浅谈分块
逃离地球
2019-12-03 17:26:06
## 浅谈分块
##### author:yqr
今天我来介绍一下**分块**这个**暴力数据结构**。
首先来看一个问题:
#### **维护一个数列,支持两个操作:区间修改和区间求和。**
显然,这是线段树或者树状数组的板子题,但是这道题也可以用**分块**来做。
**那么分块有什么好处呢?更快?还是更好写?**
对于这个问题来说,分块似乎真的没有什么好处,时间复杂度为 $O(m\sqrt n)$,代码也没有树状数组短。
**所以分块有什么用?**
~~没用~~ 分块可以解决一些树状数组和线段树无法解决的问题,这类问题我会在之后的例题中讲到。
------------
那我们就借助上面的这道例题来理解分块。
分块的主要思路就是把整个数列划分成很多块,对每个块进行预处理,每次进行询问时,对询问区间内的整块进行快速读取,而对非整块进行暴力遍历,最终求出结果。
这么说可能比较抽象,举个例子:
现在有9个数:$6,9,8,1,4,6,7,0,2$
我们就可以把这9个数分成3块,并统计每块的数字和:
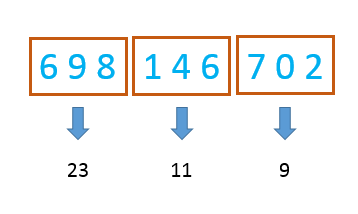
##### 1、询问
此时如果询问 $a_1+a_2+...+a_6$ 的和,我们可以不用遍历每块里的内容而直接得出结果:$23+11=34$.
那假如询问 $a_2+a_3+...+a_7$ 的值呢?
此时,分块这个数据结构的暴力就体现出来了。我们直接遍历不在整块中的数,即 $a_2$,$a_3$ 和 $a_7$,计算他们的和,再加上所有整块的和就可以了。即 $9+8+11+7=35$.
总结一下,分块的询问操作就是快速求整块,再暴力求零块。
##### 2、修改
区间修改的思路也是类似如此,快速修改整块,再暴力修改零块。
具体地说,对于每个整块,我们可以记录一个add值,表示这个整块每个数的真实值都是当前数组中记录的值加上这一块的add值。比如如果上图中第二块的add值是5,而第5个数的数组记录值为4,则第5个数的真实值就是9。
总结一下,修改操作就是快速修改整块的add值,再暴力修改零块的数组记录值。
有了这个例子,应该就可以理解分块是什么了,毕竟分块的确是一个很直观、很暴力的数据结构。
那究竟应该把大的数组分成多少小块呢?这因题而异。对于这道题来说,分成 $\sqrt n$ 块是最快的,~~十分不严谨的~~证明如下:
>设共有 $n$ 个数,$m$ 次操作,分成 $T$ 块,则每块有 $n/T$ 个数。
>
>对于每次操作,都要对整块和零块进行操作,复杂度为 $O(T+n/T)$
>
>根据均值不等式,有 $T+n/T\ge 2\sqrt n$,当 $T=\sqrt n$ 时取最小值。
>
>综上,应分成 $\sqrt n$ 块,每块有 $\sqrt n$ 个数,此时算法时间复杂度为 $O(m\sqrt n)$
现在还有一个问题,如果n不是完全平方数怎么办?只需要把n分成 $\lfloor \sqrt n\rfloor +1$ 块,前 $\lfloor \sqrt n\rfloor$ 块每块都有 $\lfloor \sqrt n\rfloor$ 个数,最后一块有剩下的数即可。
上代码!([Luogu P3372 【模板】线段树 1](https://www.luogu.com.cn/problem/P3372)):
```cpp
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
inline ll read() {
ll ret = 0, f = 1; char ch = getchar();
while (ch < '0' || ch > '9') {if (ch == '-') f = -f; ch = getchar();}
while (ch >= '0' && ch <= '9') ret = ret * 10 + ch - '0', ch = getchar();
return ret * f;
}
const ll MAXN = 100003;
ll n, m, belong[MAXN], a[MAXN], L[MAXN], R[MAXN], sum[MAXN], add[MAXN], t;
//belong[i]代表第i块属于的块的编号,a数组保存数组记录值
//L[i]和R[i]分别代表第i块的最左边的节点编号和最右边的节点编号
//sum[i]表示第i块的数字和,add[i]表示第i块的add值
ll l, r, ans;
inline void modify(ll x, ll y, ll k) {
l = belong[x], r = belong[y];
if (l == r) {
//如果中间没有完整块就暴力
for (ll i = x; i <= y; ++i) {
a[i] += k;
}
sum[l] += (y - x + 1) * k;
}
else {
for (ll i = x; i <= R[l]; ++i) {
a[i] += k;
}
sum[l] += (R[l] - x + 1) * k;
//左边零块暴力修改
for (ll i = L[r]; i <= y; ++i) {
a[i] += k;
}
sum[r] += (y - L[r] + 1) * k;
//右边零块暴力修改
for (ll i = l + 1; i <= r - 1; ++i) {
add[i] += k;
}
//修改中间整块add值
}
}
inline ll query(ll x, ll y) {
l = belong[x], r = belong[y], ans = 0;
if (l == r) {
//如果中间没有完整块就暴力
for (ll i = x; i <= y; ++i) {
ans += a[i];
}
ans += (y - x + 1) * add[l];
}
else {
for (ll i = x; i <= R[l]; ++i) {
ans += a[i];
}
ans += (R[l] - x + 1) * add[l];
//左边零块暴力读取
for (ll i = L[r]; i <= y; ++i) {
ans += a[i];
}
ans += (y - L[r] + 1) * add[r];
//右边零块暴力读取
for (ll i = l + 1; i <= r - 1; ++i) {
ans += (sum[i] + (R[i] - L[i] + 1) * add[i]);
}
//快速读取中间整块和
}
return ans;
}
int main() {
n = read(), m = read();
for (ll i = 1; i <= n; ++i) a[i] = read();
t = sqrt(n);
for (ll i = 1; i <= t; ++i) R[i] = t * i, L[i] = t * (i - 1) + 1;
if (R[t] < n) ++t, L[t] = R[t - 1] + 1, R[t] = n;//处理最后一块
for (ll i = 1; i <= t; ++i)
for (ll j = L[i]; j <= R[i]; ++j)
belong[j] = i, sum[i] += a[j];
//分块
ll op, x, y, k;
for (ll i = 1; i <= m; ++i) {
op = read();
if (op == 1) {
x = read(), y = read(), k = read();
modify(x, y, k);
}
else {
x = read(), y = read();
printf("%lld\n", query(x, y));
}
}
return 0;
}
```
#### 例题1:
[Luogu P4168 [Violet]蒲公英](https://www.luogu.com.cn/problem/P4168)
这是一道经典的在线求区间众数问题,题意就是给n个数,m次询问,每次询问一个区间内出现次数最多的数。($n\le40000,m\le50000$)
首先我们可以发现区间众数并不是一个满足区间可加性的问题,即我们知道一个区间的几个子区间的众数之后并不能得到整个区间的众数。所以线段树和树状数组解决这个问题并不是十分容易,在这时我们便可以考虑用分块解决这个问题。
假设我们询问的区间是 $[l,r]$,其中整块区间是 $[L,R]$,零块区间是 $[l,L)$ 和 $(R,r]$,那么此时可以得到一个性质:**区间 $[l,r]$ 的众数一定是 $[L,R]$ 的众数或在 $[l,L)$ 或 $(R,r]$ 中出现的数。**正确性显然:若一个数没有在零块中出现过,又不是整块的众数,那么这个数出现次数一定小于整块的众数。
此时分块的性质就体现出来了,我们可以预处理出所有第 $i$ 个区间到第 $j$ 个区间的众数和每个数出现的次数,对于每次询问,我们暴力便历零块中的数,结合已经预处理好的整块中每个数出现的次数,统计出这个区间里所有在零块中出现的数出现的次数,结合刚才的结论,把这些数和整块的众数出现的次数进行比较,次数最多的就是区间的众数。设共分了 $T$ 块,那么每次询问的时间复杂度就是 $O(\frac{T}{N})$.
现在来说预处理部分,对于统计所有第 $i$ 个区间到第 $j$ 个区间每个数出现的次数,我们只需要维护一个前缀和数组,时间复杂度 $O(n)$ 。而对于统计所有第 $i$ 个区间到第 $j$ 个区间的众数,也可以利用上面的那个性质,假设我们求出了第 $i$ 个区间到第 $j-1$ 个区间的众数,我们只需要遍历第 $j$ 个区间并进行统计即可。时间复杂度 $O(NT^2)$。
综上,算法时间复杂度为 $O(NT^2+MN/T)$ ,此时 $T=\sqrt[3] N$ 时最优。(由于我数学太菜,真不会证。。。)
#### 习题:
[Luogu U98797 天塌了](https://www.luogu.com.cn/problem/U98797)
这是我出的题,所以数据很水,可能可以用某些不是分块的算法就能A。
提示:块内排序