再学串串(一):我真的学会 KMP 了吗?评「clx201022 式的傲慢」
clx201022
·
·
算法·理论
为什么要写作本文?
以为自己已经学会了串串[^chuanchuan],结果在摩卡串被创飞才发现自己似乎连最基础的 KMP 都没有学懂,遂写此文。
因此本文不仅是一篇介绍字符串的博客,更是学习的过程。
子曰:「温故而知新,可以为师矣。」这种学习方法也叫费曼学习法。
所以读者在品鉴完本文后还可以去教别人,并告诉他这是一种高级学习方法。
本文面向的对象
已经学过字符串但还没有完全学懂的人。
如果您完全没有学过字符串相关建议先在 OI-wiki 上了解一个大概。
具体算法思想没看懂不要急,可以再回来看本文。
如果您是神犇(如队爷),也欢迎抱着一种居高临下的态度批判性地阅读此文。笔者学识浅薄,文化造诣[^yi]不高,如出现错误望神犇能不吝赐教,首当其冲[^chong]地指正。
本文会涉及的内容
一些有关算法的核心思想,而不仅仅是限于照本宣科。
因为本人资历比较浅,所以可能会出现一些错误,欢迎指正。
如果有想看的比较冷门的内容可以私信笔者,能学懂的话会加上去。
字符串的底层逻辑
字符集
在几年一知半解的学习中,笔者也积累了一点理解。而关于「底层逻辑」,第一个答案应该就是「字符集」了。
不同于一般的「值域」,字符串的字符集一般都比较小。
如经典的 AC 自动机,其能以相对较低的复杂度运行的核心就是字符集相较于其他数据而言是极小的。大部分情况下甚至会将字符集大小视为常数。
一般情况下,char 类型就足以应付竞赛中所有可能遇到的字符集。
字典序
如果要问除了字符集大小字符串第二核心的概念是什么,那应该就是字典序了。
其实字典序的应用不止于字符串,很多非串串题也会用到类似字典序的概念,如滚木比大小。
要注意其与一般数字比大小的区别与联系,不明白的可以去看 [NOIP 1998 提高组] 拼数下的有关争论,里面包含了一些关于偏序关系[^pian]的讨论。
比大小实现层面,两个字符串按位比即可。时间复杂度为 O(N),N 为串长(如果考虑录入字符串本身的开销就是较长串的,否则就是较短串的)。
拆分与拼接
字符串区别于其他数据结构最大的一点就是它的每一位可以说是近乎「独立」的。因此,你可以把一个字符串拆成两半,又或者是把两个字符串拼在一起。这两个操作可以说在绝大部分字符串题中都有出现。一般地,「前缀」是把前面一部分拆下来,「后缀」是将后面一部分拆下来。也可以以删去字符的角度考虑:此时「前缀」就是删掉后面一部分,「后缀」则是将前面一部分删掉。
C++ 的 string 类型提供了方便的 + 和 substr 供执行上述操作。需要注意的是,C++ char 类型内部的加法是基于 ASCII 码的整数加减,不是字符串拼接,正确的做法是先转化为 string 类型再进行相关操作。如果需要将 int 或者其他类型转化为 string,sstream 是一个不错的选择。
Hash(哈希)
单哈希容易被卡,双哈希可以大大降低被卡的几率(但还是有)。
其能以较快的速度判定字符串是否相等,但不方便进行字典序的比较。(要比较字典序的话需要一些奇技淫巧)
如果将所有字符串空间中的字符串全部做哈希,必定存在冲突。但大部分时候题目只需要使用整个字符串空间中的极小一部分。(字符串数量相比于对应长度的所有可能字符串数量极小)甚至有时候在题目的字符串长度限制内所有字符串都不能引发哈希冲突。这也是为什么哈希算法绝大部分情况下都是正确的。
实现方法上可以按位类似多项式乘一个系数,具体可见 OI-Wiki 或文后的友链。
这四大天王可谓是一对笑面虎,两头乌角鲨。学懂了它们,就学懂了整个字符串体系。
第一站:KMP(一)
要问最经典的字符串匹配算法是什么,那应该就是 KMP 了。
关于 KMP 算法为什么叫 KMP,可见:《FAST PATTERN MATCHING IN STRINGS*》, DONALD E. KNUTHf, JAMES H. MORRIS, JR.\:l: AND VAUGHAN R. PRATT。
之前有一部 KMP 学习笔记,但太过老旧了。
原始论文讲得已经很详细了,但是比较晦涩难懂。笔者将在此从另一角度进行思考。
KMP 本质上是一个字符串匹配算法,其要求是从文本串 T 中找出所有的模式串 S(设 S 长 m,T 长 n)。
先考虑朴素的匹配算法。对于 T 每一位置,将其作为起始位置,依次尝试匹配 S,失配则直接跳过。
容易注意到,真正耗费时间的不是匹配失败,而是匹配成功。假如每一次都匹配失败,算法时间复杂度无非是 O(n) 的,但如果每一次都匹配成功(如 S, T 均为同一字符 a 的重复),那么时间复杂度就会来到 O(nm)。
那么,如何减少匹配次数呢?
匹配成功虽然额外耗费了时间,但其肯定给出了一些「信息」。
类似于类子集和问题背包 DP 代替搜索,其本质上是将总空间相同的状态合并。但搜索就全然没有用吗?在一些值域极大但数目较少时,用搜索就可以在与值域无关的前提下求出答案,而这是一般的背包 DP 难以实现的。
上文可能涉及到了一些信息论的知识,但笔者是个蒟蒻,所以在此不深入探究。
思考匹配成功带来了什么「信息」。假设匹配成功的一段是 S[1, j], T[i, i + j - 1](以 1-index 为例,即 S[1, j] 为 S 的一个前缀),则意味着 S[1, j] 这一段前缀每一个字符都是和 T 的对应位置相等了。[^fang]
读者可以先自己思考一下如何用此思路优化算法再看下文。
以防你不小心瞄到下文:
构造
为了简单起见,先钦定 i,j 为只增的。
考虑失配或匹配成功的情况。此时 S_{j+1}\ne T_{i+j},匹配成功视为 j = m 时下一位失配即可(也可以理解为不存在合法的 S_{m+1} 用以匹配)。
(此时我们对 i+j 往后的 T 部分没有任何信息)
此时,寻找一个尽可能大的 i' 使得其在已有信息下 i<k<i' 不可能存在能使 T 匹配 S 成功的 k(保证正确性),下一次开始匹配时直接跳到 i' 即可。同时我们也希望找到一个 j' 使得下次也可以直接从此开始匹配。
对于 i'>i+j-1 的情况,由于我们对后面没有任何信息,所以只能从 j'=1 开始尝试匹配。但此时目的已经达到:i\sim i+j-1 这一段被跳过,即利用已有信息省下了计算 i\sim i+j-1 这一段的时间。
对于 i'\le i+j-1,存在合法的 T[i',i+j-1]。由于我们希望其是可能成功的,所以要求 T[i', i+j-1] = S[1, j+i-i']。又注意到根据已有条件,一定存在 T[i', i+j-1] = S[i'-i+1, j]。
(如图,i'-i+1<j+i-i' 时,推导仍然成立)
因为上文中未要求任何额外条件,所以,只要 i'\le i+j-1,就一定要求 i' 满足 S[1, j+i-i'] = S[i'-i+1, j],即在 S[1, j] 这段前缀中,S[1, j+i-i'] 这一「前缀的前缀」与 S[i'-i+1, j] 这一「前缀的后缀」相等。
考虑将 j+i-i' 封装成一个只与 S 相关的东西。设 S[1, j] 中最大的满足 S[1, x] = S[j-x+1, j], x < j 的 x = next_j,猜测此时取 i'=j+i-next_j 为最优解。
若存在一个 k 使得 i<k<i' 且合法,则据前文,必然有 S[1, j+i-k] = S[k-i+1, j],这与 next_j 为最大的满足条件的 x 相矛盾,因此,不存在这样的可能 k。
核心思路是 next_j 是最大的 x,换句话说,就是不存在更大的 x。因此只要证任意 i<k<i' 的合法 k 都能推出一个更大 x,即可证明不存在这样一个 k。
对应的 j' 设置为 j+i-i' 即可。
:::info[为什么要求 next_j=x<j?]
这个问题看起来有点蠢,但确实是部分初学者会提出的问题。
如果 x=j,那么我们得到的新 i'=j+i-x=i。由于根本不存在 i<k<i',其必然满足条件。但此时 i 已经失配,所以再尝试从 i 开始匹配没有任何意义。
也可以这样理解:x=j 是一个平凡的解,这个解没有给出任何「信息」,因此不能使用这个解。
:::
若将尝试进行一次往后的字符串匹配的复杂度视为 $O(1)$,则算法总时间复杂度均摊下来是 $O(n+m)$ 的。
可以从 $i$ 和 $j$ 往后跳的位数的角度考虑。$i$ 是只增的,最多往后跳 $n$ 次,$j$ 只在失配的情况下会回退,回退的位数为 $\Delta i=i'-i$,这正好为 $i$ 直接往后跳的位数,可以抵消。只考虑 $j$ 递增的情况,最多往后跳 $m$ 次。将两者加起来,即可得到复杂度为 $O(m+n)$。
上述证明也可以写为势能分析的形式,感兴趣的读者可以自行完成。
### next 数组
求 $next$ 数组可以理解为对于每一个前缀 $S[1, j]$,尝试使用每一个 $S[l, j]$ 进行匹配,并找到其中 $l>1$ 的最小的 $l$。但是我们要求的是整个 $S$ 每一位的 $next$,因此如果直接暴力算的话会爆炸。
然而,由于要求的是对于所有 $next_j$,而 $S[1, j]$ 显然只与 $S[1, x] (1\le x<j)$ 有关,因此可以考虑递推求。或者也可以说用上前面的「信息」。
可以理解为先「假装失配」,然后尝试自己匹配自己。
边界情况为 $next_1=0$。(显然地,$0\le next_j<j$,而满足 $0\le x< 1$ 的整数 $x$ 只有 $0$)
设已求完了 $next_p(1\le p<i)$,现在开始求 $next_i$。
由前可得,$S[1, next_{i-1}] = S[i-1-next_{i-1}+1, i-1]$。设 $j = next_{i-1} + 1$,则有 $S[1, j-1] = S[i-j+1, i-1]$。只要 $S_j=S_i$,即可得 $S[1, j] = S[i-j+1, i]$,令 $next_i\gets j$ 即可。
接下来使用反证法证明正确性:
首先因为是最大所以有 $next_i \ge j$,其次不存在情况 $next_i > j$。若存在 $x>j$ 且 $S[1, x] = S[i-x+1, i]$,则有 $S[1, x-1] = S[i-x+1, i-1](x>j)$,这与前文已求出前面所有的 $next_p(1\le p<i)$ 相矛盾。
那如果 $S_j\ne S_i$ 呢?
又根据 $next$ 的已有性质,有 $S[1,next_{j-1}] = S[j-1 - next_{j-1} + 1, j-1]$。注意到两个相同的字符串的相同位置截取的子串必然相同。所以 $S[j-1 - next_{j-1} + 1, j-1] = S[i-1-next_{j-1}+1, i-1]$。根据等价关系的传递性,有 $S[1,next_{j-1}] = S[i-1-next_{j-1}+1, i-1]$。发现此时取 $j' = next_{j-1}+1$ 就可以将问题转化为更小的子问题。
实现方面,仿照上文形式递归求解即可,注意判断边界条件 $next_1=0$。

时间复杂度方面可以用势能分析的方法证明,大致思路是每一步递推设当前的 $next_i$ 为势能函数,容易发现每个 $i$ 其最多增加一次,最后处理一些细节可以算出来是 $O(m)$,与字符集大小无关。具体可以见上文给出的原始论文。
但注意这一部分的时间复杂度证明是基于均摊的,所以 [KMP 自动机](https://www.luogu.com.cn/problem/CF1721E)必须带上一个字符集大小来保证时间复杂度不在别的地方超标。
:::success[[模板题](https://www.luogu.com.cn/record/269618490)]
```cpp
#include<vector>
#include<iostream>
#include<string>
using namespace std;
vector<size_t> makenext(const string &s)
{
vector<size_t>ret(s.size(), 0);
// next[0] = 0
for(size_t j = 1, k = 0; j < s.size(); j++)
{
while(k && s[j] != s[k])
k = ret[k - 1];
if(s[j] == s[k])
k++;
ret[j] = k;
}
return ret;
} // 求 S[0, j] 的最长前缀后缀相等长度
vector<size_t> KMP(const string &s, const vector<size_t> &nxt, const string &t)
{
vector<size_t> ret;
size_t i = 0, j = 0; // 从一开始开始配
if(!(s.size() && t.size()))
return ret; // 空
while(i < t.size())
{
while(j < s.size() && i + j < t.size() && s[j] == t[i + j])
j++; // 一直到失配或者匹配成功
// cout << i << ' ' << j <<endl;
if(j == s.size())
ret.push_back(i);
// 匹配成功
if(!(i + j < t.size()))
break; // t 被读完
// 此时必然是失配或匹配成功的情况
// S[0, j - 1] 与 T[i, i + j - 1] 已匹配成功
size_t ici = (j ? j + i - nxt[j - 1]: i + 1); // j = 0 根本没匹配成功过
if(ici >= i + j)
{
j = 0;
}
else
{
j = i + j - ici; // 下一个开始尝试匹配的位
}
i = ici;
} // i j 当前正在尝试匹配的位
return ret;
}
int main()
{
string s, t;
cin >> t >> s;
// 代码方面展示 0-index 写法
auto z = makenext(s);
auto z2 = KMP(s, z, t);
for(auto zzz : z2)
{
cout << zzz + 1 << endl;
}
for(auto zzz : z)
{
cout << zzz << " ";
}
cout << endl;
return 0;
}
```
:::
### border
求 $next$ 数组时,只有满足 $S[1, x] = S[i - x + 1, i](x<i)$ 的最大的 $x$ 是被关注的。但其他的更小的 $x$ 又该如何求呢?
如 [CF2209E A Trivial String Problem](https://www.luogu.com.cn/problem/CF2209E) 中就要求求一个子串 $S$ 的每个前缀的最小的满足 $S[1, x] = S[i - x + 1, i]$ 的 $x$。
发现 KMP 中 $next$ 数组维护的东西似乎有很多性质,所以把它单独提出来讲一下。
定义:如果字符串 $K$ 满足 $K = S[1, x] = S[m - x + 1, m](x<m)$,则称 $K$ 为 $S$ 的一个 **border**(直译为边界)。
其实 border 这个名字还是很形象的,一个字符串最前面和最后面是相同的,可不[^kebu]就是这个字符串的「边界」。
- 引理:对于一个字符串 $S$,它的 border 的 border 还是它的 border。
:::info[证明]
这个定理证明主要依靠了两条性质:
1. 字符串等价关系满足传递性,即对于任意字符串 $A=B,B=C$,有 $A=C$。
2. 两个相等的字符串从相同位置截取的子串也相同。即 $A=B$ 时,对于任意合法的 $A[l,r]$ 有 $A[l,r]=B[l,r]$。
设 $S$ 有一个 border $S[1,x]=S[m-x+1,m](x<m)$。定义 $K$ 为 $S[1,x]$ 的一个 border $K = S[1,y]=S[x-y+1,x](y<x)$。此时由于 $S[x-y+1,x]=S[m-y+1,m]$,则有 $K = S[1,y]=S[m-y+1,m](y<m)$,即 $K$ 为 $S$ 的一个 border。

求 $next$ 数组可以看作是逆否命题在特殊情况下的一种应用,因此前图也可以用于辅助理解。
:::
设 $Border(S) = \{{border}_1,{border}_2,{border}_3\dots\}$ 即 $Border$ 为一个由字符串 $S$ 到其所有 border 集合的函数。容易发现,这与返回所有 border 的长度是等价的。(因为对于一个字符串 $S$,其长 $x$ 的 border 即为 $S[1,x]$)
目前到这里其实还是平凡的,仅仅是把 border 这个东西形式化定义了一下。
考虑一些更复杂的东西。
先随便列一个字符串:
`abababbababa`
列出其 border:
`
ababa aba a
`
运用瞪眼法,容易推出对于 $S$ 的一个 border $A$,所有长度小于其的 $S$ 的 border $B$,必然有 $B$ 是 $A$ 的一个 border。
可以看下图辅助理解。
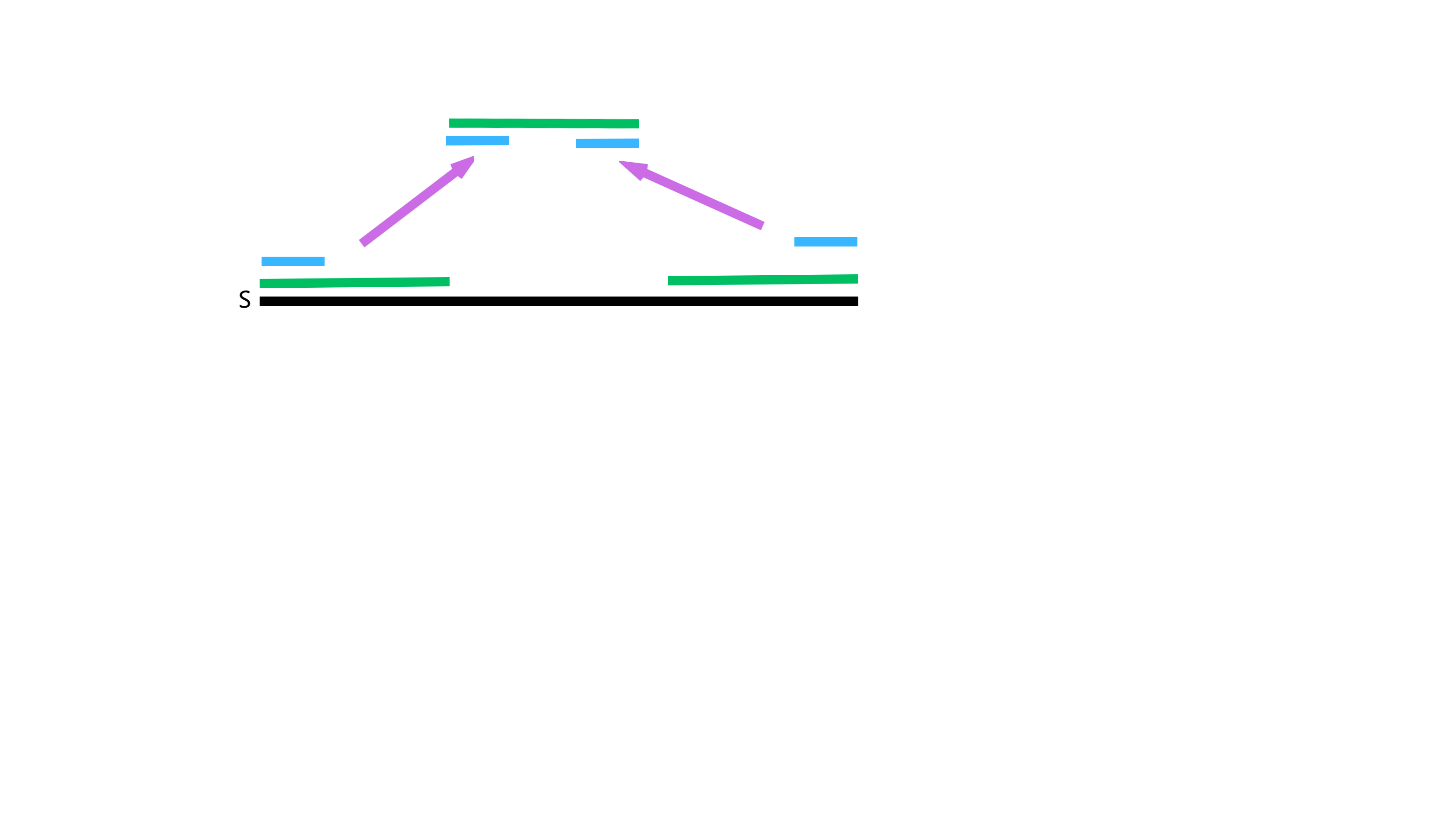
因为 $S$ 所有长度小于 $K$ 的其他 border 都必然是 $K$ 的一个 border,所以对于一个串 $S$ 求其最大 border $K$ 后再递归地求 $K$ 的所有 border 即可求出 $S$ 的所有 border。
但是有些时候还需要对于 $S$ 的一些非 border 的前缀求 border,此时利用 $next$ 数组将其作为 $S'$ 类似地递归求解即可。
容易发现从 $S$ 的任意一个前缀出发,不断转移到它的最长 border,可以建成一个为链的图。如果把这些全部结合起来,没有 border 视为空串,则可以建成一棵以空节点为根的树,因为 $next$ 数组一般是匹配失配时用的,所以这棵树也叫失配树。
:::success[[P5829 【模板】失配树](https://www.luogu.com.cn/record/270237393)]
```cpp
#include<vector>
#include<iostream>
#include<string>
using namespace std;
const int maxn = 1e6;
vector<size_t> makenext(const string & s)
{
vector<size_t>ret(s.size(), 0);
// next[0] = 0
for (size_t j = 1, k = 0; j < s.size(); j++)
{
while (k && s[j] != s[k]) k = ret[k - 1];
if (s[j] == s[k]) k++;
ret[j] = k;
}
return ret;
}
// 求 S[0, j] 的最长前缀后缀相等长度
string s;
int m;
vector<int> son[maxn + 1];
int fa[maxn + 1], top[maxn + 1], siz[maxn + 1], dep[maxn + 1], hson[maxn + 1];
void dfs1(int u)
{
siz[u] = 1;
hson[u] = 0;
for (int v : son[u])
{
if (v == fa[u]) continue;
dep[v] = dep[fa[v] = u] + 1;
dfs1(v);
siz[u] += siz[v];
if (!hson[u] || siz[hson[u]] < siz[v]) hson[u] = v;
}
}
void dfs2(int u)
{
if (hson[u])
{
top[hson[u]] = top[u];
dfs2(hson[u]);
}
// 重儿子先
for (int v : son[u])
{
if (v == fa[u]) continue;
if (v == hson[u]) continue;
top[v] = v;
dfs2(v);
}
}
int lca(int x, int y)
{
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]]) swap(x, y);
x = fa[top[x]];
}
if (dep[x] < dep[y]) swap(x, y);
return y;
// y 深度小一点
}
int main()
{
cin.tie(nullptr)->sync_with_stdio(false);
cin >> s >> m;
auto nxt = makenext(s);
for (size_t i = 0; i < nxt.size(); i++)
{
son[nxt[i]].push_back(i + 1);
}
dep[0] = 0;
fa[0] = 0;
top[0] = 0;
dfs1(0);
dfs2(0);
for (int i = 1, p, q; i <= m; i++)
{
cin >> p >> q;
int lca_pq = lca(p, q);
if (lca_pq == p || lca_pq == q) lca_pq = fa[lca_pq];
cout << lca_pq << endl;
}
return 0;
}
```
:::
非模板题:《[微不足道小问题笑传之查串 b](https://www.luogu.com.cn/article/ruel2pvk)》
## 课后作业
好了,你现在已经学会 KMP 了。
现在,挑战做出 [P15650 \[省选联考 2026\] 摩卡串 / string](https://www.luogu.com.cn/problem/P15650) 吧!
## 最后的一点悄悄话(?)
笔者是个蒟蒻,目前还不敢说自己能做出绝大部分串串题。究其原因,还是之前对字符串的理解太浅了,对「简单」的基础算法抱有一种「傲慢」。这种「傲慢」类似却又不同于「CleanIce 式的傲慢」,其并非现实生产环境中的人对于一般进行算法理论研究 OIer 的傲慢,而是自认为已学会许多高级算法的 OIer 对于「基础」算法的傲慢。由于笔者还没有找到之前有人提出过,就仿照学术界的惯例,将其称之为「clx201022 式的傲慢」吧。~~如果已经有其他人提出过了不要打我。~~
- 笑点解析:笔者写作此段时数次将「傲慢」错写为「阿毛」。
## 友链
- [字符串哈希学习笔记](https://www.luogu.com.cn/article/7t2i33ch)
- [字符串・学习笔记・算法详解 1](https://www.luogu.com.cn/article/zxhe6rla)
- 《[Border理论小记](https://www.luogu.com.cn/article/ds5cz0sg)》,@[command_block](luogu://user/58705)
- 画图使用了[在线速写板](https://www.suxieban.com)。
::anti-ai[本文作者是 clx201022,洛谷 UID 为 552688,原文:<https://www.luogu.com.cn/article/xf5o27fm> 如果您能直接看到这段文字而在本页没有转载提示,或以「原创」名义发出,说明您访问的是侵权内容,请联系管理员删除文章并处罚侵权人,十分感谢您的见义勇为之举。]
## 创作声明
本文遵循 [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/deed.zh-hans) 协议。
保证本文未使用 AI 工具辅助创作。
[^chuanchuan]: 即字符串。
[^pian]: [更多关于偏序和全序关系的内容](https://ri-nai-bit-se.github.io/Discrete-Math-Notes/%E9%9B%86%E5%90%88%E8%AE%BA/%E4%BA%8C%E5%85%83%E5%85%B3%E7%B3%BB/%E5%81%8F%E5%BA%8F%E5%85%B3%E7%B3%BB/)。
[^fang]: 其中 $s[l, r]$ 是平凡的,代表 $s_l s_{l+1}\dots s_{r-1}s_r$。
[^chong]: 首先受到攻击,或首先遭遇灾难。
[^yi]: 造诣(yi)学业、专门技术等达到的水平、境地;前往拜访。
[^kebu]: 不是这个[可不](https://mzh.moegirl.org.cn/%E5%8F%AF%E4%B8%8D)。