AlphaGo是如何打败棋手们的
呵呵侠
·
·
个人记录
要说\text{2016}年的几个大新闻,其中必然有一个就是\text{AlphaGo}击败围棋职业九段选手李世石。
$\text{2016}$年$\text{3}$月,$\text{AlphaGo}$与职业九段棋手李世石进行围棋人机大战,以$\text{4:1}$的总比分获胜。
$\text{2016}$年末$\text{2017}$年初,$\text{AlphaGo}$在中国棋类网站上以$\text{Master}$为注册帐号与中日韩数十位围棋高手进行快棋对决,连续$\text{60}$局无一败绩。
$\text{2017}$年$\text{5}$月,在中国乌镇围棋峰会上,$\text{AlphaGo}$与排名世界第一的世界围棋冠军柯洁对战,以$\text{3:0}$的总比分获胜。围棋界公认$\text{AlphaGo}$的棋力已经超过人类职业围棋顶尖水平。
不得不说,$\text{AlphaGo}$是真正的强大。
但是,$\text{AlphaGo}$是如何打败众多职业选手的呢?
这个故事首先要从一个叫做“深蓝”的程序讲起。
深蓝是美国$\text{IBM}$公司生产的一台超级国际象棋电脑,重$\text{1270}$公斤,有$\text{32}$个微处理器,每秒钟可以计算$2 * 10^9$步。深蓝输入了一百多年来优秀棋手的对局两百多万局。
深蓝创造于$\text{1996}$年,更新于$\text{1997}$年,使用$\text{C}$语言编写(让我这个$\text{C}$党非常自豪)。
那么深蓝拿下了怎样的战绩呢?
$\text{1996}$年,深蓝与国际象棋特级大师$\text{ГарриКимовичКаспаров}$对战,结果是$\text{1:2}$被击败。
$\text{1997}$年,深蓝与国际象棋特级大师$\text{ГарриКимовичКаспаров}$对战,结果是$\text{2:1}$获胜。
$\text{1997}$年的比赛过后,深蓝宣布退役。
不知道大家怎么看待这个战绩,反正在计算机还尚未普及的$\text{1997}$年,一个程序居然能够打败国际象棋特级大师,那是十分了不起的。
不过深蓝毕竟是国际象棋的,和围棋有很大不同。
国际象棋其实下发并不多,再加上一些剪枝的函数,即便是暴力运算也不会有太大问题。
但围棋不同。稍微了解一点围棋的人都知道,围棋的棋盘是标准的$\text{19 * 19}$的棋盘,一共$\text{361}$个交叉点,一局棋有$\text{361!}$种下法的可能,这大致是$4 * 10^{768}$,如果光用暴力怕是要算到天荒地老,海枯石烂了。
所以$\text{AlphaGo}$并没有使用暴力硬算,而是运用了一个相当玄学的东西——神经网络。
------------
## 技术1:神经网络和深度学习
引用了[这篇博客](http://www.199it.com/archives/449359.html?utm_source=tuicool&utm_medium=referral)的一段话:
其实类神经网络是很古老的技术了,在$\text{1943}$年,$\text{Warren McCulloch}$以及$\text{Walter Pitts}$首次提出神经元的数学模型,之后到了$\text{1958}$年,心理学家$\text{Rosenblatt}$提出了感知器($\text{Perceptron}$)的概念,在前者神经元的结构中加入了训练修正参数的机制(也是我们俗称的学习),这时类神经网络的基本学理架构算是完成。类神经网络的神经元其实是从前端收集到各种讯号(类似神经的树突),然后将各个讯号根据权重加权后加总,然后透过活化函数转换成新讯号传送出去(类似神经元的轴突)。
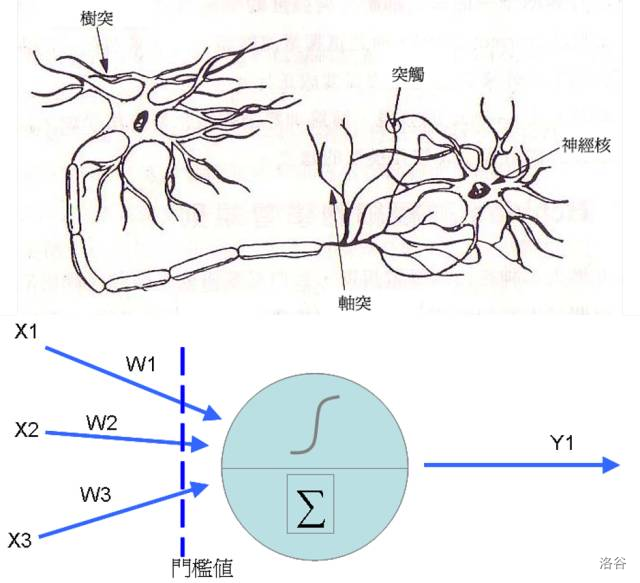
看懂了吗?
反正我是没看懂。
好吧,其实简单地说,就是先写几个随机数,用一种递归的方式逐渐更改随机数,让随机数的数值尽可能地准确。
不过尽管程序已经努力地让随机数变得准确,可惜准确度仍然不够,说句实话,如果$\text{AlphaGo}$用的是类神经网络,连我都不一定下得过(在下水平业余$\text{5}$段,不知道这是个什么水平的可以百度一下)。
然而,$\text{AlphaGo}$能打败李世石和柯洁,用类神经网络就有点力不从心了,于是就有了一个高级版——深度学习。
当时类精神网络已经进入了一个尘封期,直到$\text{2006}$年,这个被尘封的技术再次被人类捡起来使用。
那时一些人发现如果类神经网络不采用随机方式去派发数据就会让程序的精准度以及速度大大提升,这种好事谁不愿意干?
它们提出的方法是利用神经网络的非监督式学习来做为神经网络初始权重的指派,那时由于各家的论文期刊只要看到类神经网络字眼基本上就视为垃圾不刊登,所以他们才提出深度学习这个新的字眼突围。
所以才有了深度学习这一个名词。
------------
## 技术2:两个“大脑”配合工作
$\text{AlphaGo}$是通过两个不同神经网络“大脑”合作来改进下棋。这些“大脑”是多层神经网络,跟那些$\text{Google}$图片搜索引擎识别图片在结构上是相似的。
两个“大脑”分别是“落子选择器”和“棋局评估器”,分别有各自的用途,接下来我来给大家一一列说。
$\text{AlphaGo}$的第一个“大脑”是用来寻找下一步的。这可以理解为“落子选择器”。
$\text{AlphaGo}$的第二个“大脑”是用来判断当棋手把棋下在每一个地方时的胜率。这可以理解为“棋局评估器”。
正是由这两个“大脑”互相配合,才能够让这个程序能够击败李世石。
----------
## 不足之处:
虽然$\text{AlphaGo}$以$\text{4:1}$的战绩击败李世石,然而那时的$\text{AlphaGo}$还不是人类不可击败的,不然就不是$\text{4:1}$而是$\text{5:0}$了。
我来给大家分析一下为什么$\text{AlphaGo}$的第四局输掉了:
众所周知,第四局时$\text{AlphaGo}$其实已经有了一定的优势,然而为什么李世石能够赢棋呢?
这就必须要提到$\text{AlphaGo}$的运行机制以及李世石的“神之一手”。
$\text{神之一手:}
这手棋我在棋盘上摆了很久,也不明白是什么意思,白棋的这一步黑棋应该有好几个应对吧,为什么实战\text{AlphaGo}下得不怎么好呢?
后来我了解了\text{AlphaGo}的运行原理,我明白了,其实这就是\text{AlphaGo}的不足之处:
说白了,在$\text{AlphaGo}$的预测里李世石是基本不可能下在那个地方的,所以就根本没做准备,最后也就只能凉凉了。
这也是当时$\text{AlphaGo}$唯一的一个弱点,就是只要你能出乎意料(似乎我很擅长),就能出其不意。
然而后来的$\text{AlphaGo Master}$版本就已经改掉了这个问题,所以后来$\text{Master}$才能在围棋网上连胜$\text{60}$局。
接下来,我来给大家介绍一下新版的$\text{AlphaGo}$的运行机制:
------------
## 技术1:自我学习
新版的$\text{AlphaGo Zero}$使用新的强化方法,让自己成为了自己的老师,这靠的是不断地自己与自己对弈,从单一的神经网络开始,使得神经网络更加强大,能够提升预测能力,最终赢得比赛。
------------
## 技术2:一个“大脑”
新版的$\text{AlphaGo Zero}$将自己的两个“大脑”合二为一,变成了一个“大脑”,尽管“大脑”的个数变少了,然而功能却丝毫没有发生改变,并且速度更快了。
------------
## 技术3:高级神经网络
新版的$\text{AlphaGo Zero}$不再使用快速走子这种牺牲质量,换取速度的方法,而是采用了高质量的神经网络(在自我学习时建立起来的)来评估下棋的局势。
------------
正是有着这些技术,$\text{AlphaGo}$才能战胜众多职业选手,一跃成为围棋职业九段,但是就像那句话所说:
阿尔法狗不懂围棋的美学,他只是由两个函数支撑而已。
**The End**
------------
参考:
[百度百科:阿尔法围棋](https://baike.so.com/doc/23638581-24193228.html)
[浅谈AlphaGo背后所涉及的深度学习技术](http://www.199it.com/archives/449359.html?utm_source=tuicool&utm_medium=referral)