、输入和输出设备)
16.操作系统(OS,Operating System)
操作系统的主要作用
操作系统的主要功能是资源管理,程序控制和人机交互等。
计算机系统的资源可分为设备资源和信息资源两大类。
设备资源指的是组成计算机的硬件设备,如中央处理器,主存储器,磁盘存储器,打印机,磁带存储器,显示器,键盘输入设备和鼠标等。
信息资源指的是存放于计算机内的各种数据,如文件,程序库,知识库,系统软件和应用软件等。
操作系统位于底层硬件与用户之间,是两者沟通的桥梁。
用户可以通过操作系统的用户界面,输入命令。
操作系统则对命令进行解释,驱动硬件设备,实现用户要求。
以现代观点而言,一个标准个人电脑的OS应该提供以下的功能:进程管理,内存管理,文件系统,网络通讯,安全机制,用户界面驱动程序。
17.WAVE文件容量计算方式
WAVE文件所占容量=(采样频率×采样位数×声道)×时间/8(1字节=8bit)
其中采样频率的单位为 Hz,遇到 kHz 时记得乘 1000 ,双声道的要乘 2 。
单声道的声道数为1个声道;双声道的声道数为2个声道;立体声道的声道数默认为2个声道(也有 4 个的,具体看题目,没提就算双声道)。
音箱所支持的声道数是衡量音箱档次的重要指标之一。
定理
时间复杂分析
给出一个递推式,让你求复杂度(求通项)
主定理
如果我们要解决规模为 n 的问题,通过分治,得到 a 个规模为 \frac{n}{b} 的问题,每次的额外复杂度为 O(n^d)
则 T(n) = aT(\frac{n}{b})+O(n^d)
T(n)=aT\left(\frac{n}{b}\right)+O(n^d)
T(n)=\begin{cases}O(n^{log_ba})& a >b^d\\O(n^{d}lgn)& a=b^d\\O(n^d)&a<b^d\end{cases}
\log 与 \lg 只是常数级关系,中间那行写成 \lg 问题也不大 。
一阶线性递推式
a_{n+1}=c\cdot a_n+d,\;a_1=b\quad c\ne0,1
根据式子列出特征方程
x=cx+d
得出解
x_0=\frac{d}{1-c}
定理:
若 x_0=a_1 , 则 a_n=a_1 ,即 \{a_n\} 为常数列
若 x_0\ne a_1, 则 a_n= b_n+x_0 ,其中 \{b_n\} 为以 c 为公比的等比数列,即 b_n=b_1c^{n-1},\;b_1=a_1-x_0
故 \{a_n\} 的通项表达式为
a_n=(a_1-x_0)\cdot c^{n-1}+x_0
证明: 咕咕咕
相关资料-有更为朴素的生成函数解法
二阶线性递推式
a_{n+2}=p\cdot a_{n+1}+q\cdot a_{n} \qquad a_1=\alpha,a_2=\beta
根据式子列出特征方程:
x^2-px-q=0
若 x_1,x_2 为方程两个根。
case1:当 x_1\ne x_2 时,数列 \{a_n\} 的通项为:
a_n=Ax_1^{n-1}+Bx_2^{n-1}
其中 A,B 为常数,由 a_1=\alpha,a_2=\beta 决定,可将 a_1,a_2,x_1,x_2 带入,即求解如下方程:
\left\{\;\begin{matrix}
A+B=a_1\\
x_1A+x_2B=a_2
\end{matrix}\right.
case2: 当 x_1= x_2 时,数列 \{a_n\} 的通项为:
a_n=(A+Bn)x_1^{n-1}
同样,将 a_1,a_2,x_1,x_2 带入求 A,B
注意,当x_1,x_2相同时,通项公式明显不同,别搞混了。
定义
欧拉路径
欧拉路是指从图中任意一个点开始到图中任意一个点结束的路径,并且图中每条边都通过且只通过一次,又称欧拉迹。
资料
无向连通图存在欧拉路的条件:
所有点度都是偶数,或者恰好有两个点度是奇数,则有欧拉路。
若有奇数点度,则奇数度点一定是欧拉路的起点和终点,否则可取任意一点作为起点。
有向连通图存在欧拉路的条件:
除两点外,所有入度等于出度。这两点中一点的出度比入度大,另一点的出度比入度小,则存在欧拉路。取出度大者为起点,入度大者为终点。
每个点的入度等于出度,则存在欧拉回路
任意一点有度的点都可以作为起点。
欧拉回路
欧拉回路是指起点和终点相同的欧拉路,又称欧拉闭迹,亦称欧拉环游。
对于无向连通图来说,每个顶点度数都是偶数,就存在欧拉回路
对于有向连通图来说,每个点的入度等于出度,则存在欧拉回路
任意一点有度的点都可以作为起点。
欧拉图
对于连通图G,如果G中存在经过每条边的闭迹,则称G为欧拉图,简称G为E图。资料
即从图中任意一点出发,能找到一种方法遍历完所有边再回到该点的图称为欧拉图,有欧拉闭迹;所以欧拉图一定联通。
若能遍历完所有的边但是没法回到起始点,称为非欧拉图但是有欧拉迹。
欧拉图的每一个顶点都能作为某条欧拉闭迹的起点。
等价人话:
对于图G,它在什么条件下满足从某点出发,经过每条边一次且仅一次,可以回到出发点
一笔画,对于一个图G, 笔不离纸, 一笔画成
定理1:若G满足下列条件中的任意一个,则G是E图,且这些条件都是充要条件
G的顶点度数为偶数
G的边集合能划分为圈
推论1:连通非欧拉图G存在欧拉迹当且仅当G中只有两个顶点度数为奇数
推论2:若G和H是欧拉图,则GxH是欧拉图(证明其顶点度数都是偶数即可)首先注意连通性
Fleury算法解决了在欧拉图中求出一条具体欧拉环游的方法。方法是尽可能避割边行走。算法流程如下:
任选一个起始点 v_0,在与 v_0 相连接的边中选择一条非割边 e_0 ,若实在没有非割边,则随便选择一条即可,此时到达该边的另一顶点v_1,找与v_0相接的非割边。如法炮制直到遍历完所有边。
注:首先前提是在欧拉图上,求的是欧拉回路,那么从任意一点开始都有条欧拉回路,我们想想,如果它走了割边,不就是回不来了吗。所以我们要直到迫不得已的时候再走割边。
哈密尔顿图
如果经过图G的每个顶点恰好一次后能够回到出发点,称这样的图为哈密尔顿图,简称H图。
所经过的闭途径是G的一个生成圈,称为G的哈密尔顿圈。(欧拉图是经过每条边再回去,而哈密尔顿图只是要求经过所有点后回到出发点,不要求经过所有边。)
非哈密尔顿图有可能存在哈密尔顿路。也可知若图中存在割边,则该图一定不是H图。
树状数组
运用了倍增思想,(雾),相当于画出以后树状数组的图后,向上倍增在(add函数中较为明显),向上倍增lowbit()次
C++STL中的sort
运用了快排,堆排和插入排序。
哈弗曼树
哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。
所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数,即为路径上边的个数)。
树的带权路径长度记为WPL=(W1*L1+W2*L2+...+ Wn*Ln),
构造哈夫曼树的算法如下:
1)对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F={T1,T2,T3,...,Ti,..., Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。
2)在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
3)从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
4)重复2)和3),直到集合F中只有一棵二叉树为止。
对于哈夫曼树,有一个很重要的定理:对于具有$n$个叶子节点的哈夫曼树,共有$2*n-1$个节点。
这个定理的解释如下:对于二叉树来说,有三种类型节点,即度数(只算出度)为$2$的节点,度数为$1$的节点和度数为$0$的叶节点。
而哈夫曼树的非叶子节点是由两个节点生成的,因此不能出现度数为$1$的节点,而生成的非叶子节点的个数为叶子节点个数减一,于此定理就得证了。
---------
### 排序算法
稳定性:
不稳定的排序算法:堆排序、快速排序、希尔排序、直接选择排序
稳定的排序算法:基数排序、冒泡排序、直接插入排序、折半插入排序、归并排序
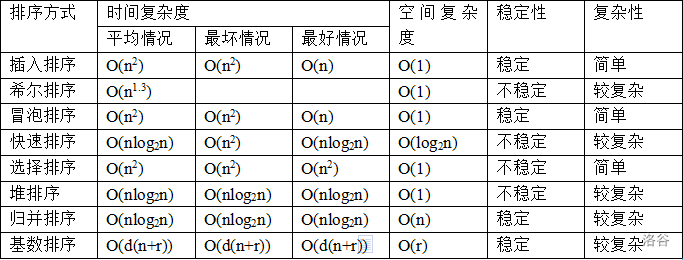
[对于排序算法稳定性的理解](https://www.cnblogs.com/lxy-xf/p/11321536.html)
排序算法的稳定性,稳定的排序算法是指**不会**改变**数值相同**的元素的**相对位置**的排序算法。
**注意** 基数排序不是基于比较的,而是桶排的一种延伸
**注意** 选择排序是不稳定的,原因如下:
选择排序是给每个位置选择当前元素最小的,
比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,
依次类推,直到第n - 1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。
那么,在一趟选择,如果一个元素比当前元素小,而这个元素又出现在一个和当前元素相等的元素后面,
那么交换后稳定性就被破坏了。
举个例子,序列5 8 5 2 9,我们知道第一遍选择第1个元素5会和2交换,
那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
另一种分类——就地排序和非就地排序
就地(原址、原地)排序是指:基本上不需要额外辅助的的空间,允许少量额外的辅助变量进行的排序。
就是在原来的排序数组中比较和交换的排序。
像选择排序,插入排序,希尔排序,快速排序,堆排序等都会有一项比较且交换操作(swap(i,j))的逻辑在其中,
因此他们都是属于原地(原址、就地)排序。
而归并排序,计数排序,基数排序等不是原地排序。
部分常见应用:
快排思路:$rand$一个值,比我小的都在前面,比我大的都在后面,递归求解前后两个部分。(可以开个辅助数组,每次递归的某个区间可以先把区间扫一遍)
基于快排思路的求第$k$大值:$rand$个数,比我大的在后面,小的在前面,看小的个数与$k$值的关系,比较大小,递归查找。
期望复杂度:$O(n)+O(\frac{n}{2})+O(\frac{n}{4})+......$期望为$O(n)
归并思路:分为前一半和后一半,递归前后两个部分使之各自有序,在双指针将前后两个有序数组合并。
卡特兰数
资料:出门左转
学卡特兰数,可能比组合数要难一点,因为组合数可以很明确的告诉你那个公式是在干什么,而卡特兰数却像是在用大量例子来解释什么是卡特兰数
关于Catalan 数
递归定义:f_n=f_0 \times f_{n-1} + f_1 \times f_{n-2} + f_2 \times f_{n-3} + ... + f_{n-1} \times f_0,n >= 2
递推定义: f_n = \frac{4n-2}{n+1} f_{n-1}
计算公式:f_n = (2n)! / (n + 1)! / n! = \frac{1}{n+1} C^{n}_{2n} = f_n=C_{2n}^{n}-C_{2n}^{n-1}
常见问题
在一个w×h的网格上,你最开始在(0,0)上,你每个单位时间可以向上走一格,或者向右走一格,在任意一个时刻,你往右走的次数都不能少于往上走的次数,问走到(n,n),0≤n有多少种不同的合法路径。
图及解答看资料!!
答案为:C^{n}_{2n} - C^{n-1}_{2n} = f_n 即卡特兰数第 n 项。
以下很多问题都可以转化为资料里的图示解答,根据公式 C^{n}_{2n} - C^{n-1}_{2n} = f_n 获得解题的灵感。
$f_n$ 表示含$n$ 对括号的合法括号序列的个数。
$f_n$ 表示长度为$n$ 的入栈序列对应的合法进出栈序列个数。
$f_n$ 表示含$2n$ 个点两两配对,且这两个点之间连一条弦,满足这$n$条弦彼此不相交的个数。
根据公式$f_n=f_0 \times f_{n-1} + f_1 \times f_{n-2} + f_2 \times f_{n-3} + ... + f_{n-1} \times f_0,n >= 2 $ 即递归定义又衍生出许多题的灵感。
$f_n$表示总共有$n$个点,求这$n$个点最终能构成多少二叉树的数量。
$f_n$ 表示通过连接顶点而将$n + 2$ 边的凸多边形分成三角形的方法个数。
-------------------
### 组合数学
资料:[出门左转再右转](https://www.luogu.com.cn/blog/chengni5673/dang-xiao-qiu-yu-shang-he-zi)
小球与盒子的相爱相杀。。。。。
组合数公式$C^{m}_{n} = \frac{n!}{m!(n-m)!}
当然你也可以用杨辉三角求解。
注:杨辉三角
C^m_n$ = $C^{m-1}_{n-1}$ $+$ $C^{m}_{n-1}
证明,相当于n个小球中选m个,要么不选第n个小球,在n-1个小球中选m个,要么选第n个小球,从n-1个里拿m-1个。
普通的插板法,捆绑法,容斥原理,就不介绍了,这篇博文里主要是摘记(非原创)一些对博主有用的东西,而不是真的对某种知识的讲解介绍,具体讲解请移步资料。
接下来我们回到正题,默认问题为 n 个小球放到 m 个盒子里,题型共有三项要求,球是否相同,盒子是否相同,能否有空盒。
1.球相同,盒子不同,不能有空盒
插板法,实质是把n个小球分为m个不为空的小组求方案数。
n-1$个空,放$m-1$个板,$ans = C^{m-1}_{n-1}
2.球相同,盒子不同,可以有空盒
对于每个盒子,我们都先给它一个球,这就和上面一样了,即
ans = C^{m-1}_{n+m-1}
3.球不同,盒子不同,可以有空盒
因为球不同,每个球都是独立的,所以每个球都有m种选择,即
ans = m^n
4.球不同,盒子相同,不能有空盒
对于这类问题的求解有一个神奇的东西叫第二类斯特林数(简称为S2),其定义为将n个物体划分为k个非空无区别的集合的方案数,大致就是把n个不同的小球放入m个相同的盒子中(盒子不为空)的方案数。递推公式为:
s2[i][j] = s2[i-1][j] \times j + s2[i-1][j-1]
(s2[i][j]表示前i个小球放到前j个盒子里的方案数)
对于一个s2[i][j],接下来要再放一个小球,可以放到前j个盒子,方案数为j \times s2[i][j],也可以放到下一个盒子里,方案数为s2[i][j]
代码见资料。
斯特林还有个公式
s2[n][m] = \frac{1}{m!} \times \sum^m_{k=0}(-1)^k \times C^k_m * (m - k)^n
若集合无非空的限制,方法有m^n中,我们枚举为空的盒子,得出C^k_m \times (m - k)^n是多出来的。
这里可能会导致重复(因为(m-k)^n对应的情况仍有可能盒子为空),所以容斥下即(-1)^k
最后除以个m!消掉有序性,若不除则有序。
5.球不同,盒子也不同,不能有空盒
即4中不除以m!的结果
ans = m! \times s2[n][m]
6.球不同,盒子相同,可以有空盒
因为可以有空盒,所以我们枚举有非空盒的个数,加上对应的斯特林数即可。
ans = \sum^{m}_{i=1} s2[n][i]
这东西又叫贝尔数,第n个贝尔数表示集合{1,2,3,4....n}的划分方案数
7.球相同,盒子相同,可以有空盒
设f[n][m]表示n个球放到m个盒子里的方案数
那么,若只有一个盒子或无小球,方案数为1
若小球比盒子少,则小球一定放不满盒子,则f[i][j]=f[i][i]
若小球比盒子多,就分为将盒子放满和没放满两种情况,则:
f[i][j]=f[i-j][j]+f[i][j-1]
解读一下:f[i-j][j]表示将盒子放满的情况,即我先每个盒子抽掉一个球,然后等其余球放好后我再一一还过去,相当于我每个盒子都至少有一个球。
------------
**8.球相同,盒子相同,不能有空盒**
就是跟$7$一样的,我们只要输出$f[n-m][m]$就行了,先抽出$m$个球,再一一放回,即
$ans = f[n-m][m]
范德蒙德卷积
\sum_{i=0}^{k}\binom{n}{i}\binom{m}{k-i}=\binom{n+m}{k}
今天模拟赛莫名其妙就用到了这个,组合意义证明,就是从 n 个小球和 m 个小球中总共选出 k 个小球,这等价于从 n+m 个小球中选出 k 个晓求得 的方案数。
另一个公式
\sum_{k=0}^{n}\binom{k}{x}\binom{n-k}{y}=\binom{n+1}{x+y+1}
特征:上下和为定值,且变量在上面。当然因为组合数上指标小于下指标时为 0 ,所以这个式子可以疯狂魔改,不过符合该特征都可以用组合意义推一波。
发现这和上面的不太一样,不是直接 \binom{n}{x+y} 因为对于同一种组合方案,由于分割线 k 的位置可以在第 x 个和 第 x+1 个球之间任意选择,无法与表达式一一对应,所以不能使用之前的组合意义。
所以我们不妨引入一个新球来代替之前的分割线 k ,相当于分割线就是现在的第 x+1 个球,这样就起到了统计因分割线不同而不同的方案数。
即为
\binom{n+1}{x+y+1}
二项式定理
(a+b)^{n}=\sum\limits_{i=0}^{n}{\binom{n}{i} }a^{n-i}b^i
组合数的吸收
不是很懂,这里举几个例子。
通常我们会遇到 n\binom{n-1}{k} 这样的式子,这个系数放在前面不好看。
那么
\begin{aligned}
n\binom{n-1}{k}=\frac{n!}{k!(n-1-k)!}=(k+1)\frac{n!}{(k+1)!(n-1-k)!}=(k+1)\binom{n}{k+1}
\end{aligned}
这样我们就实现了系数的转换。
可以发现正着看它是把一个定的系数换为我们的枚举项,倒过来看就是把枚举项换为一个定的系数,看上去都挺有用。
一般来说,就是可以把组合数乘上一个下降幂给吸收进来,从而实现上指标和下指标的转换(指系数)。
排列组合进阶
设多重集合 S=\left \{ n_1\cdot a_1,n_2\cdot a_2\dots,n_k\cdot a_k \right \} ,对与整数r(r<\forall n_i)
从S 中选择r个元素组成一个多重集的方案数就是 多重集的组合数
其问题等价于,x_1+x_2\dots x_k=r的非负整数解的个数,隔板法得到:\LARGE \binom{r+k-1}{k-1}
以上问题的加强版是:没有r<\forall n_i这一条件
同样地,转化为线性方程x_1+x_2+\dots x_k=r 的非负解且 \forall x_i\le r
可见是一个容斥,模型如下:
全集: \sum\limits_{i=1}^{k}x_i =r的整数解,
属性:P_i 为 x_i \le n_i
考虑\overline{S_i}为不满足属性P_i的集合,即x_i\ge n_i+1
根据容斥原理:
\left | \bigcup_{i=1}^{k}{\overline{S_i}} \right |=\sum_{m=1}^{k}(-1)^{m-1}\sum_{A}\left|\bigcap_{i=1}^{m}{\overline{S_{a_i}}}\right|\\
解释一下,其中m 用来枚举个数,A 用于子集的枚举,满足|A|=m,a_i<a_{i+1}
根据弱化版中的结论,得到
\sum_{A}\left|\bigcap_{i=1}^{m}{\overline{S_{a_i}}}\right|=\sum_{A}{\binom{r+k-1-\sum{n_{a_i}-m}}{k-1}}
圆排列
n$个人围成一个一个圆的排列数,记作$Q_{n}^{n}
考虑从中间选一个地方断开得到了n个人的全排列,即
\large Q_{n}^{n}\times n=A_{n}^{n}\Rightarrow Q_{n}^{n}=\frac{A_{n}^{n}}{n}=(n-1)!
由此可见,部分圆排列:\large Q_n^r=C_n^r\times Q_r^r =\frac{n!}{r\times (n-r)!}
注:部分圆排列指n个人里面选r个进行圆排列。
错位排列
以下内容摘自 OI-wiki 资料
我们把错位排列问题具体化,考虑这样一个问题:
假设我们考虑到第 $n$ 个信封,初始时我们暂时把第 n 封信放在第 n 个信封中,然后考虑两种情况的递推:
前面$n-1$个信封全部装错;
前面$n-1$个信封有一个没有装错其余全部装错。
对于第一种情况,前面$n-1$个信封全部装错:因为前面$n-1$个已经全部装错了,所以第 $n$ 封只需要与前面任一一个位置交换即可,总共有 $(n-1)\times f(n-1)$ 种情况。
对于第二种情况,前面$n-1$个信封有一个没有装错其余全部装错:考虑这种情况的目的在于,若$n-1$个信封中如果有一个没装错,那么我们把那个没装错的与$n$交换,即可得到一个全错位排列情况。
其他情况,我们不可能通过一次操作来把它变成一个长度为 $n$ 的错排。
于是可得错位排列的递推式为 $f[n]=(n-1)\ast (f[n-1]+f[n-2])$ 。
错位排列数列的前几项为 $0,1,2,9,44,265$ 。
---------------------------
### 组合数性质|二项式推论
$$
\sum_{i=0}^{m}\binom{n}{i}\binom{m}{m-i}=\binom{m+n}{m} (n\ge m)\tag{1}
$$
不难想象就是从两个没有交集、大小分别为$n,m$的集合中选$m$个,该公式用来组合数的拆分
当$m=n$时,就得到了:
$$
\sum_{i=0}^{n}{\binom{n}{i}^2}=\binom{2n}{n}
$$
---
$$
\sum_{i=0}^{n}{i\binom{n}{i}}=n2^{n-1}\tag 2
$$
证明:将左边和式内变换一下:
$$
i\binom{n}{i}=i\times \frac{n!}{i!(n-i)!}=n\times \frac{(n-1)!}{(i-1)!(n-i)!}=n\binom {n-1}{i-1}\\
左边\Rightarrow n\times\sum\limits_{i=0}^{n}{\binom{n-1}{i-1}}=n2^{n-1}=右边
$$
-------
$$
\sum_{i=1}^{n}{i^2\binom{n}{i}}=n(n+1)2^{n-2}\tag{3}
$$
证明:变换一下左边式子:
$$
{i^2\binom{n}{i}}=i^2\times\frac{n!}{i!(n-i)!}=ni\times\frac{(n-1)!}{(i-1)!(n-i)!}=n\times{i\binom{n-1}{i-1}}
\\ \Rightarrow\sum_{i=0}^{n}{i^2\binom{n}{i}}=n\times\sum_{i=0}^{n}{\left\{(i-1)\binom{n-1}{i-1}+\binom{n-1}{i-1}\right\} }\\
$$
根据$(2)$:
$$
左边=n(n-1)2^{n-2}+n2^{n-1}=n(n+1)2^{n-2}=右边
$$
证毕!
---
$$
\sum_{l=k}^{n}\binom{l}{k}=\binom{n+1}{k+1}\tag 4
$$
在杨辉三角上考虑这个和式就不难证明
---
$$
\binom{n}{r}\binom{r}{k}=\binom{n}{k}\binom{n-k}{r-k}\tag 5
$$
化成阶乘的形式证就行了
---
$$
\sum_{i=0}^{n}\binom{n-i}{i}=F_{n+1}\tag 6
$$
$F$是斐波那契数列
$$
\sum_{i=0}^{n}{\binom{n-i}{i}}=\sum_{i=0}^{n-1}{\binom{n-1-i}{i}}+\sum_{i=0}^{n-2}{\binom{n-2-i}{i}}
$$
发现这三个式子是同构的,即:$G_n=G_{n-1}+G_{n-2}
考虑到:G_1=1,G_2=2\Rightarrow G_n=F_{n+1}
证毕!
四次方和公式
求:
\sum_{i=1}^n i^4
显然 是一个 4+1 次的多项式,( n个四次不就是五次了吗,感谢Moonpie口糊)。
于是有一种作差的巧妙做法,而且对于任意次方前缀和都适用。
显然 (n+1)^5-n^5=5n^4+10n^3+10n^2+5n+1
然后 1,2,3\dots n 依次都代进去:
\begin{aligned}
2^5-1^5&=5\cdot 1^4+10\cdot1^3+10\cdot1^2+5\cdot1+1\\
3^5-2^5&=5\cdot 2^4+10\cdot2^3+10\cdot2^2+5\cdot2+1\\
4^5-3^5&= 5\cdot 3^4+10\cdot3^3+10\cdot3^2+5\cdot3+1\\
5^5-4^5&=5\cdot 4^4+10\cdot4^3+10\cdot4^2+5\cdot4+1\\
&\;\;\vdots\\
n^5-(n-1)^5&=5\cdot (n-1)^4+10\cdot (n-1)^3+10\cdot (n-1)^2+5\cdot (n-1)+1\\
(n+1)^5-n^5&=5\cdot n^4+10\cdot n^3+10\cdot n^2+5\cdot n+1\\
\end{aligned}
全部加起来:
(n+1)^5-1=5\cdot\sum_{i=1}^n i^4+10\cdot\sum_{i=1}^n i^3+
10\sum_{i=1}^n i^2+5\cdot\sum_{i=1}^n i+\sum_{i=1}^n i^0\\
5\cdot\sum_{i=1}^n i^4=(n+1)^5-10\cdot\sum_{i=1}^n i^3-
10\cdot\sum_{i=1}^n i^2-5\cdot\sum_{i=1}^n i^1-\sum_{i=1}^n i^0-1\\
5\cdot\sum_{i=1}^n i^4=(n+1)^5-10\cdot\frac{1}{4}(n+1)^2n^2-10\cdot\frac{1}{6}(2n+1)(n+1)n-5\cdot\frac{1}{2}(n+1)n-n-1\\
\vdots\\
\text{自行化简}\\
\vdots\\
\sum_{i=1}^n i^4=\frac{1}{30} (3n^2+3n-1)(2n+1)(n+1)n
注:引用的公式
\sum_{i=1}^n i=\frac{1}{2}(n+1)n\\
\sum_{i=1}^n i^2=\frac{1}{6}(2n+1)(n+1)n\\
\sum_{i=1}^n i^3=\frac{1}{4}(n+1)^2n^2
不常见的C++语言命令
防止看不懂码风清奇的阅读程序 (这东西防不来)
switch
switch(a){
case 1://a==1
cout << "hi" << endl;
break;
case 2://a==2
cout << "hello" << endl;
break;
default://否则,即不满足上述条件
cout << "goodbye" << endl;
}
/*
case 相当于 goto part; 中类似part一样的入口,即满足条件,就开
始执行case下面的语句,但是如果每个case中没有break,可能会执行
下一个case或default中的内容。当然,若是最后一个case/default,
那加不加break无所谓,因为后面没东西了。
*/
#include <iomanip>
//io流控制头文件, 主要是一些操纵用法如setw(int n),setprecision(int n)
/*
这里面iomanip的作用:
主要是对cin,cout之类的一些操纵运算子,比如setfill,setw,setbase,setprecision等等。它是I/O流控制头文
件,就像C里面的格式化输出一样.
只要cin,cout中没有一些如set-的奇怪东西,就不需要用这个头文件。
*/
setprecision(n)
/*
使用setprecision(n)可控制输出流显示浮点数的数字个数。
C++默认的流输出数值有效位是6。
如果setprecision(n)与setiosflags(ios::fixed)合用,
可以控制小数点右边的数字个数。
setiosflags(ios::fixed)是用定点方式表示实数。
*/
setw(int n)
/*
用来控制输出间隔。
例如:
cout<<'s'<<setw(8)<<'a'<<endl;
则在屏幕显示
s a
s与a之间有7个空格,
setw()只对其后面紧跟的输出产生作用,
如上例中,表示'a'共占8个位置,不足的用空格填充。
若输入的内容超过setw()设置的长度,则按实际长度输出。
setw()默认填充的内容为空格,
可以setfill()配合使用设置其他字符填充。
如
cout<<setfill('*')<<setw(5)<<'a'<<endl;
则输出:
****a //4个*和字符a共占5个位置。
*/
Sundat(const int &T)
/*
const int &T和const int T的比较
首先,const int &T会更省空间,因为它直接引用,而不是像const int T一样直接新开一个地址空间。
第二,它取地址,实参会改变
*/
void fun(int *x,int *y){
int *t;
t=x,x=y,y=t;//case 1
*t=*x,*x=*y,*y=*t;//case 2
}
/*
int *x=a;这是指针的定义式,表示x指向a的地址
x=&a表示指针x指向a的地址
case 1,不会导致两个指针中的值交换,因为它只是把两个指针交换,即原本x指a,y指b,现在是x指b,y指a,
又因为*x,*y是形参,函数中指向的改变不会导致主函数里的x,y改变。
case 2,导致x,y里的东西交换,因为*t=*x,*t表示t指针里指的东西,
x指的东西与y指的东西交换,即地址内的东西交换,值发生改变。
*/