动态DP基础
GKxx
2018-12-28 16:22:01
### 引例:最大子段和问题
一个序列的最大子段和是指,从序列中找出一段连续的子段,最大化这个子段的和。
设$f_i$表示以$a_i$结尾的最大子段和,$g_i$表示$[1,i]$的最大子段和,显然有转移
$$f_i=\max\{f_{i-1}+a_i,a_i\}$$
$$g_i=\max\{g_{i-1},f_i\}$$
求整个序列最大子段和的代码如下
```cpp
g[0] = -inf;
for (int i = 1; i <= n; ++i) {
f[i] = max(f[i - 1] + a[i], a[i]);
g[i] = max(g[i - 1], f[i]);
}
printf("%d\n", g[n]);
```
下面的问题是:给一个长度为$n$的序列,$m$次操作,支持单点修改,查询区间最大子段和。[传送门:GSS3](https://www.luogu.org/problemnew/show/SP1716)
本题的经典做法是用线段树维护$lmax,rmax,sum,ans$,分别表示区间的最大前缀和、最大后缀和、和、最大子段和。这种做法是基于一种分治的思想。但其实,上面提到的DP做法也可以完成这道题,只是需要魔改一番。
**但是线段树还是需要的,如果不会线段树请先去[模板区](https://www.luogu.org/problemnew/show/P3372)学习**
注:本文对于数据结构有一定的要求。不过没学过线段树、树剖、平衡树、lct中的任何一个数据结构的朋友也不要急着走开,毕竟矩阵乘法的部分内容还是很好理解的而数据结构只是个壳子而已。另外本文末尾附赠NOIP2018保卫王国的倍增题解,不借助任何数据结构。
### 矩阵乘法
基本的矩阵乘法请直接看[这一期日报](https://shehuizhuyihao.blog.luogu.org/post-zhen-sheng-fa)
这时候你应该已经会用矩阵快速幂求斐波那契数列第$n$项了,时间复杂度$O(k^3\log n)$,其中$k=2$。如果不会的话请点开上面的链接。
顺便可以练习一下:如何构造这种矩阵
$$f_n=3f_{n-1}+4f_{n-2}+7\times 2^n+5n^3+6n^2+3n-2$$
$$\begin{bmatrix}3&4&7&5&6&3&-2\\1&0&0&0&0&0&0\\0&0&2&0&0&0&0\\0&0&0&1&3&3&1\\0&0&0&0&1&2&1\\0&0&0&0&0&1&1\\0&0&0&0&0&0&1\end{bmatrix}\begin{bmatrix}f_{n-1}\\f_{n-2}\\2^n\\n^3\\n^2\\n\\1\end{bmatrix}=\begin{bmatrix}f_n\\f_{n-1}\\2^{n+1}\\(n+1)^3\\(n+1)^2\\n+1\\1\end{bmatrix}$$
体会一下,非常有趣啊...(出现了杨辉三角?)
### 求区间最大子段和
掏出一开始我们列的dp式子:
设$f_i$表示以$a_i$结尾的最大子段和,$g_i$表示$[1,i]$的最大子段和,显然有转移
$$f_i=\max\{f_{i-1}+a_i,a_i\}$$
$$g_i=\max\{g_{i-1},f_i\}$$
然而我们发现,这个式子似乎不怎么好写成矩阵乘法,因为这里有一个矩阵乘法里不涉及的运算:$\max$
#### 广义的矩阵乘法
其实矩阵乘法的结合律能够成立,只依靠一个条件:乘法对加法有分配律。即
$$a\times(b+c)=a\times b+a\times c$$
简单感受(证明)一下矩阵乘法的结合律
设矩阵$A,B,C$分别是$n\times m, m\times p, p\times q$的,那么
$$(ABC)_{i,j}=\sum\limits_{k=1}^p (AB)_{i,k}C_{k,j}$$
$$=\sum\limits_{k=1}^p C_{k,j}\sum\limits_{t=1}^m A_{i,t}B_{t,k}$$
交换求和符号
$$=\sum\limits_{t=1}^m A_{i,t}\sum\limits_{k=1}^pB_{t,k}C_{k,j}$$
$$=(A(BC))_{i,j}$$
得证。
所以结合律成立的核心在于这个交换求和号的过程能够成立,而这依赖于乘法对加法的分配律。
而加法对$\min/\max$其实也有分配律:
$$a+\max\{b,c\}=\max\{a+b,a+c\}$$
$$a+\min\{b,c\}=\min\{a+b,a+c\}$$
所以我们可以重新定义矩阵乘法:
$$C_{i,j}=\max_k\{A_{i,k}+B_{k,j}\}$$
$$C_{i,j}=\min_k\{A_{i,k}+B_{k,j}\}$$
再看看我们熟悉的Floyd:
$$dist_{i,j}=\min_k\{dist_{i,k}+dist_{k,j}\}$$
是不是很妙
其实Floyd算法就可以看做一种矩阵乘法。而Floyd本身是一种DP,种种迹象表明DP与矩阵有着密切的联系。
这样的矩阵乘法依然有结合律,证明过程就只要把相应的运算改改就好了。
有了这种新的矩阵乘法,我们就可以尝试把上面的DP转移写成矩阵:
$$\begin{bmatrix}a_i&\\&&\end{bmatrix}\begin{bmatrix}f_{i-1}\\g_{i-1}\end{bmatrix}=\begin{bmatrix}f_i\\g_i\end{bmatrix}$$
然后你会发现你写不下去了。
可能需要再来一行
$$\begin{bmatrix}a_i&-\infty&a_i\\&&&\\-\infty&-\infty&0\end{bmatrix}\begin{bmatrix}f_{i-1}\\g_{i-1}\\0\end{bmatrix}=\begin{bmatrix}f_i\\g_i\\0\end{bmatrix}$$
然后你会发现$g_i=\max\{g_{i-1},f_i\}$这东西不好办。
机智的你马上想到可以把$f_i$拆开:$g_i=\max\{g_{i-1},f_{i-1}+a_i,a_i\}$
$$\begin{bmatrix}a_i&-\infty&a_i\\a_i&0&a_i\\-\infty&-\infty&0\end{bmatrix}\begin{bmatrix}f_{i-1}\\g_{i-1}\\0\end{bmatrix}=\begin{bmatrix}f_i\\g_i\\0\end{bmatrix}$$
完美。
那么数列的每个元素$a_i$都对应自己的一个矩阵$A_i=\begin{bmatrix}a_i&-\infty&a_i\\a_i&0&a_i\\-\infty&-\infty&0\end{bmatrix}$
对于一个询问$[l,r]$,只要我们能快速求出$A_l$到$A_r$的矩阵乘积即可。考虑到矩阵乘法具有结合律,不难想到用线段树来维护区间矩阵乘积。那么这题就做完了。
这种东西当然支持单点修改,所以它有一个非常响亮的名字:**动态DP**
附GSS3 AC代码:支持单点修改,区间查询最大子段和。
```cpp
#include <cctype>
#include <cstdio>
#include <climits>
#include <algorithm>
template <typename T> inline void read(T& x) {
int f = 0, c = getchar(); x = 0;
while (!isdigit(c)) f |= c == '-', c = getchar();
while (isdigit(c)) x = x * 10 + c - 48, c = getchar();
if (f) x = -x;
}
template <typename T, typename... Args>
inline void read(T& x, Args&... args) {
read(x); read(args...);
}
template <typename T> void write(T x) {
if (x < 0) x = -x, putchar('-');
if (x > 9) write(x / 10);
putchar(x % 10 + 48);
}
template <typename T> void writeln(T x) { write(x); puts(""); }
template <typename T> inline bool chkmin(T& x, const T& y) { return y < x ? (x = y, true) : false; }
template <typename T> inline bool chkmax(T& x, const T& y) { return x < y ? (x = y, true) : false; }
const int maxn = 5e4 + 207, inf = INT_MAX >> 2;
struct Matrix {
int data[3][3];
};
Matrix mat[maxn << 2];
int a[maxn];
int n, m;
inline Matrix mul(const Matrix& A, const Matrix& B) {
Matrix C;
// 这里我们对“零矩阵”给出了新的定义,“零矩阵”的所有元素都是负无穷大。这是为了配合新的矩阵乘法。
for (int i = 0; i <= 2; ++i)
for (int j = 0; j <= 2; ++j)
C.data[i][j] = -inf;
for (int k = 0; k <= 2; ++k)
for (int i = 0; i <= 2; ++i)
for (int j = 0; j <= 2; ++j)
chkmax(C.data[i][j], A.data[i][k] + B.data[k][j]);
return C;
}
inline void update(int o) {
mat[o] = mul(mat[o << 1], mat[o << 1 | 1]);
}
void build(int o, int l, int r) {
if (l == r) {
mat[o].data[0][0] = mat[o].data[0][2] = mat[o].data[1][0] = mat[o].data[1][2] = a[l];
mat[o].data[0][1] = mat[o].data[2][0] = mat[o].data[2][1] = -inf;
mat[o].data[1][1] = mat[o].data[2][2] = 0;
return;
}
int mid = (l + r) >> 1;
build(o << 1, l, mid);
build(o << 1 | 1, mid + 1, r);
update(o);
}
void modify(int o, int l, int r, int p, int v) {
if (l == r) {
mat[o].data[0][0] = mat[o].data[0][2] = mat[o].data[1][0] = mat[o].data[1][2] = v;
return;
}
int mid = (l + r) >> 1;
if (p <= mid) modify(o << 1, l, mid, p, v);
else modify(o << 1 | 1, mid + 1, r, p, v);
update(o);
}
Matrix query(int o, int lb, int rb, int l, int r) {
if (l <= lb && r >= rb) return mat[o];
int mid = (lb + rb) >> 1;
if (l <= mid && r > mid)
return mul(query(o << 1, lb, mid, l, r), query(o << 1 | 1, mid + 1, rb, l, r));
else {
if (l <= mid) return query(o << 1, lb, mid, l, r);
else return query(o << 1 | 1, mid + 1, rb, l, r);
}
}
int main() {
read(n);
for (int i = 1; i <= n; ++i) read(a[i]);
build(1, 1, n);
read(m);
while (m--) {
int q; read(q);
if (q) {
int l, r; read(l, r);
if (l > r) std::swap(l, r);
Matrix ret = query(1, 1, n, l, r);
writeln(std::max(ret.data[1][0], ret.data[1][2]));
} else {
int x, y;
read(x, y);
a[x] = y;
modify(1, 1, n, x, y);
}
}
return 0;
}
```
### 求树的最大点权独立集
给一棵树,$m$次操作,每次修改一个点的点权,请你在每次修改之后都求出这棵树的[最大点权独立集](https://www.luogu.org/problemnew/show/P1352)的权值大小。
[模板题传送门](https://www.luogu.org/problemnew/show/P4719)
首先我们还是写出一个普通的DP:
$f(x,0/1)$表示以$x$为根的子树,$x$不选/选,最大点权独立集权值。
$$f(x,0)=\sum_v\max\{f(v,0),f(v,1)\}$$
$$f(x,1)=\sum_v f(v,0)+a_x$$
~~根据经验~~我们应该需要把这个DP方程写成矩阵乘法,然后用一个数据结构来维护。树上问题的数据结构,马上可以联想到树剖/LCT。(在阅读这部分内容之前,树剖或LCT至少要会一个,不会的话[树剖模板](https://www.luogu.org/problemnew/show/P3384) [LCT模板](https://www.luogu.org/problemnew/show/P3690),或者直接跳到下一道题)无论树剖还是LCT,都是把树剖分成重链和轻边。比如现在我们已经用某种剖分方式把树剖分成了这样:
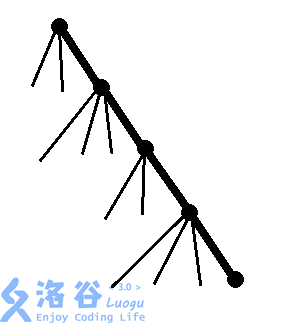
我们的数据结构能够维护的是序列,放在树上就是重链,因此我们需要提取出一些与重链无关的信息来。所以我们设$g(x,0/1)$表示以$x$为根的子树中,不包含$x$所在重链的结点的部分(但是包含$x$自己)的最大点权独立集权值。记$son(x)$为$x$的重儿子,那么有
$$g(x,0)=\sum\limits_{v\neq son(x)}\max\{f(v,0),f(v,1)\}$$
$$g(x,1)=\sum\limits_{v\neq son(x)}f(v,0)+a_x$$
这时候我们就可以改写$f(x,0/1)$的转移方程
$$f(x,0)=g(x,0)+\max\{f(son(x),0),f(son(x),1)\}$$
$$f(x,1)=g(x,1)+f(son(x),0)$$
不难改写成矩阵的形式:
$$\begin{bmatrix}g(x,0)&g(x,0)\\g(x,1)&-\infty\end{bmatrix}\begin{bmatrix}f(son(x),0)\\f(son(x),1)\end{bmatrix}=\begin{bmatrix}f(x,0)\\f(x,1)\end{bmatrix}$$
那么就可以树剖+线段树$O(m\log^2n)$或者LCT$O(m\log n)$维护了。
并且,此题的LCT既不L也不C,自然也不需要翻转标记,只要access就行了。在access的时候,儿子的轻重发生了变化,需要更改相应的$g$值,其实就是LCT维护子树信息的做法。详见代码。
个人认为此题LCT比树剖好写,一是因为LCT可以直接access比较省事,而树剖需要一条链一条链往上跳;二是因为LCT在一开始全是轻边,$f$和$g$相等,初始化比较方便。并且这可能是为数不多的LCT比树剖快的题了...
附上LCT的代码
```cpp
#include <cctype>
#include <cstdio>
#include <climits>
#include <algorithm>
template <typename T> inline void read(T& x) {
int f = 0, c = getchar(); x = 0;
while (!isdigit(c)) f |= c == '-', c = getchar();
while (isdigit(c)) x = x * 10 + c - 48, c = getchar();
if (f) x = -x;
}
template <typename T, typename... Args>
inline void read(T& x, Args&... args) {
read(x); read(args...);
}
template <typename T> void write(T x) {
if (x < 0) x = -x, putchar('-');
if (x > 9) write(x / 10);
putchar(x % 10 + 48);
}
template <typename T> void writeln(T x) { write(x); puts(""); }
template <typename T> inline bool chkmin(T& x, const T& y) { return y < x ? (x = y, true) : false; }
template <typename T> inline bool chkmax(T& x, const T& y) { return x < y ? (x = y, true) : false; }
const int maxn = 1e5 + 207, inf = INT_MAX;
struct Matrix {
long long data[2][2];
// 注意初值
Matrix() {
data[0][0] = data[0][1] = data[1][0] = data[1][1] = -inf;
}
};
int v[maxn << 1], head[maxn], next[maxn << 1], a[maxn], tot;
// val是一个结点保存的矩阵,prd是splay上一棵子树的矩阵乘积,也就是实链上的一个区间的矩阵乘积。
Matrix val[maxn], prd[maxn];
int fa[maxn], ch[maxn][2];
int dp[maxn][2];
int n, m;
inline Matrix mul(const Matrix &A, const Matrix &B) {
Matrix C;
for (int k = 0; k <= 1; ++k)
for (int i = 0; i <= 1; ++i)
for (int j = 0; j <= 1; ++j)
chkmax(C.data[i][j], A.data[i][k] + B.data[k][j]);
return C;
}
inline void ae(int x, int y) {
v[++tot] = y; next[tot] = head[x]; head[x] = tot;
v[++tot] = x; next[tot] = head[y]; head[y] = tot;
}
// 一开始全是轻边,只要照常做DP即可,不需要分f和g。
void dfs(int x) {
dp[x][1] = a[x];
for (int i = head[x]; i; i = next[i])
if (v[i] != fa[x]) {
fa[v[i]] = x;
dfs(v[i]);
dp[x][0] += std::max(dp[v[i]][0], dp[v[i]][1]);
dp[x][1] += dp[v[i]][0];
}
val[x].data[0][0] = val[x].data[0][1] = dp[x][0];
val[x].data[1][0] = dp[x][1];
prd[x] = val[x];
}
// 以下是LCT部分,不需要翻转标记
inline void update(int x) {
prd[x] = val[x];
if (ch[x][0]) prd[x] = mul(prd[ch[x][0]], prd[x]);
if (ch[x][1]) prd[x] = mul(prd[x], prd[ch[x][1]]);
}
inline int iden(int x) {
return ch[fa[x]][0] == x ? 0 : (ch[fa[x]][1] == x ? 1 : -1);
}
inline void rotate(int x) {
int d = iden(x), y = fa[x];
if (~iden(y)) ch[fa[y]][iden(y)] = x;
fa[x] = fa[y];
if ((ch[y][d] = ch[x][d ^ 1])) fa[ch[x][d ^ 1]] = y;
fa[ch[x][d ^ 1] = y] = x;
update(y); update(x);
}
inline void splay(int x) {
while (~iden(x)) {
int y = fa[x];
if (~iden(y)) rotate(iden(y) ^ iden(x) ? x : y);
rotate(x);
}
}
// access按照维护虚子树信息的方法写
inline void access(int x) {
for (int y = 0; x; x = fa[y = x]) {
splay(x);
// 原来的右孩子由实变虚,要将它的贡献计入g
if (ch[x][1]) {
val[x].data[0][0] += std::max(prd[ch[x][1]].data[0][0], prd[ch[x][1]].data[1][0]);
val[x].data[1][0] += prd[ch[x][1]].data[0][0];
}
// y变成了实儿子,要将它的贡献从g中减去。
if (y) {
val[x].data[0][0] -= std::max(prd[y].data[0][0], prd[y].data[1][0]);
val[x].data[1][0] -= prd[y].data[0][0];
}
val[x].data[0][1] = val[x].data[0][0];
ch[x][1] = y;
update(x);
}
}
inline void modify(int x, int y) {
access(x); splay(x);
val[x].data[1][0] -= a[x] - y;
update(x);
a[x] = y;
}
int main() {
read(n, m);
for (int i = 1; i <= n; ++i) read(a[i]);
for (int i = 1, x, y; i != n; ++i)
read(x, y), ae(x, y);
dfs(1);
while (m--) {
int x, y; read(x, y);
modify(x, y);
splay(1);
writeln(std::max(prd[1].data[0][0], prd[1].data[1][0]));
}
return 0;
}
```
然后讲一讲这道题的毒瘤加强版。[传送门](https://www.luogu.org/problemnew/show/P4751)
数据加强并且经过特殊构造,树剖和LCT都过不了了。树剖本身复杂度太大,$O(m\log^2n)$过不了百万是很正常的;而LCT虽然只有一个$\log$,但由于常数过大也被卡了。
树剖的两个$\log$基本上可以放弃治疗了。但是我们不禁要问,LCT究竟慢在哪里?
仔细想想,LCT的access复杂度之所以是一个$\log$,是由于splay的势能分析在整棵LCT上依然成立,也就是说可以把LCT看作一棵大splay,在这棵大splay上的一次access只相当于一次splay。
话虽然是这么说,但是实际上当我们不停地随机access的时候,要调整的轻重链数量还是很多的。感受一下,拿极端情形来说,如果树是一条链,一开始全是轻边,那么对链末端的结点access**一次**显然应该是$O(n)$的。所以其实LCT的常数大就大在它是靠势能法得到的$O(\log n)$,这么不靠谱的玩意是容易gg的。
但是如果我们不让LCT放任自由地access,而是一开始就给它构造一个比较优雅的姿态并让它静止(本来这棵树也不需要动),那么它也许就有救了。我们可以按照树链剖分的套路先划分出轻重边,然后对于重链建立一棵*形态比较好*的splay,至于轻儿子就跟原来的LCT一样直接用轻边挂上即可。什么叫“形态比较好”呢?我们给每个点$x$定义其权重为$size(x)-size(son(x))$,其中$son(x)$是它的重儿子,那么对于一条重链,我们可以先找到它的带权重心作为当前节点,然后对左右分别递归建树。代码长这样:
(这里的代码参考了@Great_Influence 大佬的题解)
```cpp
int stk[maxn], tp; // 一个栈
// 对一条重链建树,结点为stk[l]到stk[r]
int build_chain(int l, int r) {
if (l > r) return 0;
// 先计算出总权重是多少
int sum = 0;
for (int i = l; i <= r; ++i)
sum += size[stk[i]] - size[son[stk[i]]];
for (int i = l, cur = 0; i <= r; ++i) {
cur += size[stk[i]] - size[son[stk[i]]];
// cur*2 >= sum时就说明当前节点stk[i]是这条链的带权重心
if ((cur << 1) >= sum) {
int x = stk[i];
// 对左右孩子递归建树
ch[x][0] = build_chain(l, i - 1);
ch[x][1] = build_chain(i + 1, r);
fa[ch[x][0]] = fa[ch[x][1]] = x;
update(x);
return x;
}
}
return 0; // never reach
}
// build_whole对于以top为根的子树建树,top必须是某条重链的顶端。
int build_whole(int top, int dad) {
// 先对这条重链的每个结点处理轻儿子,直接把轻儿子用轻边连上即可。
for (int t = top; t; dad = t, t = son[t]) {
for (int i = head[t]; i; i = next[i])
if (v[i] != son[t] && v[i] != dad) {
int light_son = build_whole(v[i], t);
fa[light_son] = t;
}
val[t] = Matrix(g[t][0], g[t][1]);
}
// 然后对重链建树
tp = 0;
for (int x = top; x; x = son[x]) stk[++tp] = x;
return build_chain(1, tp);
}
```
基本上就是这样了。然后这棵树是静止的,并不需要splay,查询的时候既类似树剖那样一条链一条链一边改一边查询往上跳,又有点类似LCT的access。这种数据结构称为**全局平衡二叉树**。
分析一下复杂度:由于每个点的父亲的子树大小至少是它自己的子树大小的两倍,所以树高是$O(\log n)$的。完整代码:~~不用fread根本卡不过去,卡常难度直逼[旧试题](https://www.luogu.org/problemnew/show/P4619)~~
```cpp
#include <cctype>
#include <cstdio>
#include <climits>
#include <algorithm>
namespace superRead
{
#define BUF_SIZE 5000010
char buf[BUF_SIZE]; int cur = BUF_SIZE; FILE *in = stdin;
inline char gnc() {
if (cur == BUF_SIZE) { fread(buf, BUF_SIZE, 1, in); cur = 0; }
return buf[cur++];
}
template <typename T> inline void read(T &x) {
int f = 0; char c = gnc(); x = 0;
while (!isdigit(c)) f |= c == '-', c = gnc();
while (isdigit(c)) x = x * 10 + c - 48, c = gnc();
if (f) x = -x;
}
template <typename T, typename... Args>
inline void read(T& t, Args&... args) {
read(t); read(args...);
}
#undef BUF_SIZE
}
using superRead::read;
template <typename T> void write(T x) {
if (x < 0) x = -x, putchar('-');
if (x > 9) write(x / 10);
putchar(x % 10 + 48);
}
template <typename T> void writeln(T x) { write(x); puts(""); }
template <typename T> inline bool chkmin(T& x, const T& y) { return y < x ? (x = y, true) : false; }
template <typename T> inline bool chkmax(T& x, const T& y) { return x < y ? (x = y, true) : false; }
const int maxn = 1e6 + 207;
const int inf = 1e9;
struct Matrix {
int data[2][2];
Matrix() {
data[0][0] = data[0][1] = data[1][0] = data[1][1] = -inf;
}
Matrix(int gx0, int gx1) {
data[0][0] = data[0][1] = gx0;
data[1][0] = gx1; data[1][1] = -inf;
}
int getAns() {
return std::max(std::max(data[0][0], data[0][1]),
std::max(data[1][0], data[1][1]));
}
};
// 卡常写法
inline Matrix operator*(const Matrix &A, const Matrix &B) {
Matrix C;
C.data[0][0] = std::max(A.data[0][0] + B.data[0][0], A.data[0][1] + B.data[1][0]);
C.data[0][1] = std::max(A.data[0][0] + B.data[0][1], A.data[0][1] + B.data[1][1]);
C.data[1][0] = std::max(A.data[1][0] + B.data[0][0], A.data[1][1] + B.data[1][0]);
C.data[1][1] = std::max(A.data[1][0] + B.data[0][1], A.data[1][1] + B.data[1][1]);
return C;
}
int v[maxn << 1], head[maxn], next[maxn << 1], tot;
int son[maxn], size[maxn], g[maxn][2], a[maxn];
int n, m;
inline void addedge(int x, int y) {
v[++tot] = y; next[tot] = head[x]; head[x] = tot;
v[++tot] = x; next[tot] = head[y]; head[y] = tot;
}
void dfs1(int x, int fa) {
size[x] = 1; g[x][1] = a[x];
for (int i = head[x]; i; i = next[i])
if (v[i] != fa) {
dfs1(v[i], x);
size[x] += size[v[i]];
if (size[v[i]] > size[son[x]]) son[x] = v[i];
g[x][1] += g[v[i]][0];
g[x][0] += std::max(g[v[i]][0], g[v[i]][1]);
}
}
// 区别于LCT,这里一开始就要把轻重边划分好,相应的g值也就要改动。
void dfs2(int x, int fa) {
if (!son[x]) return;
g[x][0] -= std::max(g[son[x]][0],g[son[x]][1]);
g[x][1] -= g[son[x]][0];
for (int i = head[x]; i; i = next[i])
if (v[i] != fa) dfs2(v[i], x);
}
struct Global_bst {
Matrix val[maxn], prod[maxn];
int fa[maxn], ch[maxn][2];
bool isroot[maxn];
int root;
void update(int x) {
prod[x] = val[x];
if (ch[x][0]) prod[x] = prod[ch[x][0]] * prod[x];
if (ch[x][1]) prod[x] = prod[x] * prod[ch[x][1]];
}
int stk[maxn], tp;
int build_chain(int l, int r) {
if (l > r) return 0;
int sum = 0;
for (int i = l; i <= r; ++i)
sum += size[stk[i]] - size[son[stk[i]]];
for (int i = l, cur = 0; i <= r; ++i) {
cur += size[stk[i]] - size[son[stk[i]]];
if ((cur << 1) >= sum) {
int x = stk[i];
ch[x][0] = build_chain(l, i - 1);
ch[x][1] = build_chain(i + 1, r);
fa[ch[x][0]] = fa[ch[x][1]] = x;
update(x);
return x;
}
}
return 0; // never reach
}
int build_whole(int top, int dad) {
for (int t = top; t; dad = t, t = son[t]) {
for (int i = head[t]; i; i = next[i])
if (v[i] != son[t] && v[i] != dad) {
int light_son = build_whole(v[i], t);
fa[light_son] = t;
}
val[t] = Matrix(g[t][0], g[t][1]);
}
tp = 0;
for (int x = top; x; x = son[x]) stk[++tp] = x;
return build_chain(1, tp);
}
void build(int n) {
root = build_whole(1, 0);
for (int i = 1; i <= n; ++i)
if (!(ch[fa[i]][0] == i || ch[fa[i]][1] == i))
isroot[i] = 1;
else isroot[i] = 0;
}
int modify_query(int x, int y) {
g[x][1] += y - a[x];
a[x] = y;
int oldval[2], newval[2];
while (x) {
oldval[0] = std::max(prod[x].data[0][0], prod[x].data[0][1]);
oldval[1] = std::max(prod[x].data[1][0], prod[x].data[1][1]);
val[x] = Matrix(g[x][0], g[x][1]);
update(x);
newval[0] = std::max(prod[x].data[0][0], prod[x].data[0][1]);
newval[1] = std::max(prod[x].data[1][0], prod[x].data[1][1]);
if (isroot[x]) {
g[fa[x]][0] = g[fa[x]][0] - std::max(oldval[0], oldval[1]) + std::max(newval[0], newval[1]);
g[fa[x]][1] = g[fa[x]][1] - oldval[0] + newval[0];
}
x = fa[x];
}
return prod[root].getAns();
}
};
Global_bst bst;
int main() {
read(n, m);
for (int i = 1; i <= n; ++i) read(a[i]);
for (int i = 1, x, y; i != n; ++i) read(x, y), addedge(x, y);
dfs1(1, 0);
dfs2(1, 0);
bst.build(n);
int lastans = 0;
while (m--) {
int x, y; read(x, y);
x ^= lastans;
writeln(lastans = bst.modify_query(x, y));
}
return 0;
}
```
好了,动态DP是不是很简单呢QAQ
### NOIP2018 保卫王国
给一棵树,每次~~钦定~~强制指定两个点选或不选,求最小点权覆盖集的权值。[传送门](https://www.luogu.org/problemnew/show/P5024)
首先可以想到:强制选一个点就是把它的点权改成0,强制不选就是改成$\infty$。然后有两条路可走:你可以利用相关定理知道最小覆盖$=$总权值$-$最大独立,于是就直接把上面那题的代码粘过来改改就好了;或者你重新写一个dp:
$$f(x,0)=\sum_v f(v,1)$$
$$f(x,1)=\sum_v\min\{f(v,0),f(v,1)\}+a_x$$
然后还是把上面那题的代码改改就好了,方程都差不多的。
代码就不贴了~~毕竟跟上面的代码高度相似~~
我想讲一讲非DDP的做法,也不需要用到树剖/LCT/全局平衡二叉树这些超出NOIP范围的东西。
在原先的$f(x,0/1)$的基础上,可以设$g(x,0/1)$表示:对于整棵树减去以$x$为根的子树剩下的部分,当$x$不选/选的时候,这一部分的dp值。注意,这一部分并不包括$x$结点,但是这个值的确与$x$选/不选有关。那么转移:
$$g(v,0)=g(x,1)+f(x,1)-\min\{f(v,0),f(v,1)\}$$
$$g(v,1)=\min\{g(v,0),g(x,0)+f(x,0)-f(v,1)\}$$
($v$是$x$的孩子)
其实做到这里应该有一个感觉:由于$f(x,0/1)$的转移是一个累加的式子,所以我们可以很方便地减去某棵子树的贡献来得到其他部分的贡献。
考虑倍增:先有$fa(x,i)$表示$x$的$2^i$级祖先,显然转移$fa(x,i)=fa(fa(x,i-1),i-1)$。然后设$h(x,i,0/1,0/1)$表示以$fa(x,i)$为根的子树去掉以$x$为根的子树,剩下的部分的dp值,并且必须满足$x$不选/选,$fa(x,i)$不选/选。注意,这个状态所包含的结点同样不包括$x$本身,但其值与$x$选/不选有关。
初始条件是
$$h(v,0,0,0)=+\infty$$
$$h(v,0,0,1)=f(x,1)-\min\{f(v,0),f(v,1)\}$$
$$h(v,0,1,0)=f(x,0)-f(v,1)$$
$$h(v,0,1,1)=f(x,1)-\min\{f(v,0),f(v,1)\}$$
然后转移就枚举$2^{i-1}$级祖先的状态
$$h(x,i,j,k)=\min_{t=0,1}\{h(x,i-1,j,t)+h(fa(x,i-1),i-1,t,k)\}$$
其实并不是很难的东西。
对于一个询问$(x,qx,y,qy)$,令$x$是深度较大的点,分两种情况处理:$y$是$x$的祖先,或者$y$不是$x$的祖先。$y$是$x$的祖先时,从$x$一路倍增跳到$y$即可;$y$不是$x$的祖先时,先把$x$跳到与$y$同深度,然后再一起跳到$lca$。跳的过程中(以跳$x$为例)要保存$tx_{0/1}$表示目前$x$所在的这个结点不选/选的时候的答案。具体的细节很多,难以用语言说清楚,而且难度不大,就看代码吧。(建议自行完成代码)
```cpp
#include <cctype>
#include <cstdio>
#include <climits>
#include <algorithm>
template <typename T> inline void read(T& t) {
int f = 0, c = getchar(); t = 0;
while (!isdigit(c)) f |= c == '-', c = getchar();
while (isdigit(c)) t = t * 10 + c - 48, c = getchar();
if (f) t = -t;
}
template <typename T, typename... Args>
inline void read(T& t, Args&... args) {
read(t); read(args...);
}
template <typename T> void write(T x) {
if (x < 0) putchar('-'), x = -x;
if (x > 9) write(x / 10);
putchar(x % 10 + 48);
}
template <typename T> inline void writeln(T x) {
write(x); puts("");
}
template <typename T> inline bool chkmin(T& x, const T& y) { return y < x ? (x = y, 1) : 0; }
template <typename T> inline bool chkmax(T& x, const T& y) { return x < y ? (x = y, 1) : 0; }
typedef long long LL;
const int maxn = 1e5 + 207;
const LL inf = 1e10;
int v[maxn << 1], head[maxn], next[maxn << 1], tot;
LL f[maxn][2], g[maxn][2], h[maxn][30][2][2], val[maxn];
int fa[maxn][30], dep[maxn];
int n, m;
inline void ae(int x, int y) {
v[++tot] = y; next[tot] = head[x]; head[x] = tot;
v[++tot] = x; next[tot] = head[y]; head[y] = tot;
}
void dfs1(int x) {
using std::min;
f[x][1] = val[x]; dep[x] = dep[fa[x][0]] + 1;
for (int i = 1; i <= 20; ++i) fa[x][i] = fa[fa[x][i - 1]][i - 1];
for (int i = head[x]; i; i = next[i])
if (v[i] != fa[x][0]) {
fa[v[i]][0] = x;
dfs1(v[i]);
f[x][0] += f[v[i]][1];
f[x][1] += min(f[v[i]][0], f[v[i]][1]);
}
}
void dfs2(int x) {
using std::min;
for (int i = 1; i <= 20; ++i)
for (int j = 0; j <= 1; ++j)
for (int k = 0; k <= 1; ++k)
h[x][i][j][k] = min(h[x][i - 1][j][0] + h[fa[x][i - 1]][i - 1][0][k],
h[x][i - 1][j][1] + h[fa[x][i - 1]][i - 1][1][k]);
for (int i = head[x]; i; i = next[i])
if (v[i] != fa[x][0]) {
h[v[i]][0][0][0] = inf;
h[v[i]][0][0][1] = f[x][1] - min(f[v[i]][0], f[v[i]][1]);
h[v[i]][0][1][0] = f[x][0] - f[v[i]][1];
h[v[i]][0][1][1] = f[x][1] - min(f[v[i]][0], f[v[i]][1]);
g[v[i]][0] = g[x][1] + f[x][1] - min(f[v[i]][0], f[v[i]][1]);
g[v[i]][1] = min(g[v[i]][0], g[x][0] + f[x][0] - f[v[i]][1]);
dfs2(v[i]);
}
}
inline bool isAncestor(int x, int y) {
for (int i = 20; ~i; --i) if (dep[fa[y][i]] >= dep[x]) y = fa[y][i];
return x == y;
}
inline LL getAns(int x, int qx, int y, int qy) {
using std::min;
using std::swap;
if (dep[x] < dep[y]) { swap(x, y); swap(qx, qy); }
if (isAncestor(y, x)) {
LL tmp[2] = {f[x][0], f[x][1]}; tmp[qx ^ 1] = inf;
for (int i = 20; ~i; --i) if (dep[fa[x][i]] > dep[y]) {
LL t0 = min(tmp[0] + h[x][i][0][0], tmp[1] + h[x][i][1][0]);
LL t1 = min(tmp[0] + h[x][i][0][1], tmp[1] + h[x][i][1][1]);
tmp[0] = t0; tmp[1] = t1; x = fa[x][i];
}
LL ans = min(tmp[0] + h[x][0][0][qy], tmp[1] + h[x][0][1][qy]) + g[y][qy];
return ans < inf ? ans : -1;
} else {
LL tx[2] = {f[x][0], f[x][1]}; tx[qx ^ 1] = inf;
LL ty[2] = {f[y][0], f[y][1]}; ty[qy ^ 1] = inf;
for (int i = 20; ~i; --i) if (dep[fa[x][i]] >= dep[y]) {
LL t0 = min(tx[0] + h[x][i][0][0], tx[1] + h[x][i][1][0]);
LL t1 = min(tx[0] + h[x][i][0][1], tx[1] + h[x][i][1][1]);
tx[0] = t0; tx[1] = t1; x = fa[x][i];
}
for (int i = 20; ~i; --i) if (fa[x][i] != fa[y][i]) {
LL t0 = min(tx[0] + h[x][i][0][0], tx[1] + h[x][i][1][0]);
LL t1 = min(tx[0] + h[x][i][0][1], tx[1] + h[x][i][1][1]);
tx[0] = t0; tx[1] = t1; x = fa[x][i];
t0 = min(ty[0] + h[y][i][0][0], ty[1] + h[y][i][1][0]);
t1 = min(ty[0] + h[y][i][0][1], ty[1] + h[y][i][1][1]);
ty[0] = t0; ty[1] = t1; y = fa[y][i];
}
LL ans = min(f[fa[x][0]][0] - f[y][1] - f[x][1] + tx[1] + ty[1] + g[fa[x][0]][0],
f[fa[x][0]][1] - min(f[x][0], f[x][1]) - min(f[y][0], f[y][1])
+ min(tx[0], tx[1]) + min(ty[0], ty[1]) + g[fa[x][0]][1]);
return ans < inf ? ans : -1;
}
}
int main() {
read(n, m);
{ char foo[10]; scanf("%s", foo); }
for (int i = 1; i <= n; ++i) read(val[i]);
for (int i = 1; i != n; ++i) {
int x, y; read(x, y);
ae(x, y);
}
dfs1(1);
dfs2(1);
while (m--) {
int x, qx, y, qy;
read(x, qx, y, qy);
writeln(getAns(x, qx, y, qy));
}
return 0;
}
```
### 胡思乱想
既然有了动态DP,如果用可持久化数据结构来维护的话是不是就可以...
~~可持久化DP???~~