【毒瘤Warning】Chtholly Tree珂朵莉树详解
SuperJvRuo
·
·
个人记录
本文被yfz批判,正在修改
一、什么是珂朵莉树
珂朵莉树,又称Old Driver Tree(ODT)。是一种某毒瘤发明的、常基于std::set实现的算法。
二、什么时候用珂朵莉树
关键操作:推平一段区间,使一整段区间内的东西变得一样,另有一些奇奇怪怪的查询。要求复杂度m\log n,保证数据随机。
ODT起源:CF896C Willem, Chtholly and Seniorious
操作:
1. 区间加
2. **区间赋值**
3. 区间第k小
4. 求区间幂次和
**数据随机**,时限2s。
当然了,遇到一道区间推平、线段树可做、**数据不保证随机**的题时,你如果觉得线段树代码量巨大,害怕写挂,也可以选择ODT来**骗分**。之所以说是骗分,是因为如果使用std::set维护ODT,在非随机数据下,其复杂度可能是不对的。只有使用线段树辅助维护,才可以获得正确的复杂度。在出题人没有认真造数据的情况下有奇效。本文最后给出的几道练习题表明,目前几乎没有出题人有意卡掉珂朵莉树。
## 三、珂朵莉树的初始化
一般来说,珂朵莉树可以用线段树或平衡树维护。我们用```std::set```维护每个包含的数相同的区间。这道题里,这样定义珂朵莉树的节点:
```
struct node
{
int l,r;
mutable LL v;
node(int L, int R=-1, LL V=0):l(L), r(R), v(V) {}
bool operator<(const node& o) const
{
return l < o.l;
}
};
```
这样的一个节点表示$[l,r]$内的所有数都是$v$,ODT的本质就是把区间缩成点,```std::set```维护的ODT,可以视为一棵缩点后的平衡树。需要注意的是```mutable```,意为易变的,不定的。它对```v```的修饰,使得我们可以在```add```操作中修改```v```的值。没有它的修饰会在```add```函数里导致CE。
我们把节点存在```set```里。
```
set<node> s;
```
像CF896C这道题就这样初始化。
```
cin>>n>>m>>seed>>vmax;
for (int i=1; i<=n; ++i)
{
a[i] = (rnd() % vmax) + 1;
s.insert(node(i,i,a[i]));
}
```
初始化完了?初始化完了。
## 四、核心操作1:split
```split(pos)```操作是指将原来含有pos位置的节点分成两部分:$[l,pos-1]$和$[pos,r]$。
看这个操作的代码:
```
#define IT set<node>::iterator
IT split(int pos)
{
IT it = s.lower_bound(node(pos));
if (it != s.end() && it->l == pos) return it;
--it;
int L = it->l, R = it->r;
LL V = it->v;
s.erase(it);
s.insert(node(L, pos-1, V));
return s.insert(node(pos, R, V)).first;
}
```
这都什么啊?看不懂啊。我们一行一行来看。
```
#define IT set<node>::iterator
```
宏定义没什么好说的。
```
IT it = s.lower_bound(node(pos));
```
找到首个$l$不小于pos的节点。
```
if (it != s.end() && it->l == pos)
return it;
```
如果pos是某个节点的左端点,直接返回该节点。
```
--it;
```
否则pos一定在前一个区间中。
```
int L = it->l, R = it->r;
```
$[L,R]$就是要被分割的区间。
```
LL V = it->v;
```
取出这个节点的值。
```
s.erase(it);
```
删除原节点。
```
s.insert(node(L, pos-1, V));
```
插入前半段。
```
return s.insert(node(pos, R, V)).first;
```
插入后半段,返回后半段的迭代器。这里利用了```pair<iterator,bool> insert (const value_type& val)```的返回值。
## 五、核心操作2:assign
要是只有```split```还不得复杂度爆炸?我们需要```assign```操作迅速减小```set```的规模。
```
void assign(int l, int r, LL val=0)
{
IT itr = split(r+1),itl = split(l);
s.erase(itl, itr);
s.insert(node(l, r, val));
}
```
把$l$和$r+1$进行split,再把$[l,r]$合成一个节点。为什么要先split出r+1呢?因为如果先split出l,再split出r+1,之前的itl可能就不是l对应的迭代器了。```void erase (iterator first, iterator last)```可删除$[first,last)$区间。这里就是把$[l,r+1)$内的部分推成一段。
珂朵莉树的复杂度是由```ass```♂```ign```保证的。由于例题数据随机,有$\frac{1}{4}$的操作为```assign```。我们还可以证明,每次```assign```的区间的期望大小为$\frac{n}{3}$。(初赛竟然考了诶)

```set```的大小快速下降,使得珂朵莉树在随机数据下的时间复杂度为期望$m\log n$。复杂度证明:http://codeforces.com/blog/entry/56135?#comment-398940
**注意:珂朵莉树的时间复杂度在非随机数据下是错误的,只能用于骗分,不是正解。**
## 六、其他操作:set里走路
区间加:
```
void add(int l, int r, LL val=1)
{
IT itr = split(r+1),itl = split(l);
for (; itl != itr; ++itl) itl->v += val;
}
```
```split```出来挨个加一下就行。
区间第k小:
```
LL rank(int l, int r, int k)
{
vector<pair<LL, int> > vp;
IT itr = split(r+1),itl = split(l);
vp.clear();
for (; itl != itr; ++itl)
vp.push_back(pair<LL,int>(itl->v, itl->r - itl->l + 1));
sort(vp.begin(), vp.end());
for (vector<pair<LL,int> >::iterator it=vp.begin();it!=vp.end();++it)
{
k -= it->second;
if (k <= 0) return it->first;
}
return -1LL;
}
```
暴力取出排序就好了,反正也没有多少段。
```
LL sum(int l, int r, int ex, int mod)
{
IT itr = split(r+1),itl = split(l);
LL res = 0;
for (; itl != itr; ++itl)
res = (res + (LL)(itl->r - itl->l + 1) * pow(itl->v, LL(ex), LL(mod))) % mod;
return res;
}
```
暴力遍历,快速幂,然后加起来。
那么,这道题就可做了,快写一发试试吧!
## 七、ODT如何应付非随机数据
例题:[USACO08FEB 酒店Hotel](https://www.luogu.org/problemnew/show/P2894)
区间赋值,区间填补,这不是傻逼ODT题吗,赶快写一发!
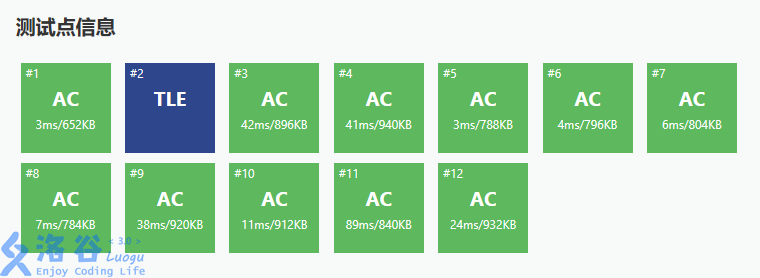
布星啊,这第二组数据的区间填补长度都不超过10,ODT内这么多区间,复杂度退化了啊!
其实还是有办法的。复杂度之所以不对,是因为在```set```中的暴力```for```。如果改成用线段树维护ODT,批量对区间操作,复杂度就正确了。而且我们可以想象到,它的速度会大大快于标算。
```
```
看到这里,也许读者会有疑虑:我为什么不直接写个线段树呢?
这道题并没有完全体现ODT的代码优越性。我选出这道题只是单纯地因为它的官方数据可以卡掉```set```。对于不少题目,用线段树就需要维护繁多的标记,处理复杂的下放与上传。而ODT完全不需要这些。
## 八、更广泛的应用:骗分的有力武器
~~由于CF896C这种毒瘤题目只会在ynoi级别的题目中出现,~~珂朵莉树更多地被用于骗分。

UESTC的B站讲解(不用找了,这段视频已被lxl,yfz,mcfx,zcy所批判)里还有另两道题,一道是[CF915E](https://www.luogu.org/problemnew/show/CF915E),另一道是[BZOJ4293割草](http://ruanx.pw/bzojch/p/4293.html)(权限题)。**值得注意的是,在这两道题中使用ODT,由于数据不随机,视频中代码的复杂度是错误的。**这两道题的主流做法都是线段树,珂朵莉树也可达到骗分的目的。但珂朵莉树仍能体现出代码复杂度较小、易查错、高效骗分的优势。CF915E的评测记录: https://www.luogu.org/record/show?rid=11431273 。
数据结构需要摸索,需要练习。否则就算是在考场上看到了珂朵莉树可骗分的题,也会被水淹没,也会不知所措。洛谷题库里还有不少珂朵莉树骗分的练手题,都有珂朵莉树的骗分题解:
- [P2572 SCOI2010序列操作](https://www.luogu.org/problemnew/show/P2572),不难想到线段树做法,但是用线段树写起来码量不小,标记也容易弄错顺序,珂朵莉树就方便多了。评测记录: https://www.luogu.org/record/show?rid=11438976 。开了O2跑得还挺快。
- [P2082 区间覆盖(加强版) ](https://www.luogu.org/problemnew/show/P2082),标算是贪心,但是也可以用动态开点线段树或珂朵莉树解决(此题中的复杂度是正确的)。评测记录: https://www.luogu.org/record/show?rid=11388888 。(这个rid不错诶)
- [P2787 语文1(chin1)- 理理思维](https://www.luogu.org/problemnew/show/P2787),区间推平,区间排序,珂朵莉树骗分。评测记录: https://www.luogu.org/record/show?rid=11489133 。区间排序可以开桶完成:
```
void sort_range(int l,int r)
{
int cnt[27];
memset(cnt,0,sizeof(cnt));
IT itr=split(r+1),itl=split(l);
for(IT itl2=itl;itl2!=itr;++itl2)
{
cnt[itl2->v-'A']+=itl2->r-itl2->l+1;
}
s.erase(itl,itr);
int pos=l;
for(int i=0;i<26;++i)
{
if(cnt[i])
{
s.insert(node(pos,pos+cnt[i]-1,i+'A'));
pos+=cnt[i];
}
}
}
```
- [SHOI2015 脑洞治疗仪](https://www.luogu.org/problemnew/show/P4344),都是珂朵莉树骗分基操。脑洞治疗操作就是一个```count```一个```assign```加一波乱搞。评测记录: https://www.luogu.org/record/show?rid=11492835 。
```
int count_erase(int l,int r)
{
int res=0;
IT itr=split(r+1),itl=split(l);
for(IT itl2=itl;itl2!=itr;++itl2)
{
if(itl2->v==true)
{
res+=itl2->r-itl2->l+1;
}
}
s.erase(itl,itr);
s.insert(node(l,r,false));
return res;
}
void fix(int l,int r,int cnt)
{
IT itr=split(r+1),itl=split(l);
for(;itl!=itr;++itl)
{
if(itl->v==false)
{
if(itl->r-itl->l+1>=cnt)
{
if(itl->r-itl->l+1>cnt)
{
int lrange=itl->l,rrange=itl->r;
s.erase(itl);
s.insert(node(lrange,lrange+cnt-1,true));
s.insert(node(lrange+cnt,rrange,false));
}
else
{
itl->v=true;
}
return;
}
else
{
itl->v=true;
cnt-=itl->r-itl->l+1;
}
}
}
}
void recover(int l1,int r1,int l2,int r2)
{
int cnt=count_erase(l1,r1);
if(!cnt)
return;
fix(l2,r2,cnt);
}
```
- [SDOI2011 染色](https://www.luogu.org/problemnew/show/P2486),树链剖分+珂朵莉树。会用线段树做这题,那你用珂朵莉树也能骗分AC。(但是这题的代码量似乎没太大优势)评测记录: https://www.luogu.org/record/show?rid=11868327 。我的查询是这样写的:
```
typedef node Ret;
//直接把node的定义拿来用,l表示左端颜色,r表示右端颜色,v表示颜色段数
Ret operator + (Ret l,Ret r)
{
return Ret(l.l?l.l:r.l,r.r?r.r:l.r,l.v+r.v-(l.r==r.l));
}
//重载运算符便于合并
Ret query(int l,int r)
{
Ret ans=Ret(0);
IT itr=split(r+1),itl=split(l);
for(;itl!=itr;++itl)
{
ans=ans+Ret(itl->v,itl->v,1);
}
return ans;
}
int qRange(int x,int y)
{
Ret lans=Ret(0),rans=Ret(0);
//lans表示x一侧的答案,rans表示y一侧的答案。
while(top[x]!=top[y])
{
if(dep[top[x]]>dep[top[y]])
{
lans=query(id[top[x]],id[x])+lans;
x=fa[top[x]];
}
else
{
rans=query(id[top[y]],id[y])+rans;
y=fa[top[y]];
}
}
if(dep[x]>dep[y])
{
lans=query(id[y],id[x])+lans;
}
else
{
rans=query(id[x],id[y])+rans;
}
std::swap(lans.l,lans.r);
//lans倒过来再加上rans
return (lans+rans).v;
}
```
- [NOI2007 项链工厂](https://www.luogu.org/problemnew/show/P4130)
与染色一题大体相同,记录一下rotate和flip的情况,像染色一样去搞即可。
```
```
**注意:以上题目中珂朵莉树都只是骗分手段,尽管可以依靠以上代码获得AC,但由于数据不是完全随机的,其复杂度都是错误的。**
笔者在暑期的一场测试中使用过一次ODT,特判了出锅的数据后(这个锅不会影响到正常写法的线段树和分块,但会导致用```std::set```实现的珂朵莉树RE成60pts),成功骗得了88分,在时限开到2秒后可以获得96分,第22号测试点足足用了15秒,想必是出题人有意构造,卡掉骗分做法的。该题的大意是对一个初始为空集的数集做交、并、减、异或等操作。不难发现这些操作大部分可以用split和assign完成,小部分可以暴力解决。在该场比赛中,分块的分数多为76分,线段树的分数为96~100分。而ODT的代码量远小于分块和线段树(线段树标记越多越明显),为我解决同一场考试中的其他题目争取了时间。
## 九、结语(雾)
lxl是启明星,lxl是航标灯。如今,毒瘤数据结构已在lxl的领导下进入了深水区,表面海阔天空,却也暗潮涌动;看似河清海晏,实则泥沙俱下。一方面,信息学竞赛中的毒瘤日新月异;另一方面,骗分手段也是道高一尺,魔高一丈。9年前,李博杰的《骗分导论》横空出世,为OI界的骗分指明了方向。9年过去了,如今的骗分,已远非是当年一本区区200余页的骗分导论说得清,道得明的。珂朵莉树就是毒瘤正解在骗分之林中初绽的一朵奇葩,助我们在时间复杂度和代码复杂度间找到最好的平衡。珂朵莉树是潜移默化的,珂朵莉树是润物无声的。有暴力骗分武装头脑,珂朵莉树指导实践,就没有翻不过的山、迈不过的坎,就可以获得更加可观的暴力分。如果出版新的骗分导论,珂朵莉树必然是其中最值得学习的骗分技巧之一。这是广大OIer坚定的信念、共同的心声。
~~——洛谷人民日报(大雾)~~